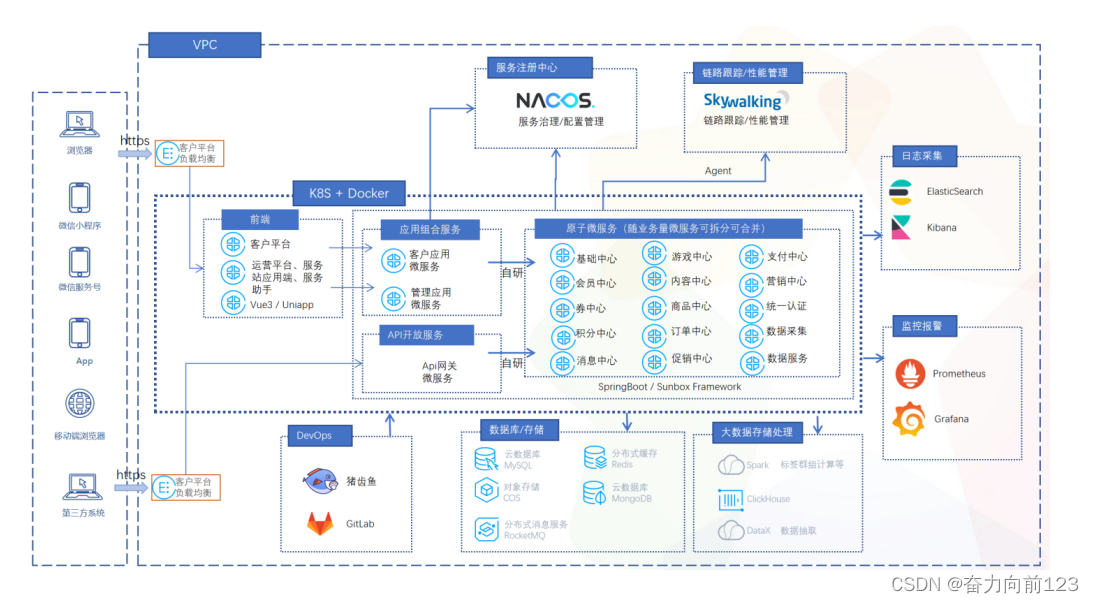
自动机器学习 (Auto Machine Learning) 的应用和方法
随着众多企业在大量场景中开始采用机器学习,前后期处理和优化的数据量及规模指数级增长。企业很难雇用充足的人手来完成与高级机器学习模型相关的所有工作,因此机器学习自动化工具是未来人工智能 (AI) 的关键组成部分,自动机器学习 (Automated Machine Learning,AutoML) 应运而生。AutoML 是AIOps多层技术平台中一款快速增长的工具。 自动机器学习是一种将人工智能 (Artificial Intelligence) 应用于问题的端到端周期自动化方法。一般情况下,数据科学家会负责构建机器学习 (ML) 模型,以及随后的数据预处理、特征工程、模型选择、超参数优化和模型后处理等复杂任务。AutoML 框架可以自动完成这些任务(或至少部分任务),让不具备数据科学专业知识的人也可以成功构建 ML 模型。 对那些因资源有限而无法全面投入使用 AI 的公司来说,自动化 ML 流程带来了机会。尽管实现机器学习流程全自动化依然任重而道远,但很多企业都开始在构建着眼于未来的工具,以进一步推动自动机器学习的发展。

为什么要使用自动机器学习工具?
研究当前的机器学习模型构建过程,我们发现,模型构建的代价高昂,不仅需要高水平的技术专家,还需要投入大量的时间、资金,反复地进行研发工作。以下为推动自动机器学习发展的四个因素:
缩小技能差距
由于企业很难招募到兼具领域知识和技能的人才来构建模型,导致缺乏开发 AI 和 ML 相关的专业技术,阻碍了机器学习的进一步发展。借助自动机器学习,非专业人才也可以参与构建AI。企业不仅无需招聘大量高专业化人才,还能提高创新速度,最终实现人工智能的规模化应用。
缩短面市时间
在一些快速发展的领域,缩短上市时间就能取得巨大的竞争优势。而机器学习流程自动化恰好能够减少构建模型所需的时间。对于从未部署过 AI 的公司来说,自动机器学习不仅能够降低其进入该领域的门槛,还可以提供成功的解决方案。
降低成本
从零开始构建机器学习模型,需要耗费大量的时和资金。数据科学家及其他机器学习领域的专家,他们的薪资相对较高。从零开始构建模型,费时又费力,相比之下,自动机器学习工具则具有较高的性价比。
构建更佳模型
自动机器学习在模型和超参数方面的迭代速度比手工操作更快。在规定时间段内,迭代越多,所构建的模型性能就越高。自动机器学习既提高了决策效率,又加快了模型研究的速度。 此外,数据科学家也在努力探索适用于深度神经网络的高性能架构。自动机器学习可以自动搜索和评估架构(即神经架构搜索),从而加速开发人工智能模型解决方案。
自动机器学习的方法
对于机器学习的自动化,有不同的定义。如今,流传比较广泛的是一个对自动机器学习进行分级的体系(类似于自动驾驶汽车的分级):
- 初级:无自动化,数据科学家从零开始编写算法。
- 1 级:使用一些高级API。
- 2 级:自动调整超参数和选择模型。
- 3 级:自动特征工程、特征选择和数据增强。
- 4 级:自动领域和特定问题的特征工程、数据扩充和数据整合。
- 5 级:完全自动化,无需输入或指导来解决机器学习问题。
虽然目前市场上有很多不错的 3 级自动机器学习解决方案,但不同公司在实际实施中又降为了 1 级或 2 级。在这些不同等级的自动化过程中,有几个自动机器学习方法值得讨论:
模型选择和集成
自动机器学习可以通过输入相同数据来训练不同算法,从而实现迭代,选择性能最佳的模型。自动机器学习还可以借助混合和叠加等技术来与多个模型集成,以获取更好的结果。
超参数优化 (HPO)
所有机器学习算法都有参数,或者模型中每个变量或特征的权重。参数来自于训练过程,而超参数则是一个用于控制学习过程的可调值。超参数优化 (HPO) 是指通过调整超参数来提高模型性能。自动机器学习工具可以自动评估各种超参数,以确定可以产生最高性能的模型集合。
特征工程
在自动机器学习中,特征工程不如模型选择和 HPO 那么常见,但由于其能够提高模型的预测性,因此越来越受重视。特征工程是指从现有输入中构建新的输入特征(或解释变量)。特征工程强调了模型预测时需要了解的相关元素,因而会影响模型性能。所以,数据科学家必须一次次地手动添加特征,但有了自动机器学习工具,这项工作可以自动完成。这些工具从给定的输入中提取相关和有意义的特征,并测试不同的特征组合,以生成性能最高的模型。
自动机器学习的前景
在达到 5 级,即完全自动化的解决方案之前,自动机器学习行业仍有漫长的道路。尽管如此,很多企业还是投资了较低级别的自动机器学习。一般来说,这些企业将精力主要放在了模型选择和 HPO上。特征工程的进一步发展或将推动自动机器学习领域在新创新阶段取得突破。 随着自动化需求增长和工具改进,构建机器学习的难度和资源密集度将会降低,机器学习的应用范围也将更加广泛。
澳鹏数据科学家 Shambhavi Srivastava 对自动机器学习的看法
在澳鹏,我们团队致力于构建机器学习模型。我与数据科学家、机器学习工程师以及 DevOps 的同事协作,致力于建立、整合最先进的 (SOTA) 模型。 构建机器学习模型均包括以下多个步骤:
- 从业务角度理解问题
- 数据准备(收集、清理、分析)
- 构建模型
- 评估性能
- 将模型容器化并部署到生产中
- 观察模型在客户端数据生成上的性能。
上述每个步骤对于项目的成功都至关重要。数据科学家可以通过 自动机器学习来提高成功率。通过自动化工作流程和大幅提升各种整体假设和单个模型属性的测试速度,自动机器学习提高了数据科学家的工作质量。 数据科学家的日常工作是,决定并实施对给定业务用例最有效的机器学习算法。然而,这项任务很繁琐,而且容易出现人为错误和偏见。自动机器学习可以自动化和简化这一过程,使团队能够通过持续评估性能来运行各种机器学习模型,直到满足最佳参数为止。这些自动机器学习功能可以加速机器学习模型的生产,并通过推出准确度更高的模型来提高项目的投资回报率 (ROI)。 模型选择中最具挑战性的环节就是探寻未知。这是科学家将自动机器学习视为头号难题的原因所在。自动机器学习通过减少代码和自动调整超参数,来降低 ML 任务的难度。自动机器学习的核心创新是超参数搜索和寻找最佳匹配。