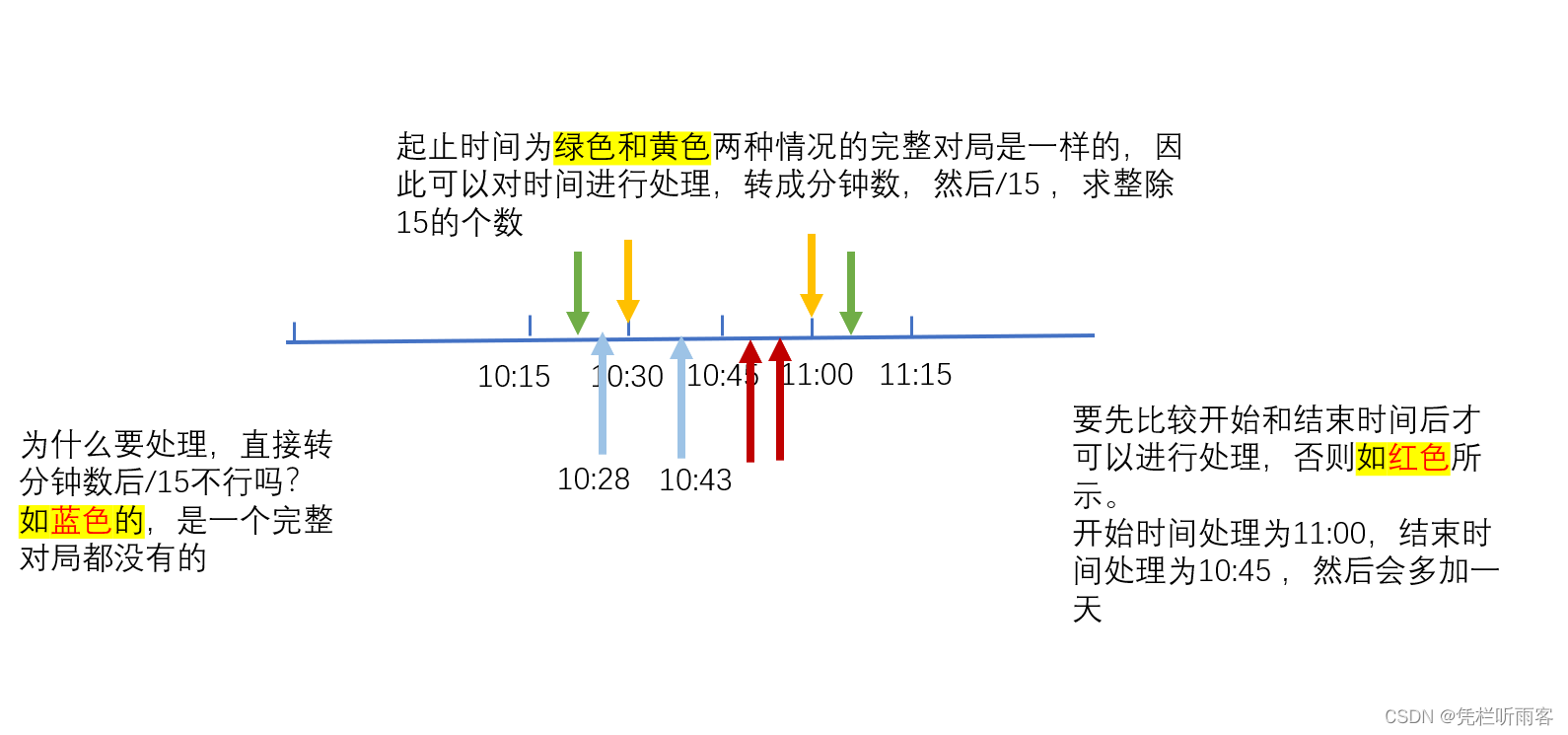
一、说明
在数字时代,数据已成为企业、组织和个人的基本资源。然而,在浩瀚的数据海洋中,困扰数据分析的一个常见问题是存在空值或缺失数据。数据无效是指某些数据字段中缺少信息,这在根据该数据进行分析和决策时可能会导致重大问题。在本文中,我们将探讨数据无效的概念、其原因、相关问题以及缓解这些问题的潜在解决方案。

数据的无效性就像知识领域的影子,使我们的见解受到怀疑。然而,通过勤奋的分析,我们可以照亮解决方案的道路,将缺失的部分转化为有价值的线索。
二、了解数据中的无效性
数据无效可归因于各种原因,从数据输入过程中的人为错误到系统故障和不完整的调查。Null 值通常表示为“N/A”、“NaN”、“NULL”,或者在数据集中简单地留空。在某些情况下,数据可能完全丢失,而在其他情况下,数据可能部分缺失。识别和解决无效性至关重要,因为它会显着影响数据驱动决策过程的准确性和可靠性。
三、与数据无效相关的问题
- 偏倚分析:空值可能会在数据分析中引入偏差,尤其是当缺失数据不是随机的,而是遵循特定模式时。这可能导致结果偏差和结论不准确。
- 信息不完整:无效性会破坏数据集的完整性,从而难以得出有意义的见解。关键变量中的缺失值会导致信息不完整,从而影响分析和预测的质量。
- 数据质量:Null 值可能会在数据质量方面产生问题,从而影响数据集的整体完整性。数据质量差会导致结果不可靠,并削弱对所用数据的信任。
- 误解:缺少数据可能会导致对信息的误解。分析师可能会试图填补空白或做出假设,这可能会导致错误的结论。
- 信息丢失:在某些情况下,缺失的数据可能携带有价值的信息或上下文。这些信息的丢失可能会阻碍对数据集的全面理解。
- 资源利用效率低下:使用 null 值需要额外的精力和资源来清理和插补数据,从而导致数据分析过程效率低下。
四、无效问题的解决方案
解决数据中的无效性对于提高数据分析的准确性和可靠性至关重要。可以采用几种策略来处理此问题:
- 数据插补: 数据插补涉及用估计值填充缺失值,例如可用数据的平均值、中位数或众数。插补方法可以是基于统计或机器学习的,具体取决于数据集的性质。
- 数据收集改进:确保稳健的数据收集流程和质量控制措施可以最大限度地减少空值的发生。精心设计的调查、标准化的数据输入程序和定期的数据验证检查至关重要。
- 数据删除:当空值是零星的或在分析中没有显著的权重时,只需删除缺少数据的行或列即可成为有效的选择。但是,应谨慎执行此操作以避免数据丢失。
- 使用高级技术:考虑到与缺失数据相关的不确定性,多重插补和概率数据建模等高级技术可以提供更准确的插补。
- 透明度和文档:必须记录在数据分析过程中如何处理空值,以保持透明度并深入了解缺失数据对结果的潜在影响。
五、原因
由于各种原因,可能会发生数据无效或存在缺失值。了解数据丢失的原因对于解决和缓解与之相关的问题至关重要。数据无效的一些常见原因包括:
- 数据输入错误:数据输入过程中的人为错误可能导致值缺失或不正确。这可能包括记录数据时的拼写错误、遗漏或误解。
- 系统故障:数据收集或存储过程中的技术问题或系统故障可能会导致数据丢失。例如,数据传输过程中的断电或软件崩溃可能会导致数据丢失。
- 无响应:在调查或问卷中,受访者可能会选择不回答特定问题,从而导致缺失值。不响应可能是故意的,也可能是由于调查疲劳。
- 数据转换:数据转换过程(例如数据清理或重塑)可能会无意中引入缺失值。例如,如果所有记录都没有相应的值,则合并数据集可能会导致数据丢失。
- 隐私和保密:在某些情况下,可能会故意删除数据以保护个人或实体的隐私和机密性。敏感信息可能会被编辑或从公共数据集中排除。
- 取样技术:在使用抽样技术的调查和研究中,并非所有选定的个人或单位都可以提供数据,从而导致数据缺失。这在随机抽样中很常见。
- 测量限制:由于测量仪器或传感器的限制,某些数据可能会丢失。例如,在某些情况下,传感器可能无法捕获数据。
- 时间相关因素:由于测量方法或仪器的变化,或者由于某些时间段内数据不可用,随着时间的推移收集的数据可能会出现缺失值。
- 数据聚合:在汇总数据时,例如根据每日数据计算月平均值,如果原始每日数据存在差距,则可能会出现数据丢失的情况。
- 未记录的事件:在某些情况下,由于疏忽、缺乏资源或缺乏这些事件的数据收集机制,事件或观察结果可能未被记录下来。
- 自然现象:某些自然现象,如自然灾害或极端天气条件,可能会扰乱数据收集过程并导致缺失值。
- 非结构化数据: 在非结构化数据源(如文本文档或社交媒体帖子)中,数据提取和转换过程可能并不总是捕获相关信息,从而导致结构化数据集中的值缺失。
了解这些数据无效的原因对于数据分析师和研究人员至关重要。解决这些问题通常涉及数据清理、插补和质量控制措施,以提高数据集的准确性和完整性,确保缺失值不会对从数据中得出的结果和结论产生不利影响。
六、代码
下面是一个完整的 Python 代码示例,演示了数据中的无效性、其问题以及如何使用数据集和绘图处理它们。在此示例中,我们将使用 seaborn 库中的“泰坦尼克号”数据集。
您需要安装 Python 并安装所需的库(pandas、numpy、seaborn 和 matplotlib)才能运行此代码。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt# Load the Titanic dataset
titanic_data = sns.load_dataset("titanic")# Introduction to Nullity in Data
print("Introduction to Nullity in Data:")
print(titanic_data.head(10)) # Display the first 10 rows of the dataset# Check for missing values
missing_data = titanic_data.isnull()# Plot missing data
plt.figure(figsize=(10, 6))
sns.heatmap(missing_data, cbar=False, cmap="viridis")
plt.title("Missing Data in the Titanic Dataset")
plt.show()# Problems Associated with Nullity in Data
print("\nProblems Associated with Nullity in Data:")
print("1. Biased Analyses:")
# Let's calculate the survival rate for passengers with and without missing age values
titanic_data['AgeMissing'] = titanic_data['age'].isnull()
survival_rate_with_missing_age = titanic_data[titanic_data['AgeMissing'] == True]['survived'].mean()
survival_rate_without_missing_age = titanic_data[titanic_data['AgeMissing'] == False]['survived'].mean()
print(f"Survival rate with missing age values: {survival_rate_with_missing_age:.2f}")
print(f"Survival rate without missing age values: {survival_rate_without_missing_age:.2f}")print("\n2. Incomplete Information:")
# Count the number of rows with missing data
incomplete_rows = titanic_data.isnull().any(axis=1).sum()
print(f"Number of rows with missing data: {incomplete_rows}")print("3. Data Quality:")
# Count the number of missing values in the 'age' column
missing_age_count = titanic_data['age'].isnull().sum()
print(f"Number of missing age values: {missing_age_count}")# Solutions to Nullity Problems
print("\nSolutions to Nullity Problems:")
# Data Imputation: Fill missing age values with the median age
titanic_data['age'].fillna(titanic_data['age'].median(), inplace=True)# Data Deletion: Remove rows with missing 'embarked' values
titanic_data.dropna(subset=['embarked'], inplace=True)# Check missing data after handling
missing_data_after_handling = titanic_data.isnull()
print(missing_data_after_handling.sum())# Plot missing data after handling
plt.figure(figsize=(10, 6))
sns.heatmap(missing_data_after_handling, cbar=False, cmap="viridis")
plt.title("Missing Data in the Titanic Dataset After Handling")
plt.show()此代码首先加载泰坦尼克号数据集,检查其无效性,并讨论与缺失数据相关的问题。然后,它演示了两种解决方案:“age”列的数据插补和“enbarked”列的数据删除。最后,它使用热图图可视化处理前后数据集的缺失数据。
Introduction to Nullity in Data:survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
5 0 3 male NaN 0 0 8.4583 Q Third
6 0 1 male 54.0 0 0 51.8625 S First
7 0 3 male 2.0 3 1 21.0750 S Third
8 1 3 female 27.0 0 2 11.1333 S Third
9 1 2 female 14.0 1 0 30.0708 C Second who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
5 man True NaN Queenstown no True
6 man True E Southampton no True
7 child False NaN Southampton no False
8 woman False NaN Southampton yes False
9 child False NaN Cherbourg yes False 以下是对从提供的 Python 代码中获得的结果的解释:
数据中的无效性简介:
- 代码首先加载泰坦尼克号数据集并显示前 10 行。本简介可帮助您熟悉数据集的结构及其包含的数据类型。
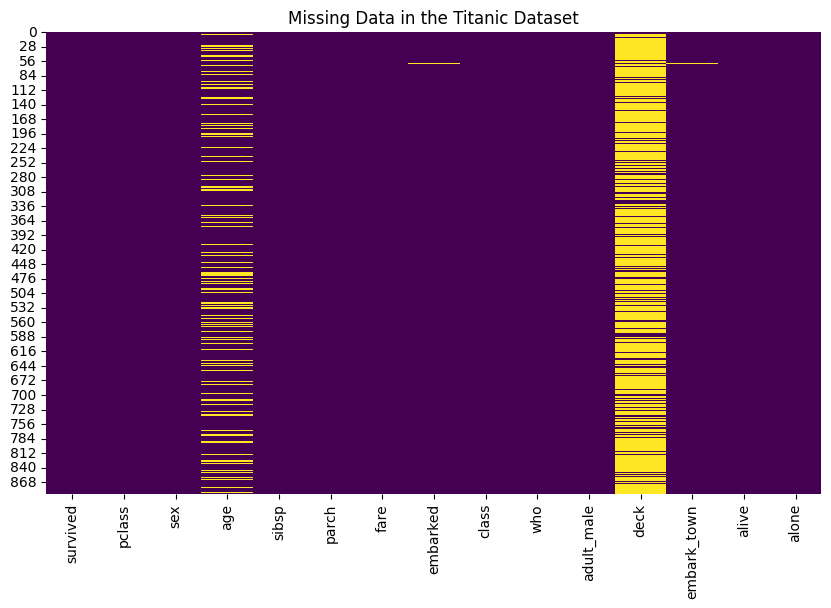
与数据无效相关的问题:
- 偏倚分析:该代码计算有和没有缺失年龄值的乘客的存活率。这证明了缺失数据带来的潜在偏差。在这种情况下,与有年龄信息的乘客相比,缺少年龄值的乘客的存活率较低,这表明生存率分析可能存在偏差。
- 信息不完整:代码统计缺少数据的行数。在此数据集中,有几行的信息不完整,因此在不处理缺失数据的情况下执行有意义的分析具有挑战性。
- 数据质量:代码统计缺失年龄值的数量,突出显示数据质量问题。基本列(如“age”)中的缺失值会影响分析的可靠性。
Problems Associated with Nullity in Data:
1. Biased Analyses:
Survival rate with missing age values: 0.29
Survival rate without missing age values: 0.412. Incomplete Information:
Number of rows with missing data: 709
3. Data Quality:
Number of missing age values: 177Solutions to Nullity Problems:
survived 0
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
class 0
who 0
adult_male 0
deck 688
embark_town 0
alive 0
alone 0
AgeMissing 0
dtype: int64无效问题的解决方案:
- 该代码提供了两种处理缺失数据的解决方案:
- 数据插补:缺失的年龄值由乘客的年龄中位数填充。这是插补缺失数值数据的常用方法,可确保数据集更完整,便于分析。
- 数据删除:将从数据集中删除缺少“已开始”值的行。此方法可消除信息不完整的行,从而确保数据集的一致性。
处理后丢失数据:
- 应用解决方案后,代码将再次检查数据集中是否缺少数据。在“age”列中,缺失值已与中位年龄一起插补,而在“enbarked”列中,缺失值的行已被删除。
可视化:
- 该代码使用热图图提供缺失数据的可视化效果。第一个热图显示原始数据集中的缺失数据,第二个热图显示处理缺失数据后的数据集。可视化可帮助您评估数据处理技术对数据集完整性的影响。

总之,该代码表明,缺失数据会导致分析有偏差、信息不完整和数据质量问题。然后,它提供数据插补和数据删除等解决方案来解决这些问题,并在处理后可视化缺失数据模式的变化。处理缺失数据对于确保数据分析和决策的准确性和可靠性至关重要。
七、结论
数据中的无效性是数据分析领域中普遍存在的问题。它会破坏分析的可靠性,引入偏见,并导致错误的决策。解决无效性问题需要结合数据插补、数据收集改进和深思熟虑地应用先进技术。此外,透明度和文档对于保持数据分析过程的完整性至关重要。通过了解数据无效的原因和后果,并实施有效的策略来缓解这些问题,组织和个人可以确保更准确、更可靠的数据驱动的见解和决策。






![[论文阅读]BEVFusion](https://img-blog.csdnimg.cn/direct/7da3ac93c5bc416f98f79c93e0158589.png)