用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。
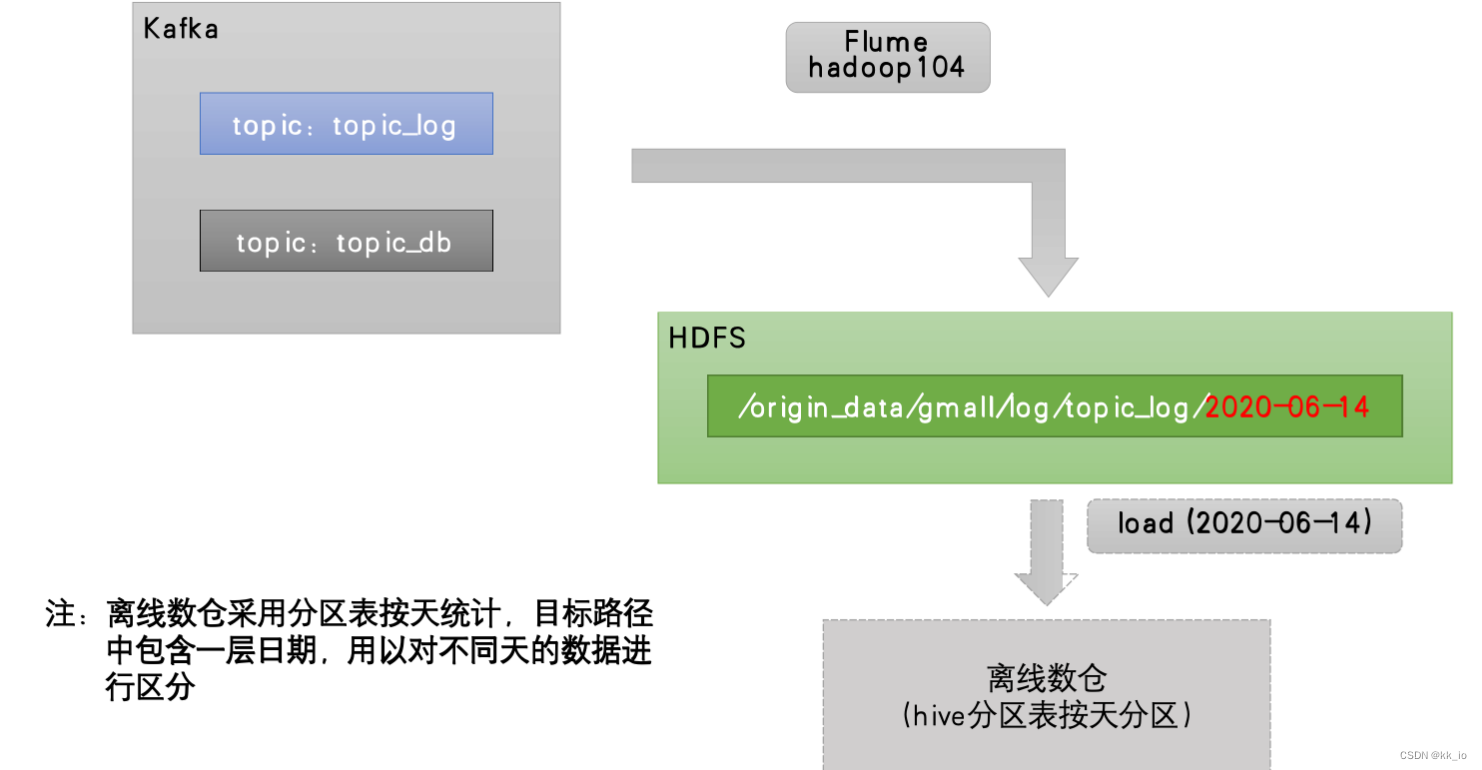
按照规划,该Flume需将Kafka中topic_log的数据发往HDFS。并且对每天产生的用户行为日志进行区分,将不同天的数据发往HDFS不同天的路径。
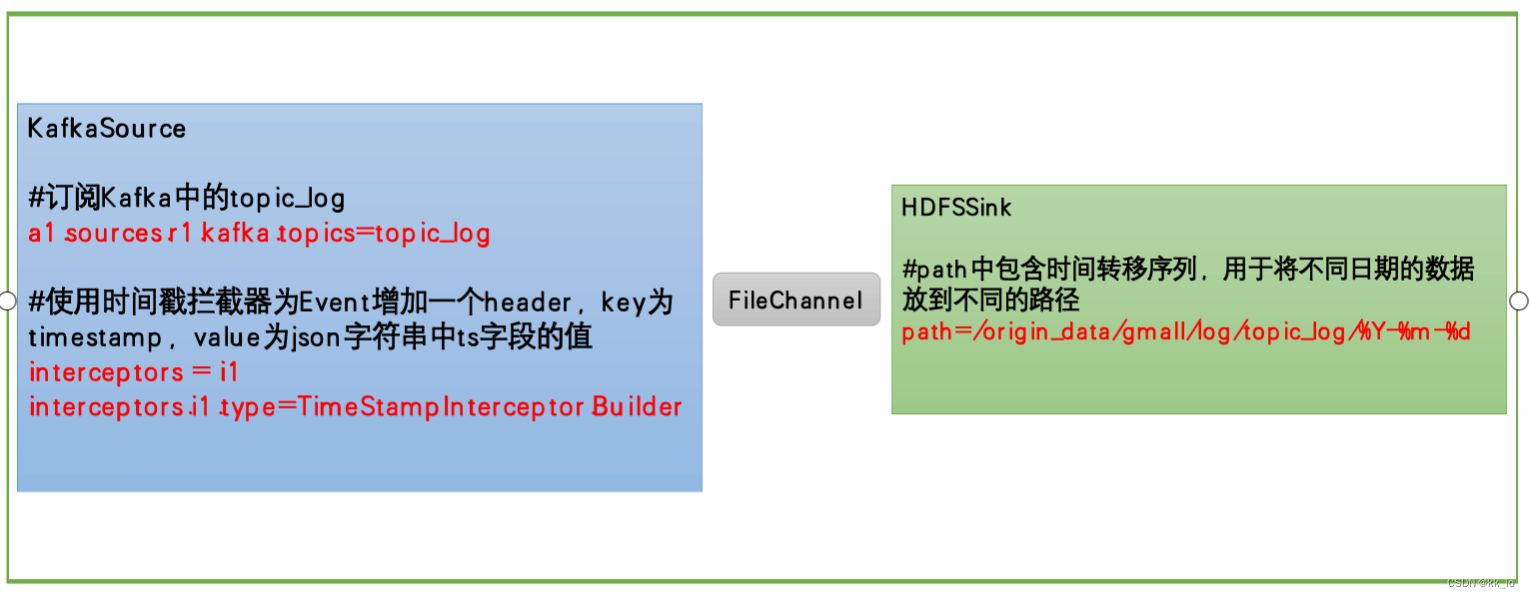
此处选择KafkaSource、FileChannel、HDFSSink。关键配置如下:
日志消费者 Flume 实操
-
在hadoop101 节点的Flume 的 job目录下创建 kafka_to_hdfs_log.conf,内容如下
配置注释:- FileChannel优化:配置 dataDirsk可以通过逗号分隔指向多个路径,每个路径对应不同硬盘,可以增加吞吐量。
- 新增checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据
#定义组件 a1.sources=r1 a1.channels=c1 a1.sinks=k1#配置source1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092 a1.sources.r1.kafka.topics=topic_log a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.logan.gmall.flume.interceptor.TimestampInterceptor$Builder#配置channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1 a1.channels.c1.maxFileSize = 2146435071 a1.channels.c1.capacity = 1000000 a1.channels.c1.keep-alive = 6#配置sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = log a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0#控制输出文件类型 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = gzip#组装 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
HDFS Sink 优化
- HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命。 - HDFS小文件处理。
官方默认三个参数配置写入HDFS 后会产生小文件: hdfs.rollInterval, hdfs.rollSize, hdfs.rollCount。
本次配置的参数为hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0。意味着文件在达到128M时会滚动生成新文件,或者文件超过 3600 秒会生成新文件。
- HDFS存入大量小文件,有什么影响?
-
编写 Flume 拦截器
- 解决问题
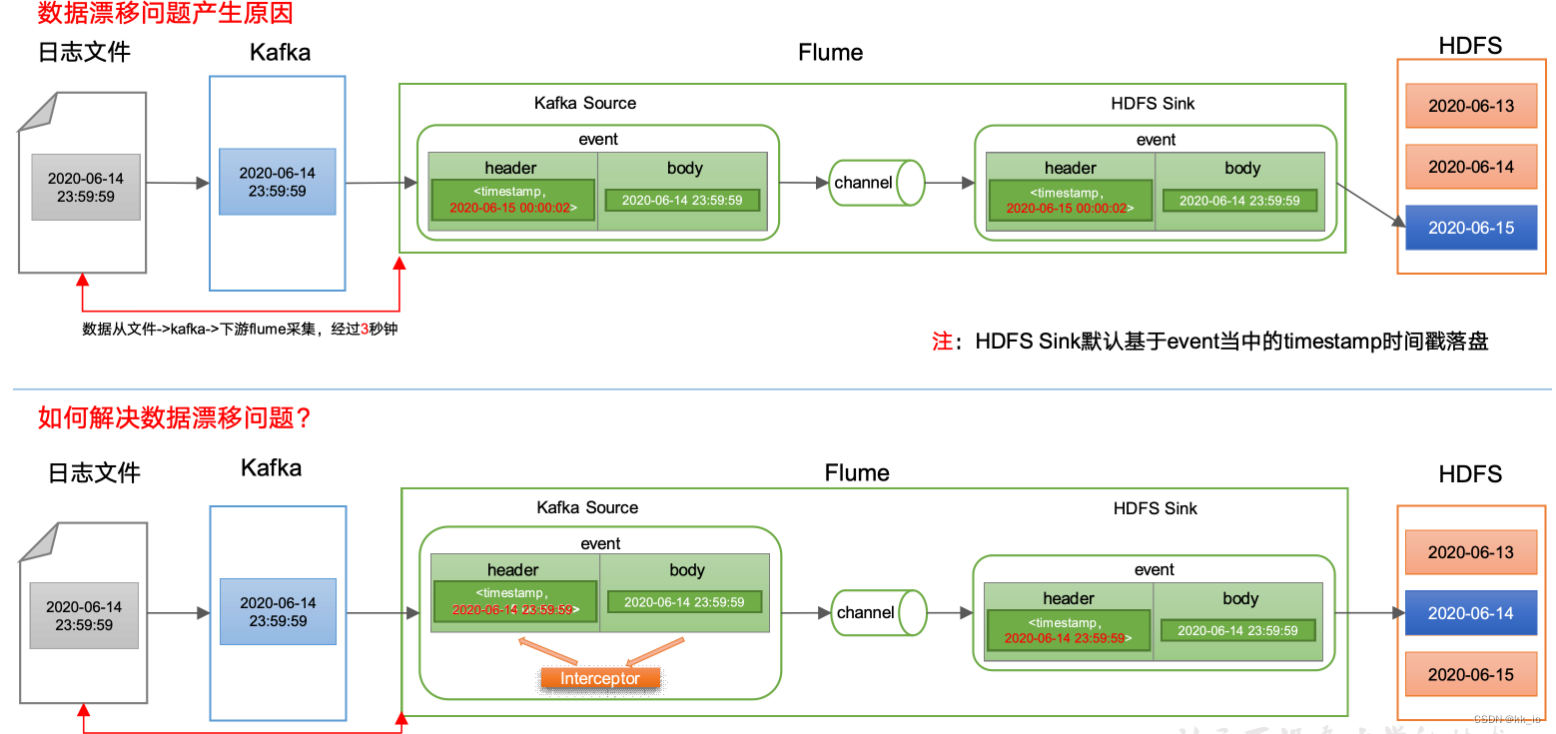
- 在com.logan.gmall.flume.interceptor包下创建TimestampInterceptor类
package com.logan.gmall.flume.interceptor;import com.alibaba.fastjson.JSONObject; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets; import java.util.List; import java.util.Map;public class TimestampInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {// 获取header和body数据Map<String, String> headers = event.getHeaders();String body = new String(event.getBody(), StandardCharsets.UTF_8);// 将body转换成JsonObject类型JSONObject jsonObject = JSONObject.parseObject(body);// 将header中的timestamp时间转换成body中的timestamp(解决数据漂移问题)String ts = jsonObject.getString("ts");headers.put("timestamp", ts);return event;}@Overridepublic List<Event> intercept(List<Event> list) {for (Event event : list) {intercept(event);}return list;}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new TimestampInterceptor();}@Overridepublic void configure(Context context) {}}@Overridepublic void close() {} } - 解决问题
-
将打好的包放入到hadoop101的/opt/module/flume/lib文件夹下
启动测试
- 启动 Zookeeper、Kafka 集群
- 启动 hadoop101 的消费Flume
[logan@hadoop101 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf -Dflume.root.logger=info,console
- 生成模拟数据
[logan@hadoop101 ~]$ vim /opt/module/applog/log/app.2023-12-14.log
{"common":{"ar":"110000","ba":"vivo","ch":"oppo","is_new":"0","md":"vivo iqoo3","mid":"mid_70997","os":"Android 11.0","uid":"776","vc":"v2.1.134"},"start":{"entry":"icon","loading_time":11968,"open_ad_id":16,"open_ad_ms":7891,"open_ad_skip_ms":0},"ts":1672503309000}
{"common":{"ar":"110000","ba":"vivo","ch":"oppo","is_new":"0","md":"vivo iqoo3","mid":"mid_70997","os":"Android 11.0","uid":"776","vc":"v2.1.134"},"displays":[{"display_type":"activity","item":"2","item_type":"activity_id","order":1,"pos_id":1},{"display_type":"activity","item":"2","item_type":"activity_id","order":2,"pos_id":1},{"display_type":"query","item":"9","item_type":"sku_id","order":3,"pos_id":1},{"display_type":"query","item":"18","item_type":"sku_id","order":4,"pos_id":4},{"display_type":"promotion","item":"35","item_type":"sku_id","order":5,"pos_id":4},{"display_type":"query","item":"35","item_type":"sku_id","order":6,"pos_id":4},{"display_type":"recommend","item":"13","item_type":"sku_id","order":7,"pos_id":5}],"page":{"during_time":14287,"page_id":"home"},"ts":1672503309000}
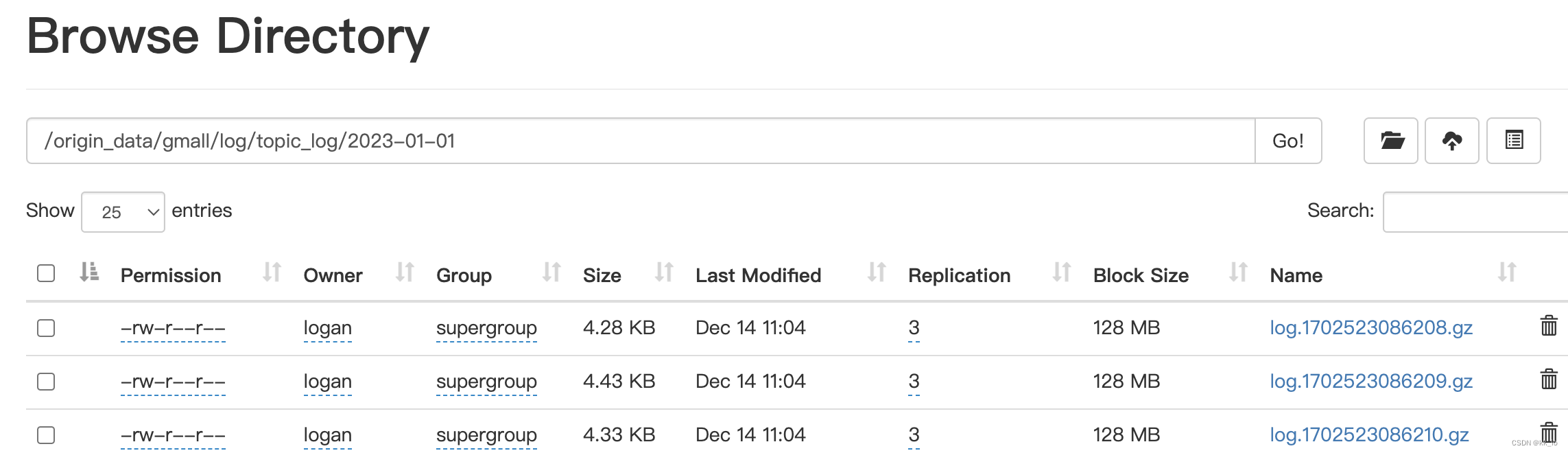
- 检查HFDS是否生成数据
- 当 HDFS 生成数据后,增加
[logan@hadoop101 bin]$ vim f2.sh
#!/bin/bashcase $1 in
"start")echo " --------启动 hadoop101 日志数据flume-------"ssh hadoop101 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")echo " --------停止 hadoop101 日志数据flume-------"ssh hadoop101 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
- 最终 HDFS 文件








![[Kubernetes]1.Kubernetes(K8S)介绍,基于腾讯云的K8S环境搭建集群以及裸机搭建K8S集群](https://img-blog.csdnimg.cn/direct/af4e9261d5c9426684cf01acf8390053.png)