determine_dl_model_detection_param
“determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。
这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议使用这一过程来优化训练和推断性能。
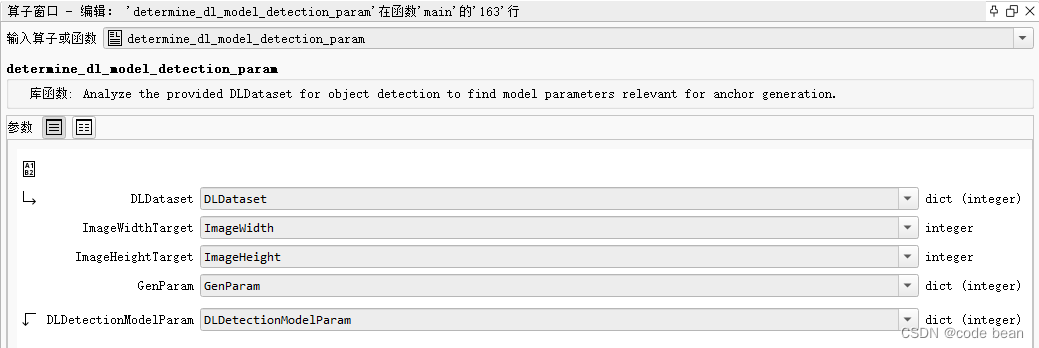
过程签名
determine_dl_model_detection_param(: : DLDataset, ImageWidthTarget, ImageHeightTarget, GenParam : DLDetectionModelParam)
描述
该过程用于分析提供的深度学习数据集(DLDataset)以进行目标检测,以确定与锚点生成相关的模型参数。生成的DLDetectionModelParam是一个包含建议值的字典,用于各种目标检测模型的参数。
参数
- DLDataset:用于目标检测的深度学习数据集的字典。
- ImageWidthTarget:作为模型输入的目标图像宽度(经过预处理后的图像宽度)。
- ImageHeightTarget:作为模型输入的目标图像高度(经过预处理后的图像高度)。
- GenParam:包含通用输入参数的字典。
- DLDetectionModelParam:包含建议的模型参数的输出字典。
参数解析
第一个参数DLDataset,就是我们读取到的数据集,数据集 (数据集就是我们标注好的图片数据集, 我们可以通过 read_dict() 读取halcon提供的数据集。也可以通过 read_dl_dataset_from_coco 读取通用的coco数据集)
图片缩放
第二,第三个参数,是图片的大小设置。我们知道数据集里是有描述图片原始大小的数据的。这里需要你输入预处理后图片的大小,也就是说,你可以通过这两个参数对图片进行缩放。一般我们会设置一个较小的大小,已加快训练的速度!
GenParam
GenParam 是一个字典,包含一些通用的输入参数,可以用来影响 determine_dl_model_detection_param 过程中参数的确定。
使用输入字典GenParam,可以进一步影响参数的确定。可以设置不同的键值对来影响锚点生成和模型参数的确定。
你可以根据你的需求在 GenParam 中设置不同的键值对来调整算法的行为。以下是键和对应的值:
-
‘anchor_num_subscales’: 整数值(大于0),确定搜索锚点子尺度数量的上限值。默认值为3。
-
‘class_ids_no_orientation’: 元组,包含表示类别标识的整数值。设置那些应该忽略方向的类别的标识。这些被忽略类别的边界框被视为方向为0的轴对齐边界框。仅适用于检测实例类型为’rectangle2’的情况。
-
‘display_histogram’: 确定是否显示数据直方图以进行数据集的视觉分析。可能的值有’true’和’false’(默认为’false’)。
-
‘domain_handling’: 指定图像域的处理方式。可能的值有:
'full_domain'(默认):图像不被裁剪。'crop_domain':图像被缩小到其域定义。'ignore_direction':布尔值(或’true’/‘false’),确定是否考虑边界框的方向。仅在检测实例类型为’rectangle2’的情况下可用。参考 ‘get_dl_model_param’ 文档以获取有关此参数的更多信息。
-
‘max_level’: 整数值(大于1),确定搜索最大层级的上限值。默认值为6。
-
‘max_num_samples’: 整数值(大于0或-1),确定用于确定参数值的最大样本数。如果设置为-1,则选择所有样本。请注意,不要将此值设置得太高,因为这可能导致内存消耗过大,对机器造成高负载。然而,如果 ‘max_num_samples’ 设置得太低,确定的检测参数可能无法很好地代表数据集。默认值为1500。
-
‘min_level’: 整数值(大于1),确定搜索最小层级的下限值。默认值为2。
-
‘preprocessed_path’: 指定预处理目录的路径。预处理目录包含DLDataset的字典(.hdict文件),以及一个名为’samples’的子目录,其中包含预处理的样本(例如,由过程’preprocess_dl_dataset’生成)。对于已经预处理的数据集,将忽略输入参数ImageWidthTarget和ImageHeightTarget,并可将它们设置为[]。仅当数据集已经为应用程序进行了预处理时,此参数才适用。
-
‘image_size_constant’: 如果将此参数设置为’true’,则假定数据集中的所有图像具有相同的大小,以加速处理。图像大小由数据集中的第一个样本确定。此参数仅在数据集尚未预处理且’domain_handling’为’full_domain’时适用。默认值为’true’。
-
‘split’: 确定用于分析的数据集拆分。可能的值包括 ‘train’(默认)、‘validation’、‘test’ 和 ‘all’。如果指定的拆分无效或数据集未创建拆分,则使用所有样本。
-
‘compute_max_overlap’: 如果将此参数设置为’true’,将为数据集确定检测参数 ‘max_overlap’ 和 ‘max_overlap_class_agnostic’。
建议的模型参数 DLDetectionModelParam
DLDetectionModelParam是模型的输出参数
输出字典(DLDetectionModelParam)包括以下参数的建议值:
- ‘class_ids’:类别标识
- ‘class_names’:类别名称
- ‘image_width’:图像宽度
- ‘image_height’:图像高度
- ‘min_level’:最小层级
- ‘max_level’:最大层级
- ‘instance_type’:实例类型
- ‘anchor_num_subscales’:锚点子尺度数量
- ‘anchor_aspect_ratios’:锚点纵横比
- ‘anchor_angles’:锚点角度(仅用于’instance_type’为’rectangle2’的模型)
- ‘ignore_direction’:是否忽略方向(仅用于’instance_type’为’rectangle2’的模型)
- ‘max_overlap’:最大重叠度(如果’compute_max_overlap’设置为’true’)
- ‘max_overlap_class_agnostic’:最大重叠度(如果’compute_max_overlap’设置为’true’)
注意事项
文档中提到的返回值是对模型运行时间和检测性能之间的折衷的近似值,可能需要进一步的实验来优化参数。此外,建议的参数是基于原始数据集而不考虑训练期间可能的数据增强。如果应用了某些数据增强方法(如’mirror’、‘rotate’),可能需要调整生成的参数以涵盖所有边界框形状。
小结
determine_dl_model_detection_param 会根据输入的数据集,得到模型的某些高级参数,这些高级参数会用到后续的训练和推理。换句话说,训练和推理需要用到一些高级参数。 而这个函数,可以根据输入的数据集,帮你分析,然后得到这些高级参数的值,让你用于后续的操作!这个函数让我们后续调参有了一定的依据!
代码上下文
*
* ************************
* ** Set parameters ***
* ************************
*
* Set obligatory parameters.
Backbone := 'pretrained_dl_classifier_compact.hdl'
NumClasses := 10
* Image dimensions of the network. Later, these values are
* used to rescale the images during preprocessing.
ImageWidth := 512
ImageHeight := 320* Read in a DLDataset.
* Here, we read the data from a COCO file.
* Alternatively, you can read a DLDataset dictionary
* as created by e.g., the MVTec Deep Learning Tool using read_dict().
read_dl_dataset_from_coco (PillBagJsonFile, HalconImageDir, dict{read_segmentation_masks: false}, DLDataset)
*
* Split the dataset into train/validation and test.
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
*
* **********************************************
* ** Determine model parameters from data ***
* **********************************************
*
* Generate model parameters min_level, max_level, anchor_num_subscales,
* and anchor_aspect_ratios from the dataset in order to improve the
* training result. Please note that optimizing the model parameters too
* much on the training data can lead to overfitting. Hence, this should
* only be done if the actual application data are similar to the training
* data.
GenParam := dict{['split']: 'train'}
*
determine_dl_model_detection_param (DLDataset, ImageWidth, ImageHeight, GenParam, DLDetectionModelParam)
*
* Get the generated model parameters.
MinLevel := DLDetectionModelParam.min_level
MaxLevel := DLDetectionModelParam.max_level
AnchorNumSubscales := DLDetectionModelParam.anchor_num_subscales
AnchorAspectRatios := DLDetectionModelParam.anchor_aspect_ratios
*
* *******************************************
* ** Create the object detection model ***
* *******************************************
*
* Create dictionary for generic parameters and create the object detection model.
DLModelDetectionParam := dict{}
DLModelDetectionParam.image_width := ImageWidth
DLModelDetectionParam.image_height := ImageHeight
DLModelDetectionParam.image_num_channels := ImageNumChannels
DLModelDetectionParam.min_level := MinLevel
DLModelDetectionParam.max_level := MaxLevel
DLModelDetectionParam.anchor_num_subscales := AnchorNumSubscales
DLModelDetectionParam.anchor_aspect_ratios := AnchorAspectRatios
DLModelDetectionParam.capacity := Capacity
*
* Get class IDs from dataset for the model.
ClassIDs := DLDataset.class_ids
DLModelDetectionParam.class_ids := ClassIDs
* Get class names from dataset for the model.
ClassNames := DLDataset.class_names
DLModelDetectionParam.class_names := ClassNames
*
* Create the model.
create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle)
*
* Write the initialized DL object detection model
* to train it later in part 2.
write_dl_model (DLModelHandle, DLModelFileName)
*
*
* *********************************
* ** Preprocess the dataset ***
* *********************************
*
* Get preprocessing parameters from model.
create_dl_preprocess_param_from_model (DLModelHandle, 'none', 'full_domain', [], [], [], DLPreprocessParam)
*
* Preprocess the dataset. This might take a few minutes.
GenParam := dict{overwrite_files: 'auto'}
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename)
*
* Write preprocessing parameters to use them in later parts.
write_dict (DLPreprocessParam, PreprocessParamFileName, [], [])从这里,我们就看到了,create_dl_model_detection 创建检测模型的时候,就用到了这些参数了!后续的训练过程中也会用到,我们下一篇见