《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
《------正文------》
基本功能演示

摘要:
吸烟行为检测对于维护公共场所的健康环境、防止火灾事故的发生以及促进健康生活方式都具有重要作用。使用基于YOLOv8的吸烟行为检测系统能够有效识别视频中的吸烟行为,从而及时采取适当措施。本文基于YOLOv8深度学习框架,通过2357张图片,训练了一个进行吸烟行为的目标检测模型,准确率高达96%。并基于此模型开发了一款带UI界面的吸烟行为检测系统,可用于实时检测场景中的吸烟行为,更方便进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
- 基本功能演示
- 前言
- 一、软件核心功能介绍及效果演示
- 软件主要功能
- (1)图片检测演示
- (2)视频检测演示
- (3)摄像头检测演示
- (4)保存图片与视频检测结果
- 二、模型的训练、评估与推理
- 1.YOLOv8的基本原理
- 2. 数据集准备与训练
- 3. 训练结果评估
- 4. 检测结果识别
- 【获取方式】
- 结束语
点击跳转至文末《完整相关文件及源码》获取
前言
吸烟行为检测系统是一种重要的实时监控工具,它对于维护公共场所的健康环境、防止火灾事故的发生以及促进健康生活方式都具有重要作用。使用基于YOLOv8的吸烟行为检测系统能够有效识别视频中的吸烟行为,从而及时采取适当措施。
在众多应用场景中,吸烟行为检测尤为关键。例如,在
不允许吸烟的公共区域,如医院、学校、购物中心、机场和餐馆等,此系统能够确保这些区域的空气质量,防止受到二手烟的影响。在商业大厦与工作场所,监测吸烟行为有助于遵守法律法规,并可能与健康保险政策挂钩,降低因吸烟相关疾病带来的成本。
此外,该系统在防火安全管理上同样至关重要。吸烟是引起火灾的主要原因之一,特别是在加油站、化工厂或爆炸性物质储存区等高风险地区的安全监控中,吸烟行为的早期检测可以有效预防火灾和其他安全事故的发生。在住宅区和酒店,吸烟检测系统同样有助于确保室内环境符合住宅政策,并保障居民与客人的健康。
综上所述,吸烟行为检测系统的推广和应用能够帮助管理者迅速响应吸烟事件,制定并执行吸烟禁令,同时为全社会创造一个更加健康、安全的环境。
博主通过搜集吸烟行为的相关数据图片,根据YOLOv8的目标检测技术,基于python与Pyqt5开发了一款界面简洁的吸烟行为检测系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。
软件初始界面如下图所示:

检测结果界面如下:

一、软件核心功能介绍及效果演示
软件主要功能
1. 可实时进行吸烟行为状态的目标检测;
2. 支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
3. 界面可实时显示目标位置、目标总数、置信度、用时等信息;
4. 支持图片或者视频的检测结果保存;
(1)图片检测演示
点击图片图标,选择需要检测的图片,或者点击文件夹图标,选择需要批量检测图片所在的文件夹,操作演示如下:
点击目标下拉框后,可以选定指定目标的结果信息进行显示。 点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
注:1.右侧目标位置默认显示置信度最大一个目标位置。所有检测结果均在左下方表格中显示。
单个图片检测操作如下:

批量图片检测操作如下:

(2)视频检测演示
点击视频图标,打开选择需要检测的视频,就会自动显示检测结果。点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。

(3)摄像头检测演示
点击摄像头图标,可以打开摄像头,可以实时进行检测,再次点击摄像头图标,可关闭摄像头。

(4)保存图片与视频检测结果
点击保存按钮后,会将当前选择的图片【含批量图片】或者视频的检测结果进行保存。检测的图片与视频结果会存储在save_data目录下。


二、模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一种前沿的目标检测技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
其主要网络结构如下:

2. 数据集准备与训练
通过网络上搜集关于吸烟行为的各类图片,并使用LabelMe标注工具对每张图片中的目标边框(Bounding Box)及类别进行标注。一共包含2357张图片,其中训练集包含1885张图片,验证集包含472张图片,部分图像及标注如下图所示。


图片数据的存放格式如下,在项目目录中新建datasets目录,同时将跌倒检测的图片分为训练集与验证集放入SmokeData目录下。

同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: E:\MyCVProgram\SmokeDetection\datasets\SmokeData\train
val: E:\MyCVProgram\SmokeDetection\datasets\SmokeData\valnc: 1
names: ['Smoke']
注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
# 加载模型
model = YOLO("yolov8n.pt") # 加载预训练模型
# Use the model
if __name__ == '__main__':# Use the modelresults = model.train(data='datasets/SmokeData/data.yaml', epochs=250, batch=4) # 训练模型# 将模型转为onnx格式# success = model.export(format='onnx')
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
本文训练结果如下:

我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP,可以看到本文模型目标检测的mAP@0.5已经达到了0.958,结果还是十分不错的。

4. 检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/trian/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/smoke_b000918.jpg"# 加载预训练模型
# conf 0.25 object confidence threshold for detection
# iou 0.7 intersection over union (IoU) threshold for NMS
model = YOLO(path, task='detect')
# model = YOLO(path, task='detect',conf=0.5)# 检测图片
results = model(img_path)
res = results[0].plot()
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

以上便是关于此款吸烟行为检测系统的原理与代码介绍。基于此模型,博主用python与Pyqt5开发了一个带界面的软件系统,即文中第二部分的演示内容,能够很好的支持图片、视频及摄像头进行检测,同时支持检测结果的保存。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
关注下方名片G-Z-H:【阿旭算法与机器学习】,回复【软件】即可获取下载方式
本文涉及到的完整全部程序文件:包括python源码、数据集、训练代码、UI文件、测试图片视频等(见下图),获取方式见文末:
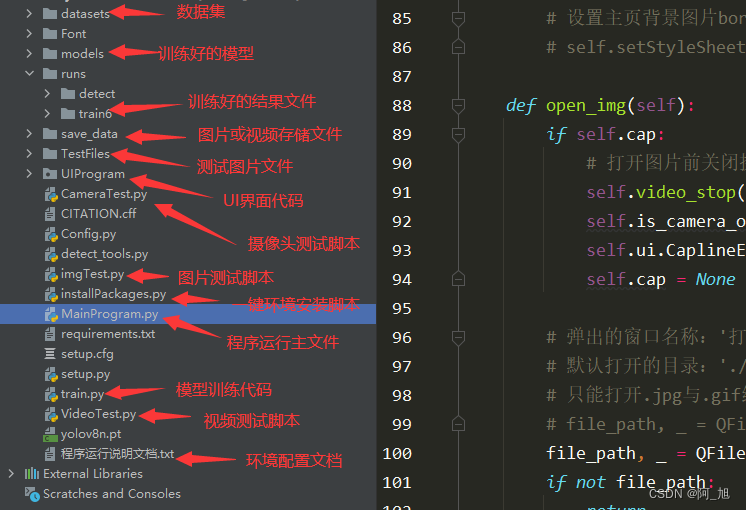
注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
关注下方名片GZH:【阿旭算法与机器学习】,回复【软件】即可获取下载方式
结束语
以上便是博主开发的基于YOLOv8深度学习的吸烟行为检测系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正。
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!




![[论文阅读]BEVFusion](https://img-blog.csdnimg.cn/direct/7da3ac93c5bc416f98f79c93e0158589.png)



![[GPT]Andrej Karpathy微软Build大会GPT演讲(下)--该如何使用GPT助手](https://img-blog.csdnimg.cn/direct/32759e9a7505413288c238fdcb1b2e12.png)