提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、ChatGLM3-6B部署
- 搭建环境
- 部署GLM3
- 二、Chatglm2-6b+langchain部署
- 三、Tips
- 四、总结
前言
提示:这里可以添加本文要记录的大概内容:
看了几天chatglm和langchain的部署,经过不断报错,终于试出了可以运行的方案,不过本地知识库搭建还有问题,要再看看。本文主要介绍ChatGLM3-6B的部署和实现效果,和Chatglm2-6b+langchain结合的实现效果。
提示:以下是本篇文章正文内容,下面案例可供参考
一、ChatGLM3-6B部署
搭建环境
用阿里云免费资源进行创建实例,详情可参考
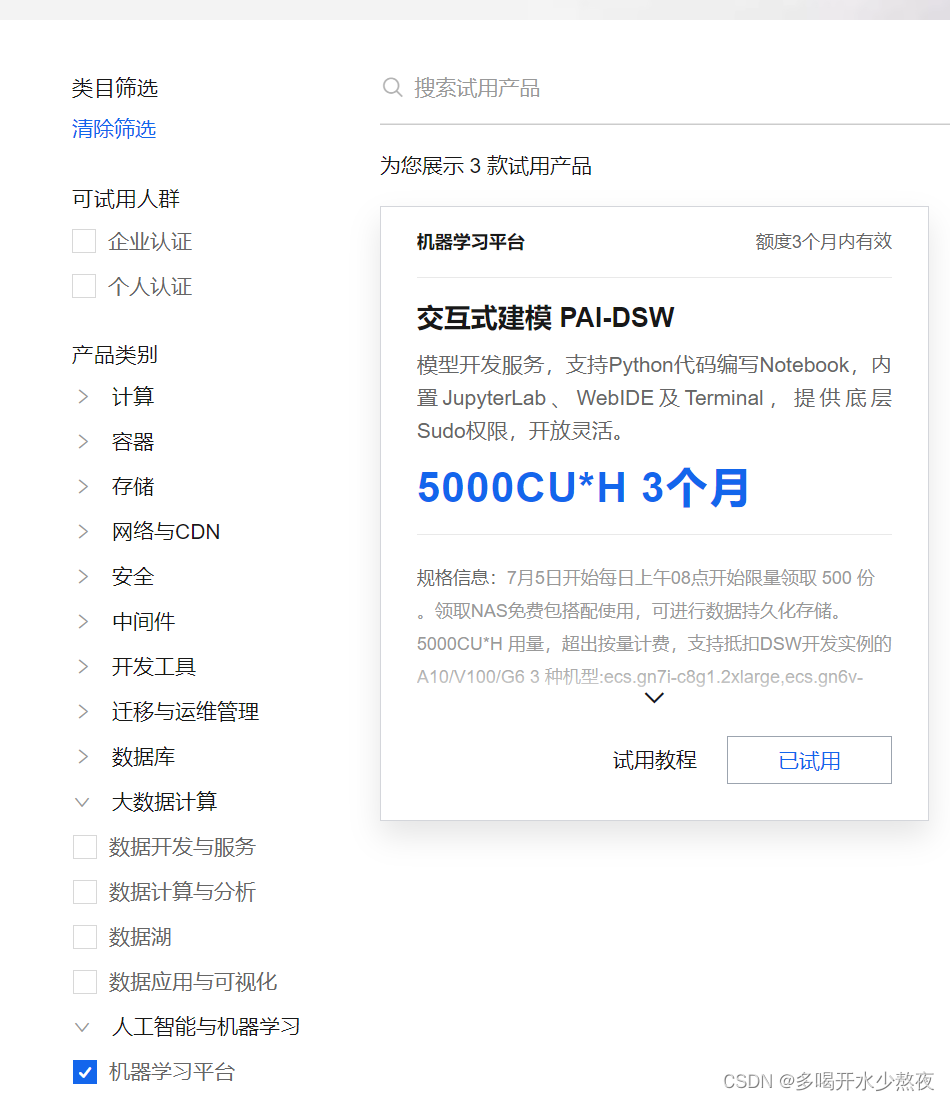 点击试用,OSS那里要勾上,看别人都勾了,不过我没勾,不知道会不会有什么问题,然后授权就行了。
点击试用,OSS那里要勾上,看别人都勾了,不过我没勾,不知道会不会有什么问题,然后授权就行了。
创建完后进入控制台,点击【交互式建模DSW】,进行创建实例,只能选择可抵扣计算时的V100或者A10,只有这两个规格的GPU是免费试用的(页面没有的话,可以过段时间再进去可能就有了,不过用哪个都行不过A10没那么耗资源)。
因为我们的是资源包,所以可以创建n个实例,我创建了一个V100的实例,配置如下:
官方镜像:pytorch2.0.1tensorflow2.13.0-cpu-py38-ubunt(最新的)
部署GLM3
1、点击创建的实例,进入terminal,输入:
apt-get update
apt-get install git-lfs
git init
git lfs install
2、首先git clone下载GLM3仓库,并切换到这个文件夹下
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
3、然后使用 pip 安装依赖:
最新版本中,建议在WEBIDE双击打开requirements.txt,然后把其中的“gradio~=3.39”修改成“gradio==3.39”
4、加好保存后,运行下面脚本:
pip install -r requirements.txt
5、git 下载本地模型
从modelscope上git下载模型,一个速度快,而且也不会因为网络问题下载不下来
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
6、修改变量路径并启用
有2个文件需要修改变量路径,一个是basic_demo下的“web_demo.py”,另一个是chatgm3-6b下的“config.json”,都是把默认的“THUDM/”修改为“/mnt/workspace/ChatGLM3/”(就是修改为chatglm3-6b所在的本地目录)
这里的修改,可以使用vim,也可以在WEBIDE中直接左边栏双击打开文件修改(推荐)
7、运行下列代码启动web_demo.py
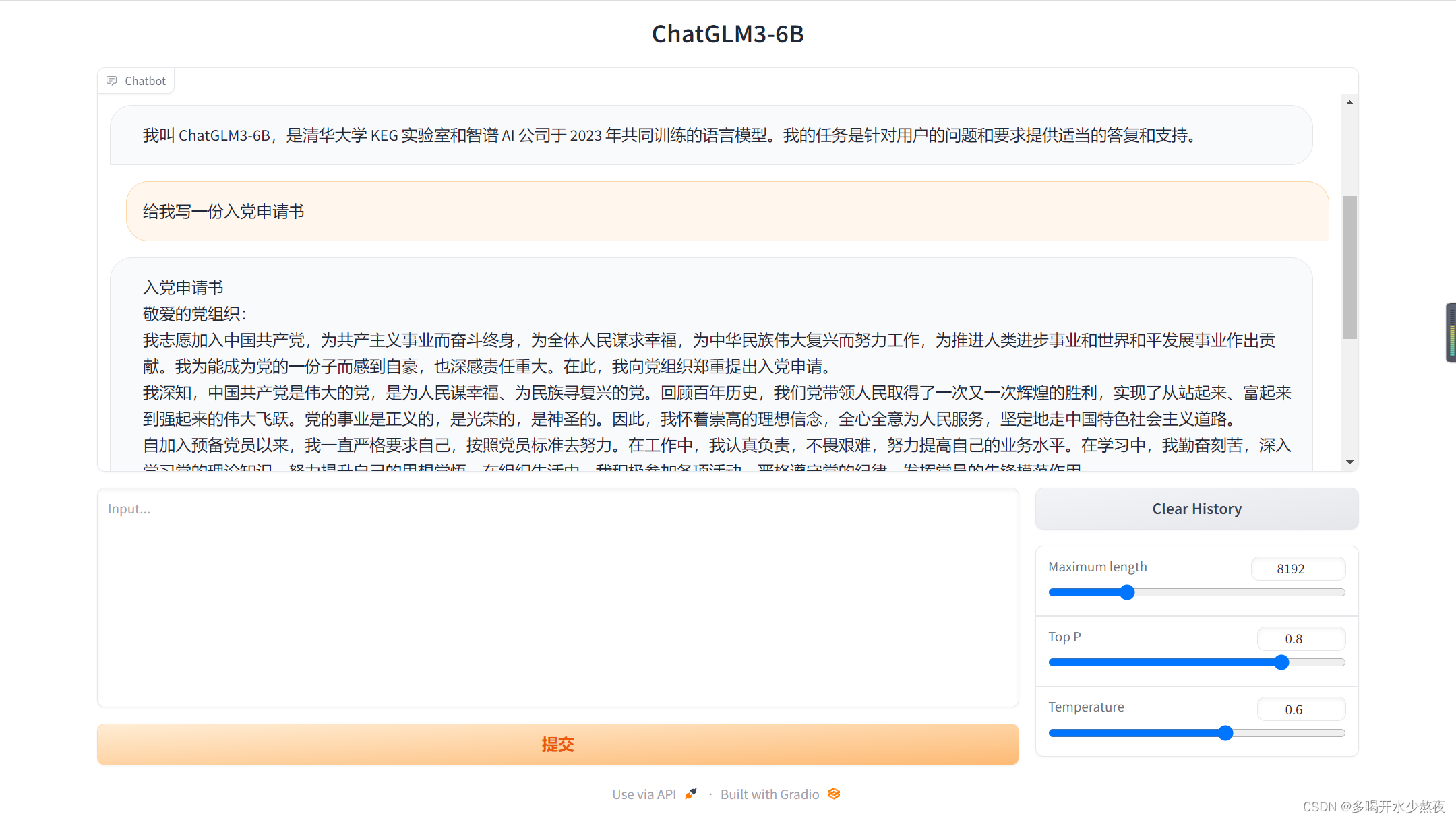
python /mnt/workspace/ChatGLM3/basic_demo/web_demo.py
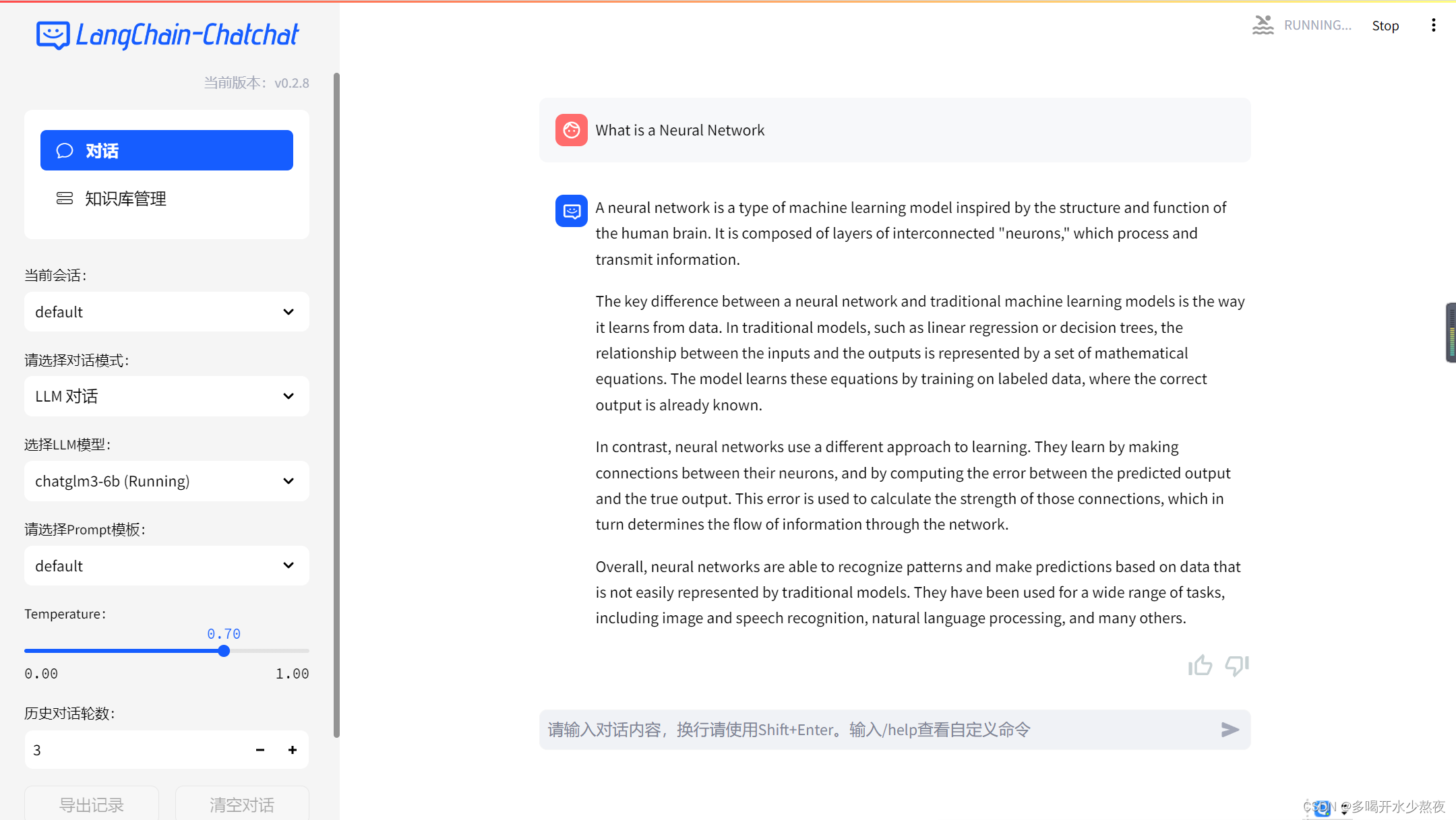
点击第二个url跳转后就可以进行对话了。如下图所示
二、Chatglm2-6b+langchain部署
借鉴网页1
借鉴网页2
先创建实例:A10,镜像在官方镜像里面选pytorch-develop:1.12-cpu-py39-ubuntu20.04
之前用镜像url输入地区url和选了官方镜像里面的*modelscope:*相关的镜像都因为版本之类的原因报错了。
更新一下:
apt-get update
apt-get install git-lfs
git init
git lfs install
接着下载好相关的模型和源码:
目录结构参考:
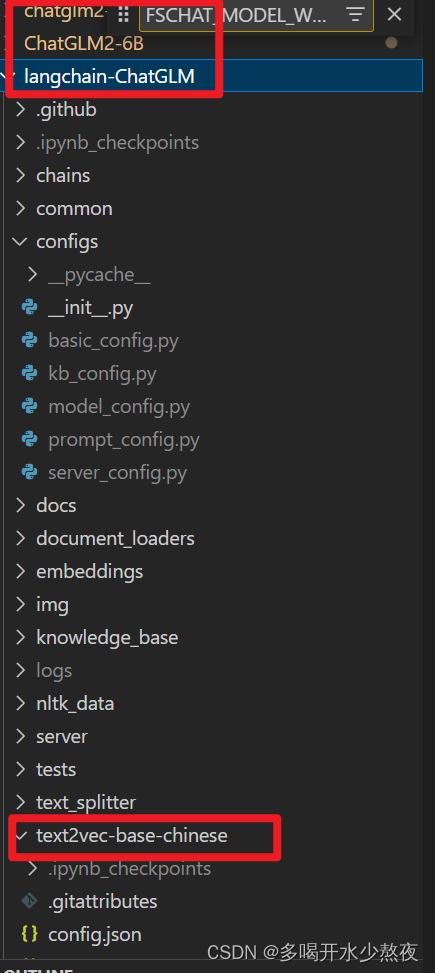
在/mnt/workspace目录下安装
git clone https://github.com/THUDM/ChatGLM2-6B.git
git clone https://www.modelscope.cn/ZhipuAI/chatglm2-6b.git
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
cd langchain-ChatGLM
git clone https://www.modelscope.cn/thomas/text2vec-base-chinese.git
该网站有许多模型可以下载,因为现在好像没办法在huggle.co下载模型了,国内推荐在modelscope里面下载。
分别在/ChatGLM2-6B 和/langchain-ChatGLM目录下执行pip install –r requirements.txt
安装依赖。
修改模型对应路径:
1.chatglm2-6b:
chatglm2-6b模型在目录的config.json文件中修改"_name_or_path"

2.ChatGLM2-6B:
在web_demo.py和web_demo2.py中都把tokenizer和model的路径修改为本地chatlm2-6b的路径

3.langchain-ChatGLM:
- 修改configs目录下的文件后面的
.example都去掉

- 修改
model_config.py
# 01.仅指定 chatglm2-6b
LLM_MODELS = ["chatglm2-6b", ]# 02.指定为 空
ONLINE_LLM_MODEL = { }# 03.仅指定 text2vec-base-chinese chatglm2-6b
MODEL_PATH = {
"embed_model": {# 仅指定 这一个"text2vec-base-chinese": "/mnt/workspace/langchain-ChatGLM/text2vec-base-chinese",},"llm_model": {# 仅指定 这一个"chatglm2-6b": "/mnt/workspace/chatglm2-6b",},
}# 04.仅指定 chatglm2
SUPPORT_AGENT_MODEL = ["chatglm2",
]
- 修改
server_config.py
FSCHAT_MODEL_WORKERS = {# 所有模型共用的默认配置,可在模型专项配置中进行覆盖。"default": {"host": DEFAULT_BIND_HOST,"port": 20002,"device": LLM_DEVICE,"infer_turbo": False,}
}
创建知识库
python init_database.py --recreate-vs
执行私有库模型
python startup.py -a
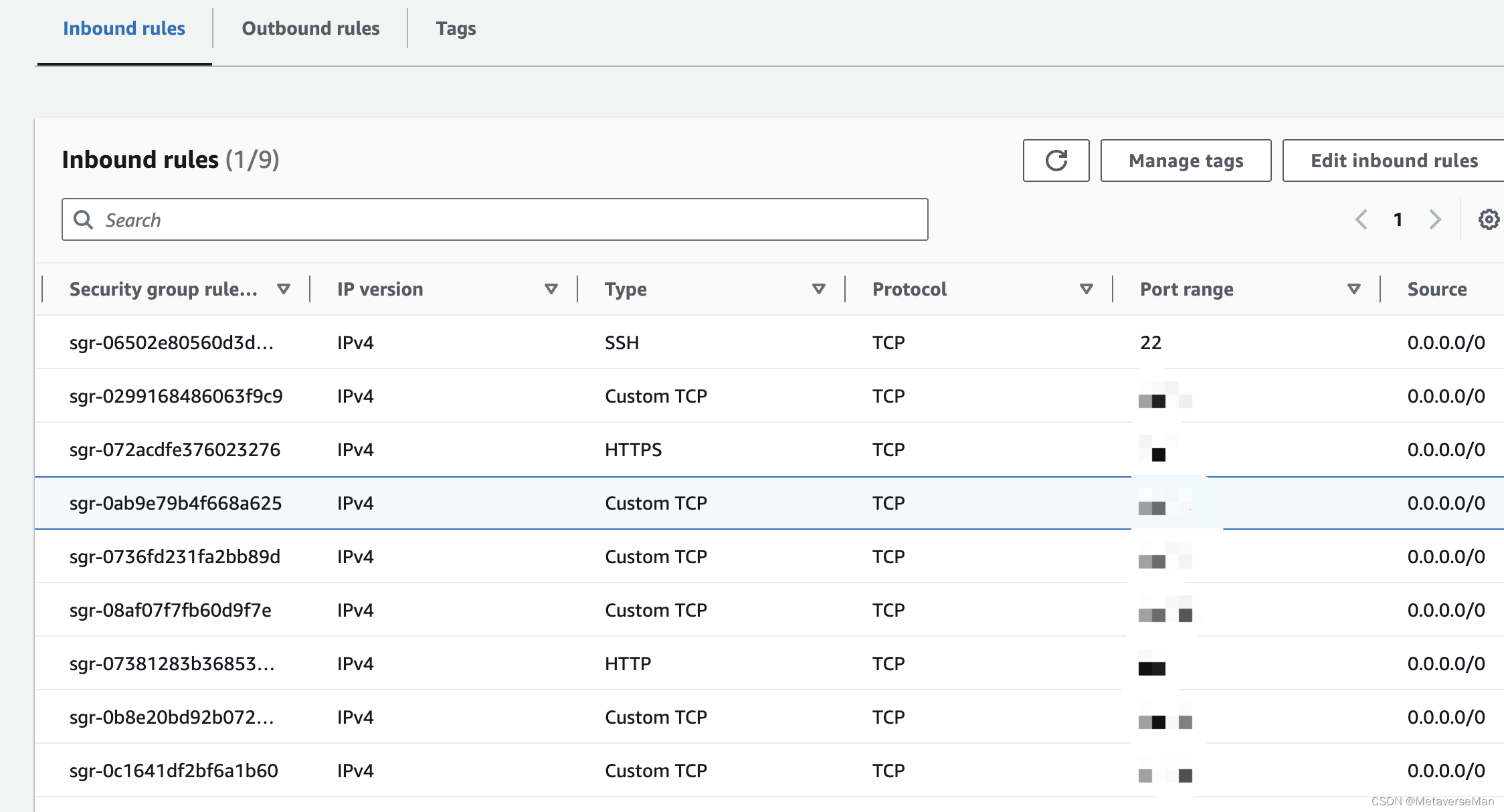
点击执行后的网址就出来了:
使用的时候内存消耗比较大

三、Tips
1、该网站有许多模型可以下载,因为现在好像没办法在huggle.co下载模型了,国内推荐在modelscope里面下载。
2、当我们国内的网打不开一些模型网站时,可以先用魔法,download下来到本地,然后上传到gitee再git clone借鉴网站
3、pip install的时候建议后面加清华源,一个是速度快,还有一个是能避免一些错误(虽然不知道为什么)
pip install 安装包名字 -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn //清华大学
pip install 安装包名字 -i http://[pypi](https://so.csdn.net/so/search?q=pypi&spm=1001.2101.3001.7020).doubanio.com/simple/ --trusted-host pypi.doubanio.com //豆瓣镜像网站
四、总结
不管怎么样首先还是要自己去多实践,实践出真知,我也创建了好几个实例,用了不同环境,修改方法才慢慢摸索出来,而且试多了也大概知道一些错误怎么修改还有修改原因之类的,所以越到后面越熟练了,我做这个部署也有几天了,每天看不同的网页,阿里云、本地都有尝试(本地可能是电脑太垃了搞不起来,毕竟莫得独显),成功的时候还是比较欣慰的,所以大家一定要坚持,很多东西尤其是没试过的东西很难一蹴而就,往往需要我们不断尝试累积经验。
之后去再看看本地知识库搭建,然后了解transformer相关内容。







![[MySQL--进阶篇]存储引擎的体系结构、简介、特点、选择](https://img-blog.csdnimg.cn/direct/50cc2961e2644b7da434db26b72dfdef.gif#pic_center)