原文: https://zhuanlan.zhihu.com/p/143092725
1. 概述
KNN 可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一。注意:KNN 算法是有监督学习中的分类算法,它看起来和另一个机器学习算法 K-means 有点像(K-means 是无监督学习算法),但却是有本质区别的。
2. 核心思想
KNN 的全称是 K Nearest Neighbors,意思是 K 个最近的邻居。从这个名字我们就能看出一些 KNN 算法的蛛丝马迹了。K 个最近邻居,毫无疑问,K 的取值肯定是至关重要的,那么最近的邻居又是怎么回事呢?其实,KNN 的原理就是当预测一个新的值 x 的时候,根据它距离最近的 K 个点是什么类别来判断 x 属于哪个类别。听起来有点绕,还是看看图吧。
3. 算法实现
3.1 Sklearn KNN参数概述
要使用 Sklearn KNN 算法进行分类,我们需要先了解 Sklearn KNN 算法的一些基本参数:
4. 算法特点
KNN是一种非参的、惰性的算法模型。什么是非参,什么是惰性呢?
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说 KNN 建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而 KNN 算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
5. 算法优缺点
5.1优点
简单易用。相比其他算法,KNN 算是比较简洁明了的算法,即使没有很高的数学基础也能搞清楚它的原理。
模型训练时间快,上面说到 KNN 算法是惰性的,这里也就不再过多讲述。
预测效果好。
对异常值不敏感。
5.2 缺点
对内存要求较高,因为该算法存储了所有训练数据。
预测阶段可能很慢。
对不相关的功能和数据规模敏感。
6. KNN 和 K-means比较
前面说到过,KNN 和 K-means 听起来有些像,但本质是有区别的,这里我们就顺便说一下两者的异同吧。
6.1 相同点:
K 值都是重点。
都需要计算平面中点的距离。
6.2 相异点:
KNN 和 K-means 的核心都是通过计算空间中点的距离来实现目的,只是他们的目的是不同的。KNN 的最终目的是分类,而 K-means 的目的是给所有距离相近的点分配一个类别,也就是聚类。
简单说,就是画一个圈,KNN 是让进来圈子里的人变成自己人,K-means 是让原本在圈内的人归成一类人。
至于什么时候应该选择使用 KNN 算法,Sklearn 的这张图给了我们一个答案:
在这里插入图片描述
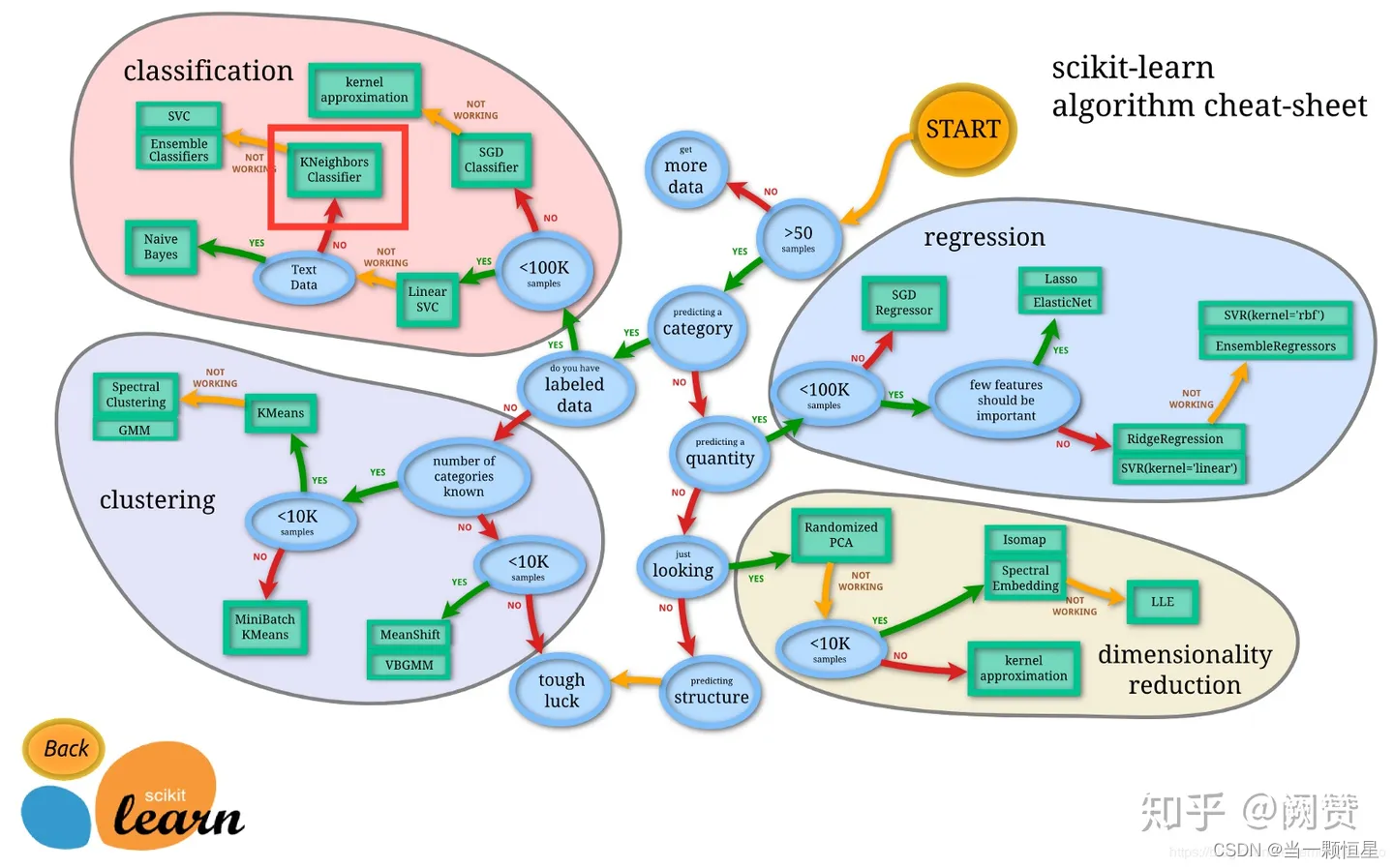
简单来说,就是当需要使用分类算法,且数据比较大的时候就可以尝试使用 KNN 算法进行分类了。
补充:
Scikit-learn (Sklearn) 是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据上图来选择相应的方法。Sklearn 具有以下特点:
- 简单高效的数据挖掘和数据分析工具;
- 让每个人能够在复杂环境中重复使用;
- 建立NumPy、Scipy、MatPlotLib 之上。