Flink系列之:大状态与 Checkpoint 调优
- 一、概述
- 二、监控状态和 Checkpoints
- 三、Checkpoint 调优
- 四、RocksDB 调优
- 五、增量 Checkpoint
- 六、RocksDB 或 JVM 堆中的计时器
- 七、RocksDB 内存调优
- 八、容量规划
- 九、压缩
- 十、Task 本地恢复
- 十一、主要(分布式存储)和次要(task 本地)状态快照的关系
- 十二、配置 task 本地恢复
- 十三、不同 state backends 的 task 本地恢复的详细介绍
- 十四、Allocation-preserving 调度
一、概述
Flink 应用要想在大规模场景下可靠地运行,必须要满足如下两个条件:
- 应用程序需要能够可靠地创建 checkpoints。
- 在应用故障后,需要有足够的资源追赶数据输入流。
第一部分讨论如何大规模获得良好性能的 checkpoints。 后一部分解释了一些关于要规划使用多少资源的最佳实践。
二、监控状态和 Checkpoints
监控 checkpoint 行为最简单的方法是通过 UI 的 checkpoint 部分。
这两个指标(均通过 Task 级别 Checkpointing 指标 展示) 以及在 监控 Checkpoint)中,当看 checkpoint 详细信息时,特别有趣的是:
- 算子收到第一个 checkpoint barrier 的时间。当触发 checkpoint 的耗费时间一直很高时,这意味着 checkpoint barrier 需要很长时间才能从 source 到达 operators。 这通常表明系统处于反压下运行。
- Alignment Duration,为处理第一个和最后一个 checkpoint barrier 之间的时间。在 unaligned checkpoints 下,exactly-once 和 at-least-once checkpoints 的 subtasks 处理来自上游 subtasks 的所有数据,且没有任何中断。 然而,对于 aligned exactly-once checkpoints,已经收到 checkpoint barrier 的通道被阻止继续发送数据,直到所有剩余的通道都赶上并接收它们的 checkpoint barrier(对齐时间)。
理想情况下,这两个值都应该很低 - 较高的数值意味着 由于存在反压(没有足够的资源来处理传入的记录),导致checkpoint barriers 在作业中的移动速度较慢,这也可以通过处理记录的端到端延迟在增加来观察到。 请注意,在出现瞬态反压、数据倾斜或网络问题时,这些数值偶尔会很高。
Unaligned checkpoints 可用于加快checkpoint barriers的传播。 但是请注意,这并不能解决导致反压的根本问题(端到端记录延迟仍然很高)。
三、Checkpoint 调优
应用程序可以配置定期触发 checkpoints。 当 checkpoint 完成时间超过 checkpoint 间隔时,在正在进行的 checkpoint 完成之前,不会触发下一个 checkpoint。默认情况下,一旦正在进行的 checkpoint 完成,将立即触发下一个 checkpoint。
当 checkpoints 完成的时间经常超过 checkpoints 基本间隔时(例如,因为状态比计划的更大,或者访问 checkpoints 所在的存储系统暂时变慢), 系统不断地进行 checkpoints(一旦完成,新的 checkpoints 就会立即启动)。这可能意味着过多的资源被不断地束缚在 checkpointing 中,并且 checkpoint 算子进行得缓慢。 此行为对使用 checkpointed 状态的流式应用程序的影响较小,但仍可能对整体应用程序性能产生影响。
为了防止这种情况,应用程序可以定义 checkpoints 之间的最小等待时间:
StreamExecutionEnvironment.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds)
此持续时间是指从最近一个 checkpoint 结束到下一个 checkpoint 开始之间必须经过的最小时间间隔。下图说明了这如何影响 checkpointing。

注意: 可以配置应用程序(通过CheckpointConfig)允许同时进行多个 checkpoints。 对于 Flink 中状态较大的应用程序,这通常会使用过多的资源到 checkpointing。 当手动触发 savepoint 时,它可能与正在进行的 checkpoint 同时进行。
四、RocksDB 调优
许多大型 Flink 流应用程序的状态存储主要是 RocksDB State Backend。 该backend在主内存之上提供了很好的拓展能力,并且可靠地存储了大的 keyed state
RocksDB 的性能可能因配置而异,本节讲述了一些使用 RocksDB State Backend 调优作业的最佳实践。
五、增量 Checkpoint
在减少 checkpoints 花费的时间方面,开启增量 checkpoints 应该是首要考虑因素。 与完整 checkpoints 相比,增量 checkpoints 可以显着减少 checkpointing 时间,因为增量 checkpoints 仅存储与先前完成的 checkpoint 不同的增量文件,而不是存储全量数据备份。
六、RocksDB 或 JVM 堆中的计时器
计时器(Timer) 默认存储在 RocksDB 中,这是更健壮和可扩展的选择。
当性能调优作业只有少量计时器(没有窗口,且在 ProcessFunction 中不使用计时器)时,将这些计时器放在堆中可以提高性能。 请谨慎使用此功能,因为基于堆的计时器可能会增加 checkpointing 时间,并且自然无法扩展到内存之外。
七、RocksDB 内存调优
RocksDB State Backend 的性能在很大程度上取决于它可用的内存量。为了提高性能,增加内存会有很大的帮助,或者调整内存的功能。 默认情况下,RocksDB State Backend 将 Flink 的托管内存用于 RocksDB 的缓冲区和缓存(State.Backend.RocksDB.memory.managed:true)
- 尝试提高性能的第一步应该是增加托管内存的大小。这通常会大大改善这种情况,而不是通过调整 RocksDB 底层参数引入复杂性。 尤其是在容器、进程规模较大的情况下,除非应用程序本身逻辑需要大量的 JVM 堆,否则大部分总内存通常都可以用于 RocksDB 。默认的托管内存比例 (0.4) 是保守的,当 TaskManager 进程的内存为很多 GB 时,通常是可以增加该托管内存比例。
- 在 RocksDB 中,写缓冲区的数量取决于应用程序中所拥有的状态数量(数据流中所有算子的状态)。每个状态对应一个列族(ColumnFamily),它需要自己写缓冲区。因此,具有多状态的应用程序通常需要更多的内存才能获得相同的性能。
- 你可以尝试设置 state.backend.rocksdb.memory.managed: false 来使用列族(ColumnFamily)内存的 RocksDB 与使用托管内存的 RocksDB 的性能对比。特别是针对基准测试(假设没有或适当的容器内存限制)或回归测试 Flink 早期版本时,这可能会很有用。 与使用托管内存(固定内存池)相比,不使用托管内存意味着 RocksDB 分配的内存与应用程序中的状态数成比例(内存占用随应用程序的变化而变化)。根据经验,非托管模式(除非使用列族(ColumnFamily)RocksDB)的上限约为 “140MB * 跨所有 tasks 的状态 * slots 个数”。 计时器也算作状态!
- 如果你的应用程序有许多状态,并且你看到频繁的 MemTable 刷新(写端瓶颈),但你不能提供更多的内存,你可以增加写缓冲区的内存比例(state.backend.rocksdb.memory.write-buffer-ratio)。
- 一个高级选项(专家模式)是通过 RocksDBOptionFactory 来调整 RocksDB 的列族(ColumnFamily)选项(块大小、最大后台刷新线程等),以减少具有多种状态的 MemTable 刷新次数:
public class MyOptionsFactory implements ConfigurableRocksDBOptionsFactory {@Overridepublic DBOptions createDBOptions(DBOptions currentOptions, Collection<AutoCloseable> handlesToClose) {// increase the max background flush threads when we have many states in one operator,// which means we would have many column families in one DB instance.return currentOptions.setMaxBackgroundFlushes(4);}@Overridepublic ColumnFamilyOptions createColumnOptions(ColumnFamilyOptions currentOptions, Collection<AutoCloseable> handlesToClose) {// decrease the arena block size from default 8MB to 1MB. return currentOptions.setArenaBlockSize(1024 * 1024);}@Overridepublic OptionsFactory configure(ReadableConfig configuration) {return this;}
}
八、容量规划
本节讨论如何确定 Flink 作业应该使用多少资源才能可靠地运行。 容量规划的基本经验法则是:
应该有足够的资源保障正常运行时不出现反压 如何检查应用程序是否在反压下运行,详细信息请参阅 反压监控。
在无故障时间内无反压运行程序所需的资源之上能够提供一些额外的资源。 需要这些资源来“追赶”在应用程序恢复期间积累的输入数据。 这通常取决于恢复操作需要多长时间(这取决于在故障恢复时需要加载到新 TaskManager 中的状态大小)以及故障恢复的速度。
重要提示:基准点应该在开启 checkpointing 来建立,因为 checkpointing 会占用一些资源(例如网络带宽)。
临时反压通常是允许的,在负载峰值、追赶阶段或外部系统(sink 到外部系统)出现临时减速时,这是执行流控制的重要部分。
在某些操作下(如大窗口)会导致其下游算子的负载激增: 在有窗口的情况下,下游算子可能在构建窗口时几乎无事可做,而在触发窗口时有负载要做。 下游并行度的规划需要考虑窗口的输出量以及处理这种峰值的速度。
重要提示:为了方便以后增加资源,请确保将流应用程序的最大并行度设置为一个合理的数字。最大并行度定义了当扩缩容程序时(通过 savepoint )可以设置程序并行度的上限。
Flink 的内部以键组(key groups) 的最大并行度为粒度跟踪分布式状态。 Flink 的设计力求使最大并行度的值达到很高的效率,即使执行程序时并行度很低。
九、压缩
Flink 为所有 checkpoints 和 savepoints 提供可选的压缩(默认:关闭)。 目前,压缩总是使用 snappy 压缩算法(版本 1.1.10.x), 但我们计划在未来支持自定义压缩算法。 压缩作用于 keyed state 下 key-groups 的粒度,即每个 key-groups 可以单独解压缩,这对于重新缩放很重要。
可以通过 ExecutionConfig 开启压缩:
ExecutionConfig executionConfig = new ExecutionConfig();
executionConfig.setUseSnapshotCompression(true);
压缩选项对增量快照没有影响,因为它们使用的是 RocksDB 的内部格式,该格式始终使用开箱即用的 snappy 压缩。
十、Task 本地恢复
问题引入
在 Flink 的 checkpointing 中,每个 task 都会生成其状态快照,然后将其写入分布式存储。 每个 task 通过发送一个描述分布式存储中的位置状态的句柄,向 jobmanager 确认状态的成功写入。 JobManager 反过来收集所有 tasks 的句柄并将它们捆绑到一个 checkpoint 对象中。
在恢复的情况下,jobmanager 打开最新的 checkpoint 对象并将句柄发送回相应的 tasks,然后可以从分布式存储中恢复它们的状态。 使用分布式存储来存储状态有两个重要的优势。 首先,存储是容错的,其次,分布式存储中的所有状态都可以被所有节点访问,并且可以很容易地重新分配(例如,用于重新扩缩容)。
但是,使用远程分布式存储也有一个很大的缺点:所有 tasks 都必须通过网络从远程位置读取它们的状态。 在许多场景中,恢复可能会将失败的 tasks 重新调度到与前一次运行相同的 taskmanager 中(当然也有像机器故障这样的异常),但我们仍然必须读取远程状态。这可能导致大状态的长时间恢复,即使在一台机器上只有一个小故障。
Task 本地状态恢复正是针对这个恢复时间长的问题,其主要思想如下:对于每个 checkpoint ,每个 task 不仅将 task 状态写入分布式存储中, 而且还在 task 本地存储(例如本地磁盘或内存)中保存状态快照的次要副本。请注意,快照的主存储仍然必须是分布式存储,因为本地存储不能确保节点故障下的持久性,也不能为其他节点提供重新分发状态的访问,所以这个功能仍然需要主副本。
然而,对于每个 task 可以重新调度到以前的位置进行恢复的 task ,我们可以从次要本地状态副本恢复,并避免远程读取状态的成本。考虑到许多故障不是节点故障,即使节点故障通常一次只影响一个或非常少的节点, 在恢复过程中,大多数 task 很可能会重新部署到它们以前的位置,并发现它们的本地状态完好无损。这就是 task 本地恢复有效地减少恢复时间的原因。
请注意,根据所选的 state backend 和 checkpointing 策略,在每个 checkpoint 创建和存储次要本地状态副本时,可能会有一些额外的成本。 例如,在大多数情况下,实现只是简单地将对分布式存储的写操作复制到本地文件。
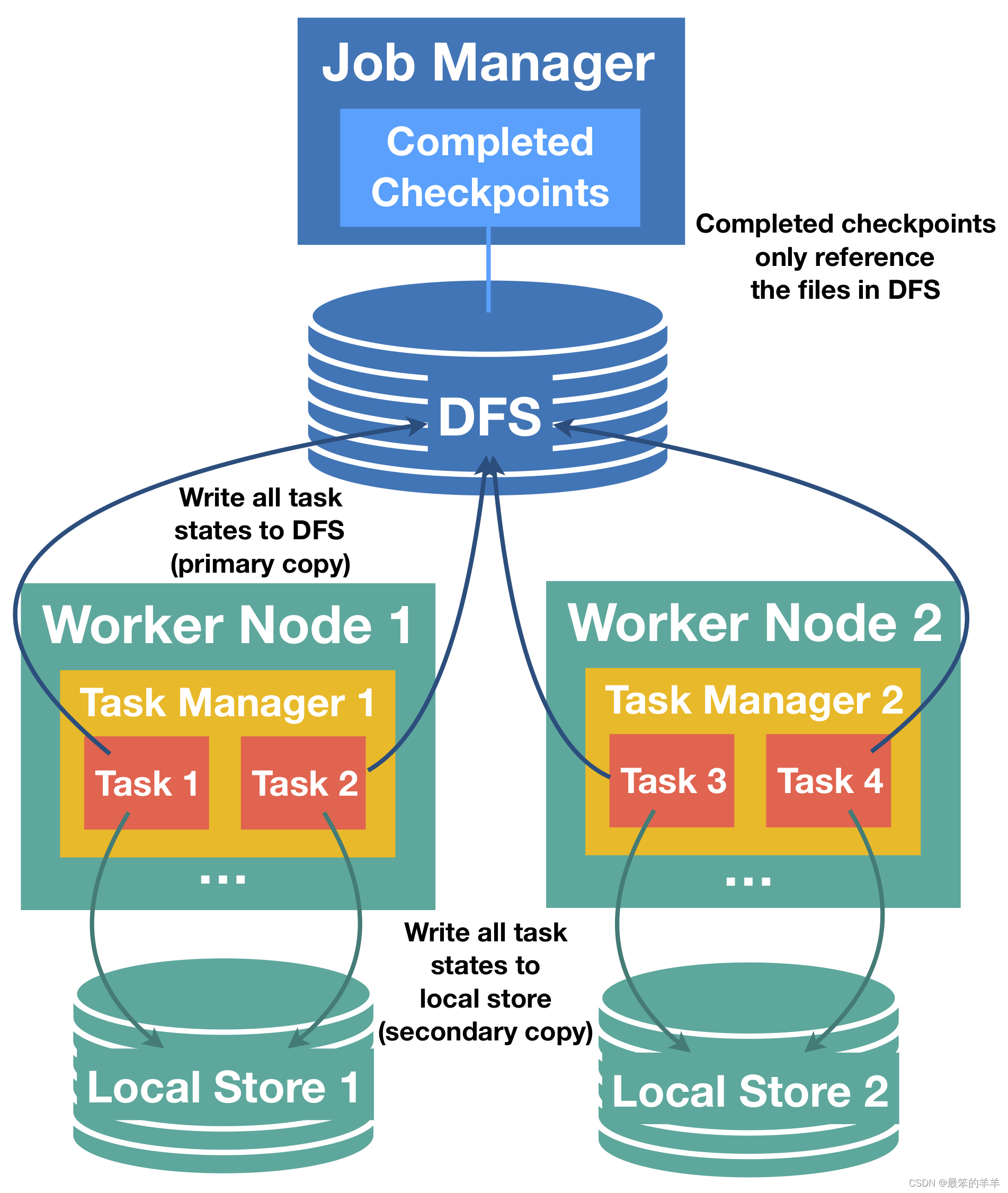
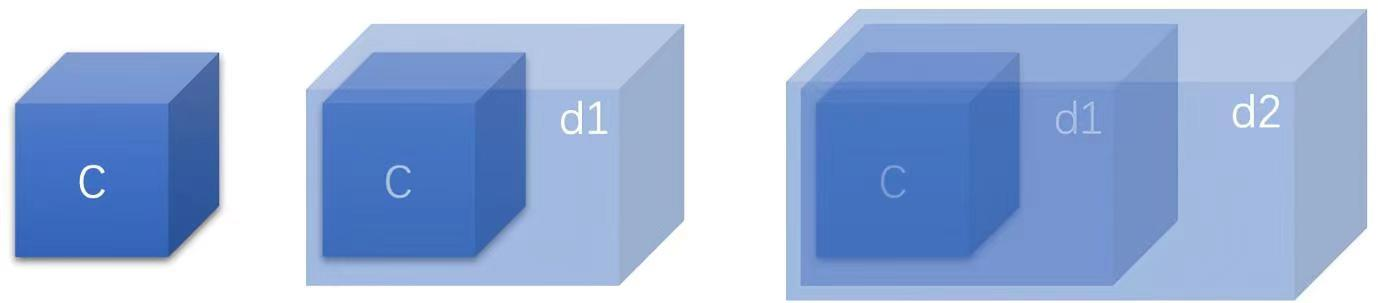
十一、主要(分布式存储)和次要(task 本地)状态快照的关系
Task 本地状态始终被视为次要副本,checkpoint 状态始终以分布式存储中的副本为主。 这对 checkpointing 和恢复期间的本地状态问题有影响:
- 对于 checkpointing ,主副本必须成功,并且生成次要本地副本的失败不会使 checkpoint 失败。 如果无法创建主副本,即使已成功创建次要副本,checkpoint 也会失败。
- 只有主副本由 jobmanager 确认和管理,次要副本属于 taskmanager ,并且它们的生命周期可以独立于它们的主副本。 例如,可以保留 3 个最新 checkpoints 的历史记录作为主副本,并且只保留最新 checkpoint 的 task 本地状态。
- 对于恢复,如果匹配的次要副本可用,Flink 将始终首先尝试从 task 本地状态恢复。 如果在次要副本恢复过程中出现任何问题,Flink 将透明地重试从主副本恢复 task。 仅当主副本和(可选)次要副本失败时,恢复才会失败。 在这种情况下,根据配置,Flink 仍可能回退到旧的 checkpoint。
- Task 本地副本可能仅包含完整 task 状态的一部分(例如,写入一个本地文件时出现异常)。 在这种情况下,Flink 会首先尝试在本地恢复本地部分,非本地状态从主副本恢复。 主状态必须始终是完整的,并且是 task 本地状态的超集。
- Task 本地状态可以具有与主状态不同的格式,它们不需要相同字节。 例如,task 本地状态甚至可能是在堆对象组成的内存中,而不是存储在任何文件中。
- 如果 taskmanager 丢失,则其所有 task 的本地状态都会丢失。
十二、配置 task 本地恢复
Task 本地恢复 默认禁用,可以通过 Flink 的 CheckpointingOptions.LOCAL_RECOVERY 配置中指定的键 state.backend.local-recovery 来启用。 此设置的值可以是 true 以启用或 false(默认)以禁用本地恢复。
注意,unaligned checkpoints 目前不支持 task 本地恢复。
十三、不同 state backends 的 task 本地恢复的详细介绍
限制:目前,task 本地恢复仅涵盖 keyed state backends。 Keyed state 通常是该状态的最大部分。 在不久的将来,我们还将支持算子状态和计时器(timers)。
以下 state backends 可以支持 task 本地恢复。
- HashMapStateBackend: keyed state 支持 task 本地恢复。 该实现会将状态复制到本地文件。 这会引入额外的写入成本并占用本地磁盘空间。 将来,我们可能还会提供一种将 task 本地状态保存在内存中的实现。
- EmbeddedRocksDBStateBackend: 支持 keyed state 的 task 本地恢复。对于全量 checkpoints,状态被复制到本地文件。这会引入额外的写入成本并占用本地磁盘空间。对于增量快照,本地状态基于 RocksDB 的原生 checkpointing 机制。 这种机制也被用作创建主副本的第一步,这意味着在这种情况下,创建次要副本不会引入额外的成本。我们只是保留本地 checkpoint 目录, 而不是在上传到分布式存储后将其删除。这个本地副本可以与 RocksDB 的工作目录共享现有文件(通过硬链接),因此对于现有文件,增量快照的 task 本地恢复也不会消耗额外的磁盘空间。 使用硬链接还意味着 RocksDB 目录必须与所有可用于存储本地状态和本地恢复目录位于同一节点上,否则建立硬链接可能会失败(参见 FLINK-10954)。 目前,当 RocksDB 目录配置在多个物理设备上时,这也会阻止使用本地恢复。
十四、Allocation-preserving 调度
Task 本地恢复假设在故障下通过 allocation-preserving 调度 task ,其工作原理如下。 每个 task 都会记住其先前的分配,并请求完全相同的 slot 来重新启动恢复。 如果此 slot 不可用,task 将向 resourcemanager 请求一个 新的 slot。 这样,如果 taskmanager 不再可用,则无法返回其先前位置的 task 不会将其他正在恢复的 task 踢出其之前的 slot。 我们的理由是,只有当 taskmanager 不再可用时,前一个 slot 才会消失,在这种情况下,一些 tasks 无论如何都必须请求新的 slot 。 在我们的调度策略中,我们让绝大多数的 tasks 有机会从它们的本地状态中恢复,从而避免了从其他 tasks 处获取它们之前的 slots 的级联效应。



![[计网01] 物理层 详细解析笔记,特性](https://img-blog.csdnimg.cn/direct/93e31d78ef9a463098704c288688565f.png)