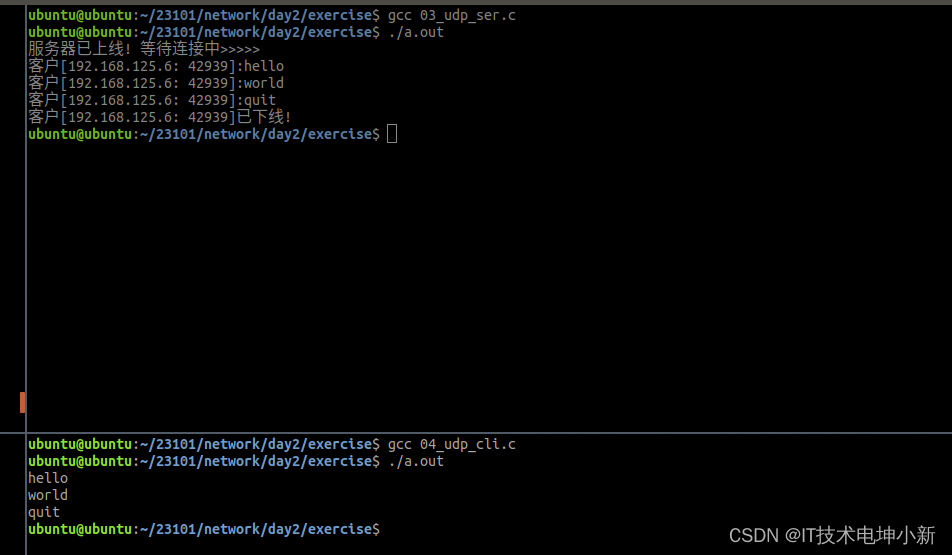
函数引用、匿名函数、lambda表达式、inline函数的理解
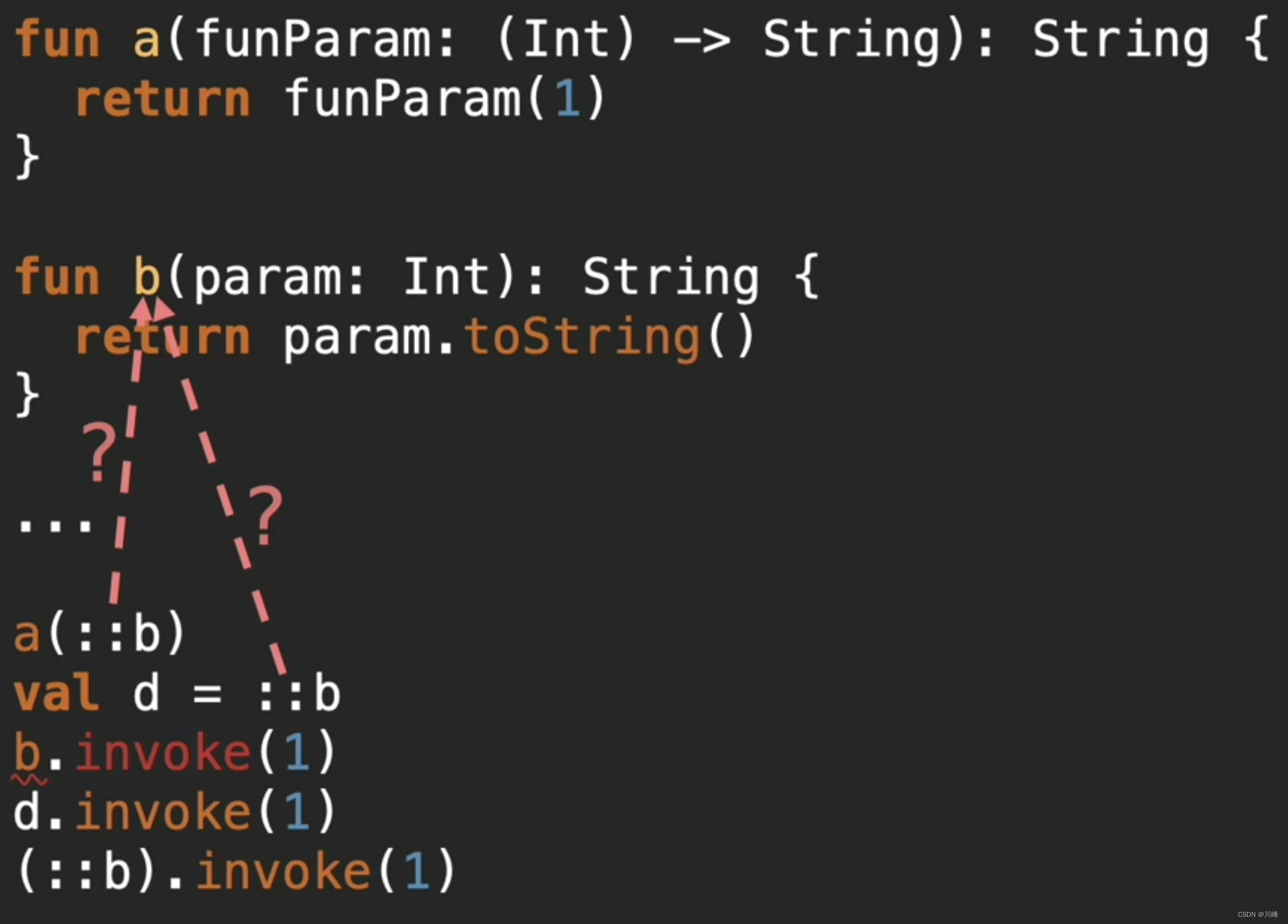
- 双冒号对函数进行引用的本质是生成一个函数对象
- 只有函数对象才拥有
invoke()方法,而函数是没有这个方法的 - kotlin中函数有自己的类型,但是函数本身不是对象,因此要引用函数类型就必须通过双冒号的方式将函数转换成一个对象,这样之后才能拿这个对象进行赋值
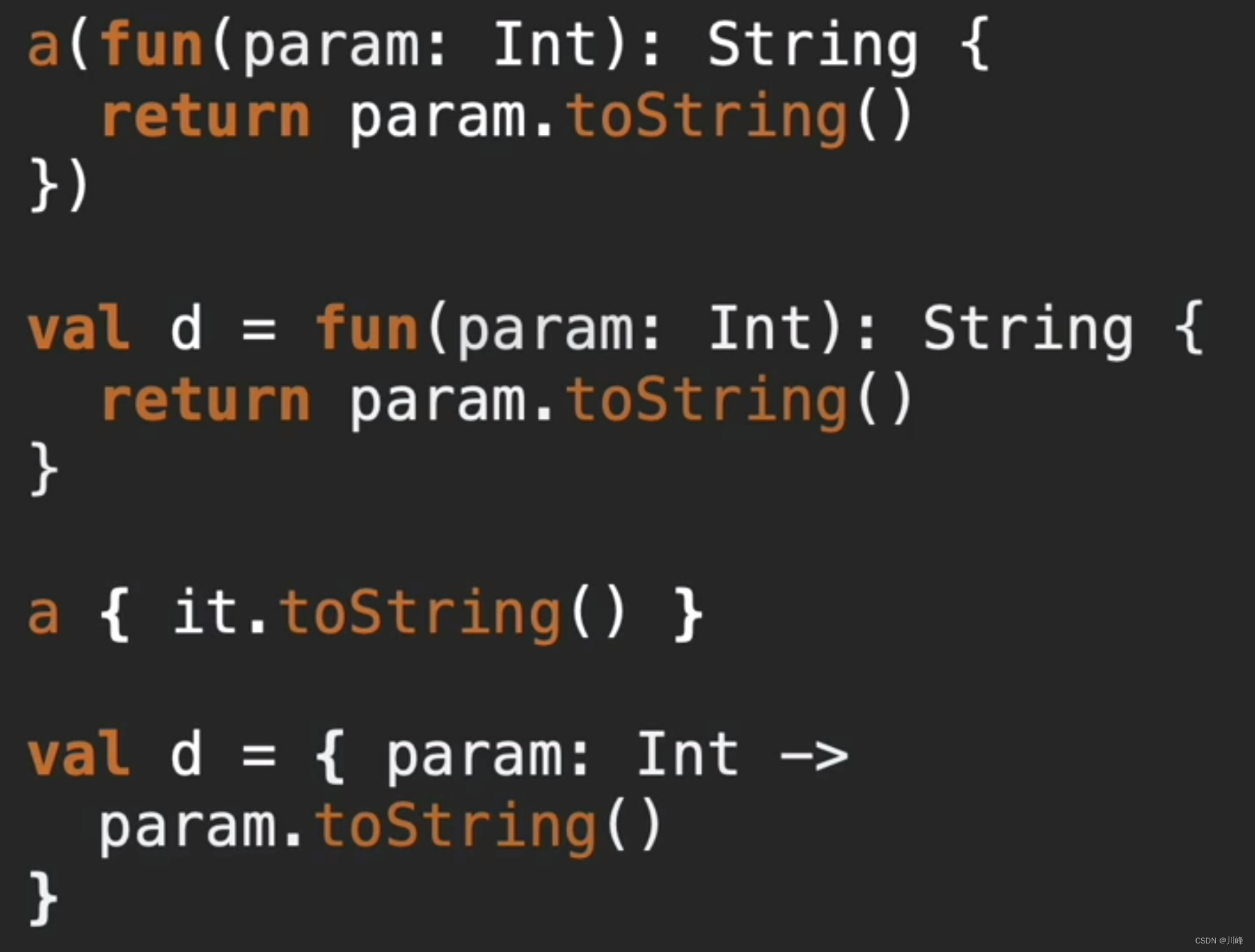
- 匿名函数是一个对象,它不是函数
- 匿名函数跟双冒号引用函数是一种东西
- 而 lambda 表达式是一种特殊的匿名函数对象,它可以省略参数和调用者括号等,更加方便而已
- 因为匿名函数是一个对象,所以它(包括lambda表达式)才可以被当成一个参数传递
- 双冒号函数引用、匿名函数对象、lambda这三者本质都是函数类型的对象
- Java8 中虽然也支持 lambda 方式的写法(SAM 转换),但是 Java8 中的 lambda 和 kotlin 中的 lambda 有本质的区别,一个是编译器的简化写法,一个是函数对象的传递。Java 中即便能写成 lambda 的方式,它也是生成的一个接口类的匿名对象。

- kotlin 中的
const用来声明编译时常量,作用同 java 里的static final,会用字面量直接替换调用处的变量。但它只能写在顶级作用域。
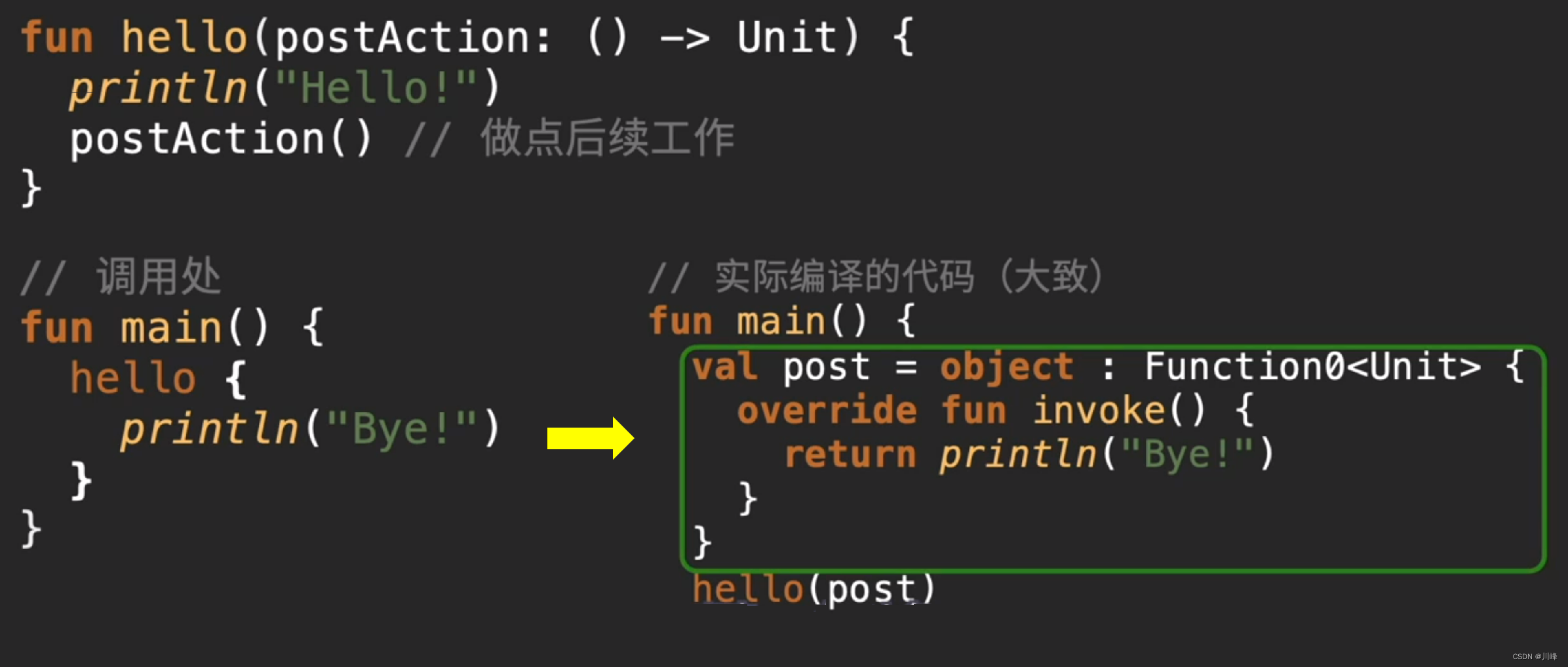

- kotlin中函数对象作为参数传递以后,会创建一个临时对象给真正的函数调用
- 这种函数如果是在
for循环这样的高频调用的场景里,就会因为创建大量的临时对象而导致内存抖动和频繁的GC, 甚至引发OOM
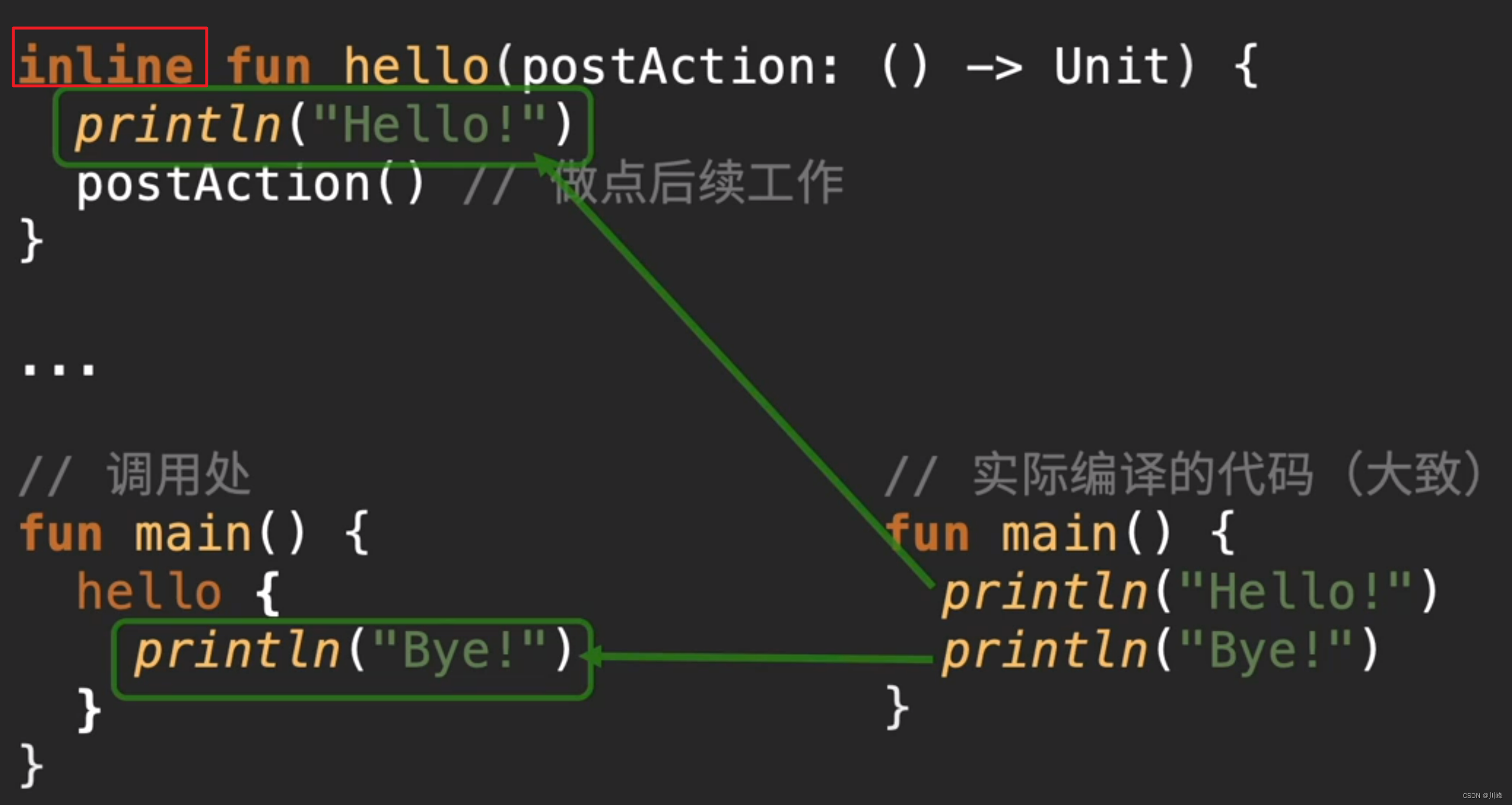
- 如果给函数加上
inline关键字,它会将调用的函数插入到调用处进行平铺展开,这样就可以避免生成临时函数对象带来的影响。所以inline关键字的优化,要是针对高阶函数的。
inline、nolinline、crossinline
- inline:通过内联(即函数内容直插到调用处)的方式来编译函数
- noinline:局部关掉这个优化,来摆脱「不能把函数类型的参数当对象使用」的限制
- crossinline:让内联函数里的函数类型的参数可以被间接调用,代价是不能在 Lambda 表达式里使用
return
noinline 和 crossinline 主要是用来解决加上 inline 之后,可能导致的一些副作用或者附带伤害,进行补救的措施,至于什么时候需要使用它们,不需要记住规则,因为 Android Studio 会在需要的时候提示它。
什么是 SAM 转换
SAM 转换(Single Abstract Method),是针对只有一个方法的接口类的简化写法,例如:
// Single Abstract Method
public interface Listener {void onChanged();
}public class MyView {private Listener mListener;public void setListener(Listener listener) {mListener = listener;}
}
MyView view = new MyView();
view.setListener(new Listener() {@Overridepublic void onChanged() {}
});
如果你写成这种写法,编译器就会提示你可以将其转换成 lambda 表达式(jdk 1.8):
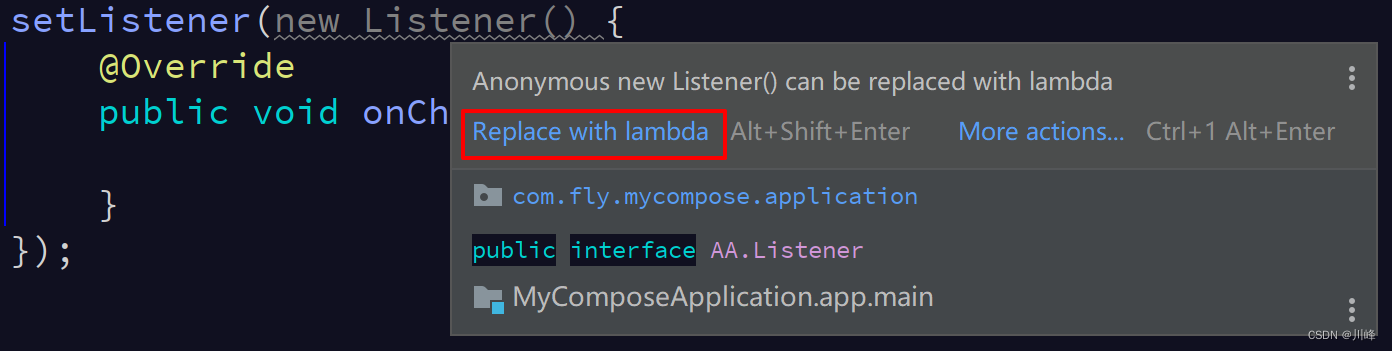
于是代码就可以简化成下面这样:
MyView view = new MyView();
view.setListener(() -> {// todo
});
当然如果是在 kotlin 中调用 java 的这种代码,还可以将小括号去掉,直接调用方法后面跟上 {} 变成更彻底的 lambda 写法。
MyView().setListener { // todo
}
泛型中的 out 与 in
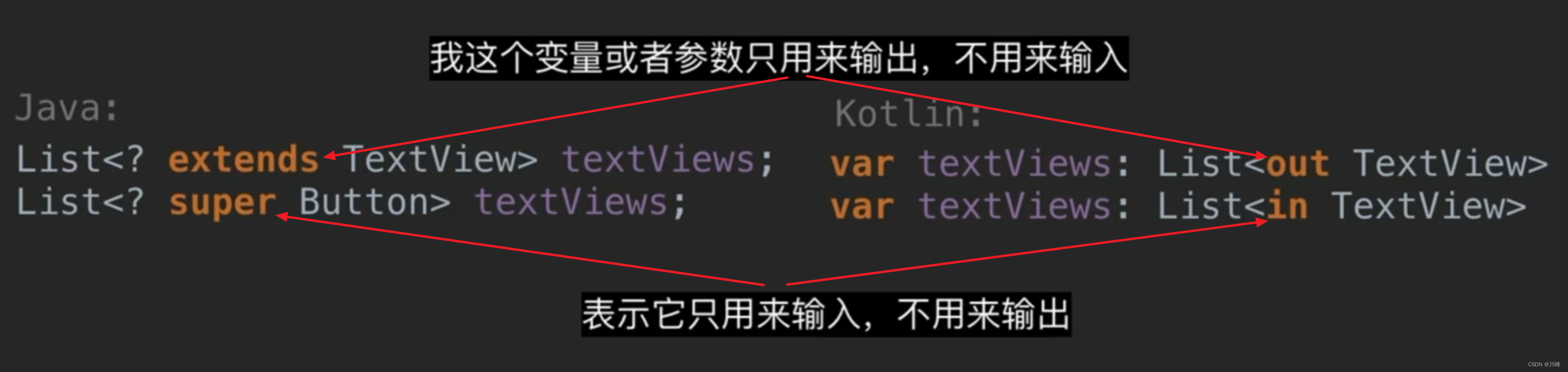
在Kotlin中out代表协变,in代表逆变,为了加深理解我们可以将Kotlin的协变看成Java的上界通配符,将逆变看成Java的下界通配符:
// Kotlin 使用处协变
fun sumOfList(list: List<out Number>)
// Java 上界通配符
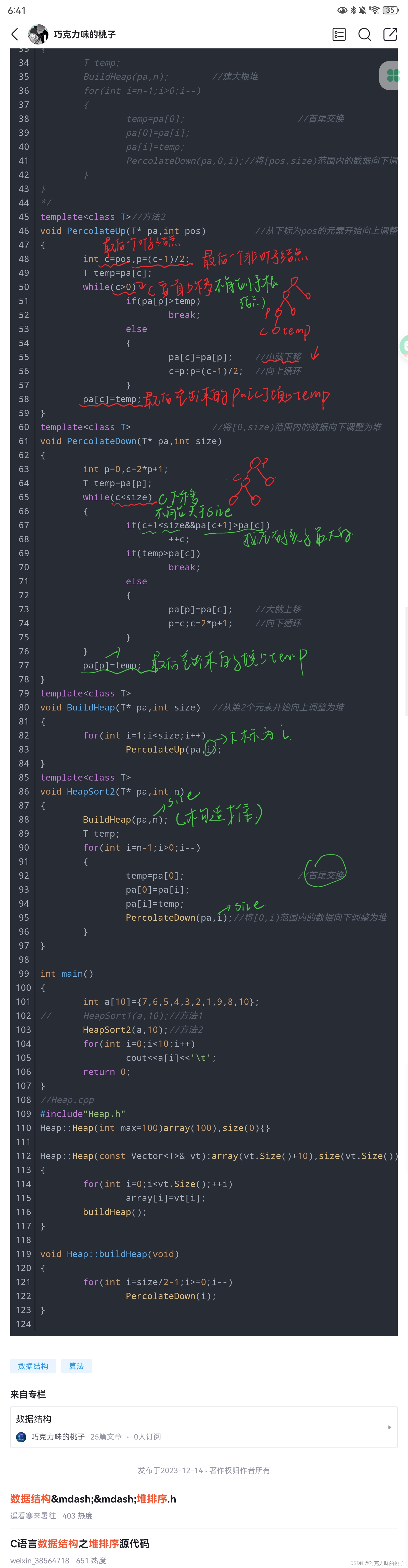
void sumOfList(List<? extends Number> list)
// Kotlin 使用处逆变
fun addNumbers(list: List<in Int>)
// Java 下界通配符
void addNumbers(List<? super Integer> list)
我们知道 Java 的上界通配符和下界通配符主要用于函数的入参和出参,它们俩一个只读,一个只写,而 kotlin 中将这两个分别命名为out和in在含义上更加明确了。
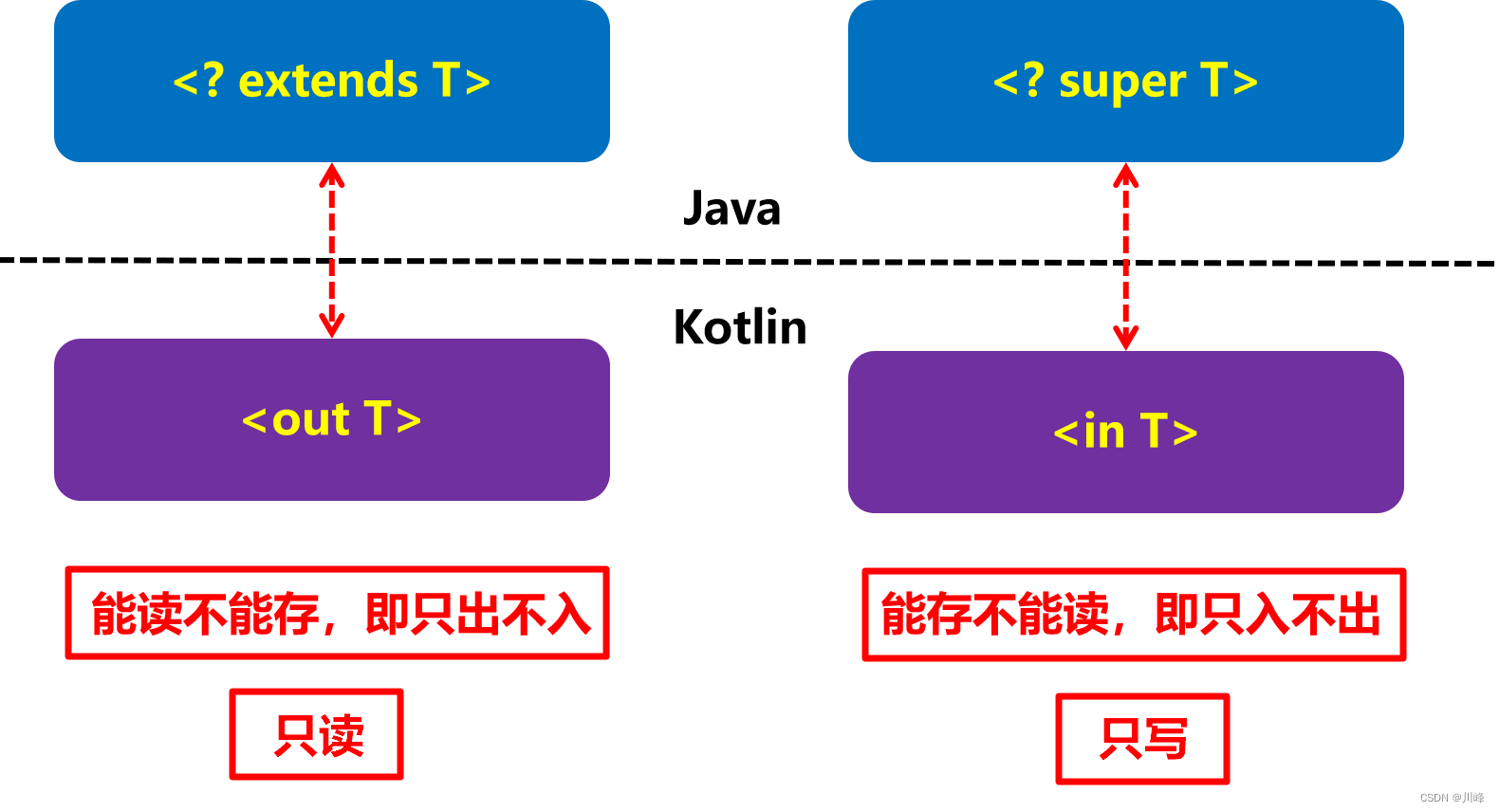

总的来说,Kotlin 泛型更加简洁安全,但是和 Java 一样都是有类型擦除的,都属于编译时泛型。
另外,kotlin 可以直接使用 out 或 in 在类上指定泛型的读写模式,但是 Java 不可以:
// 这个类,就是只能获取,不能修改了
// 声明的时候加入 一劳永逸了 <out T>
class Worker<out T> {// 能获取fun getData(): T? = null// 不能修改/* * fun setData(data: T) { }* fun addData(data: T) { }*/
}
// 这个类,就是只能修改,不能获取
// 声明的时候加入 一劳永逸了 <in T>
class Student<in T> {/* fun a(list: Mutablelist<in T>) **/fun setData(data: T) {}fun addData(data: T) {}// 不能获取// fun getData() : T
}
// Java 不允许你在声明方向的时候,控制读写模式
public class Student /*<? super T>*/ { }

- 类上的泛型
T前面的out或in关键字作用于整个类范围所有使用该泛型的地方。 - Kotlin 为什么这样设计:它表示所有使用
T的场景都是只用来输出,或者只用来输入的,那么为了避免我在每个使用的位置都给变量或者参数写上out这么麻烦,就干脆直接声明在了类上面。 - 什么时候该用
out或in:这是一个设计问题,类的设计者需要考虑这个类的职责,是否是只用于生产或者只用于消费的。
在类上使用 out 或 in 时赋值的区别:
- 子类泛型对象可以赋值给父类泛型对象,用
out - 父类泛型对象可以赋值给子类泛型对象,用
in
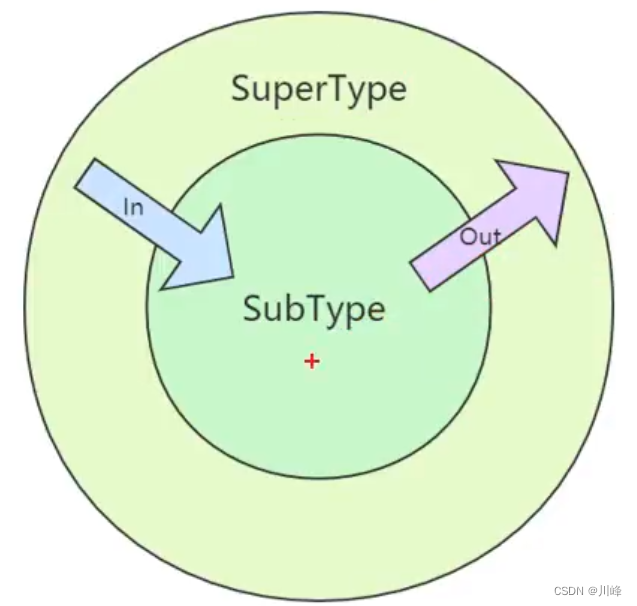
// 子类泛型对象可以赋值给父类泛型对象,用 out
val production1: Producer<Food> = FoodStore()
val production2: Producer<Food> = FastFoodStore()
val production3: Producer<Food>= BurgerStore()
// 父类泛型对象可以赋值给子类泛型对象,用 in
val consumer1: Consumer<Burger> = Everybody()
val consumer2: Consumer<Burger> = ModernPeople()
val consumer3: Consumer<Burger> = American()
这赋值这一点上, 使用 out 和 in 与 Java 的上界通配符和下界通配符是一样的行为。
Kotlin 泛型中的 * 相当于Java 泛型中的 ?:

Java 和 Kotlin 中类的泛型参数有多继承的区别:
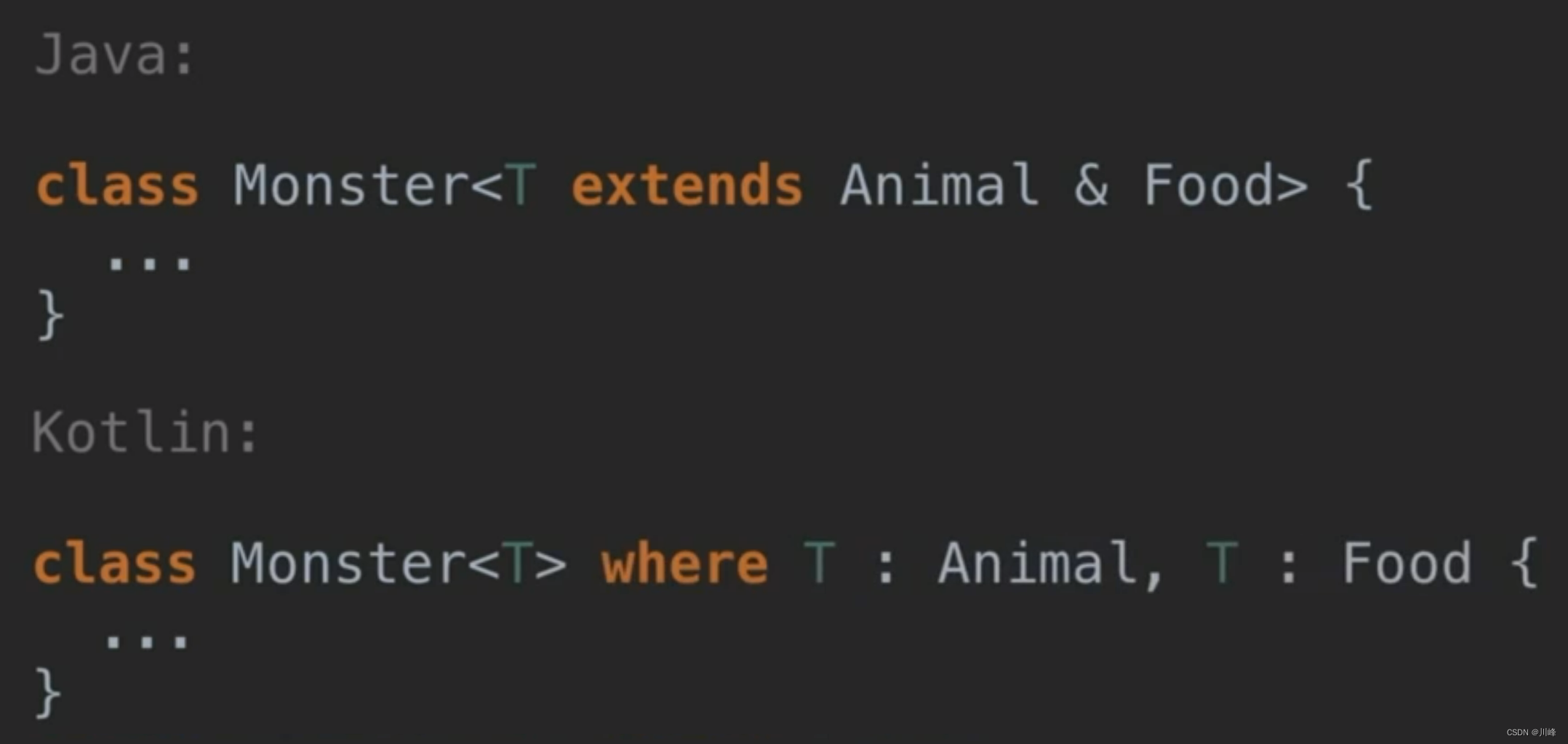
Kotlin 泛型方法示例:
fun <T> instanceRetrofit(apiInterface: Class<T>) : T {// OKHttpClient 用于请求服务器val mOkHttpClient = OkHttpClient().newBuilder() .readTimeout(10000, TimeUnit.SECONDS) // 添加读取超时时间 .connectTimeout(10000, TimeUnit.SECONDS) // 添加连接超时时间 .writeTimeout(10000, TimeUnit.SECONDS) // 添加写出超时时间.build()val retrofit: Retrofit = Retrofit.Builder().client(mOkHttpClient) // 请求方,处理响应方.addCallAdapterFactory(RxJava2CallAdapterFactory.create()) // 使用 RxJava 处理响应.addConverterFactory(GsonConverterFactory.create()) // 使用 Gson 解析 JavaBean.build()return retrofit.create(apiInterface)
}
简单总结一下:
kotlin的 out in 和 Java 的<? extends T> 和 <? super T> 虽然含义是一样的,但是写法上有点不同:
- Java 的上界通配符和下界通配符只能用作方法的参数,用于入参和出参的作用,不能直接写到类上面。
- kotlin 中的
outin可以直接写到类上面,直接表明整个类中使用到泛型T的地方都具备这个含义。 - 当在类上面声明泛型
T为out时,表示T只能从当前类中输出,而不能输入。 - 当在类上面声明泛型
T为in时,表示T只能从当前类中输入,而不能输出。
Kotlin 标准库中的常用扩展函数 apply、also、run、let
使用时可以通过简单的规则作出一些判断:
- 需要返回自身 -> 从
apply和also中选- 作用域中使用
this作为参数 ----> 选择apply - 作用域中使用
it作为参数 ----> 选择also
- 作用域中使用
- 不需要返回自身 -> 从
run和let中选择- 作用域中使用
this作为参数 ----> 选择run - 作用域中使用
it作为参数 ----> 选择let
- 作用域中使用
apply适合对一个对象做附加操作的时候let适合配合判空的时候 (最好是成员变量,而不是局部变量,局部变量更适合用if)with适合对同一个对象进行多次操作的时候
apply VS also
apply 和 also 的返回值都是当前调用者的对象,也就是 T 类型的当前实例:
public inline fun <T> T.apply(block: T.() -> Unit): T { block()return this
}
public inline fun <T> T.also(block: (T) -> Unit): T { block(this)return this
}
这俩同是当前调用者 T 类型的扩展函数,但是 apply 中的 block 同时也是当前调用者 T 类型的扩展函数,所以其 lambda 中可以使用 this 访问当前对象,而 also 中的 block 只是一个普通的函数,不过这个普通函数的参数传入的是当前对象,所以其 lambda 中只能用 it 访问当前对象。
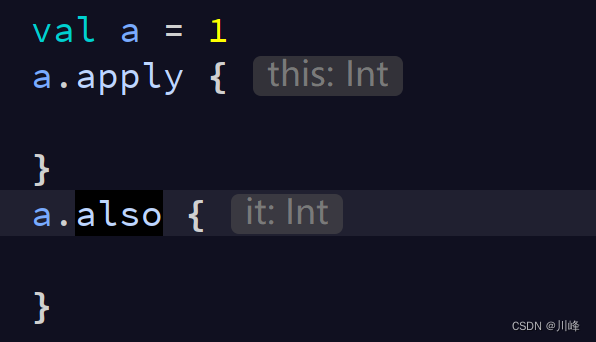
apply 常用于创建对象实例后,马上对其进行一些操作调用:
ArrayList<String>().apply { add( "testApply")add("testApply") add( "testApply") println("$this")
}.also { println(it)
}
let VS run
let 和 run 的返回值都是 block 的返回值,即 lambda 表达式的返回值:
public inline fun <T, R> T.let(block: (T) -> R): R { return block(this)
}
public inline fun <T, R> T.run(block: T.() -> R): R { return block()
}
这俩同是当前调用者 T 类型的扩展函数,但是 run 中的 block 同时也是当前调用者 T 类型的扩展函数,所以其 lambda 中可以使用 this 访问当前对象,而 let 中的 block 只是一个普通的函数,不过这个普通函数的参数传入的是当前对象,所以其 lambda 中只能用 it 访问当前的对象。
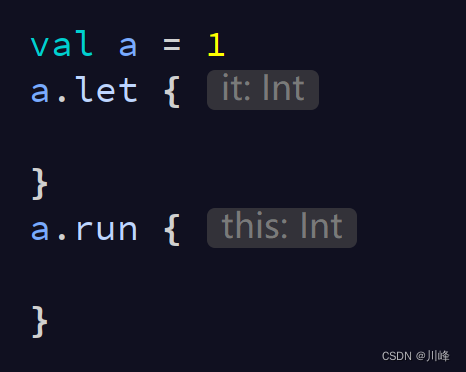
let 比较常用的一个操作是判空操作:
// 避免为 nu1ll 的操作
str?.let {println(it.length)
}
object 单例
我们知道 object 就是 kotlin 中天生的单例模式,我们看一下它翻译成 Java 代码是什么样的:
object Singleton {var x: Int = 2 fun y() { }
}
上面代码编译成Java字节码后反编译对应如下代码:
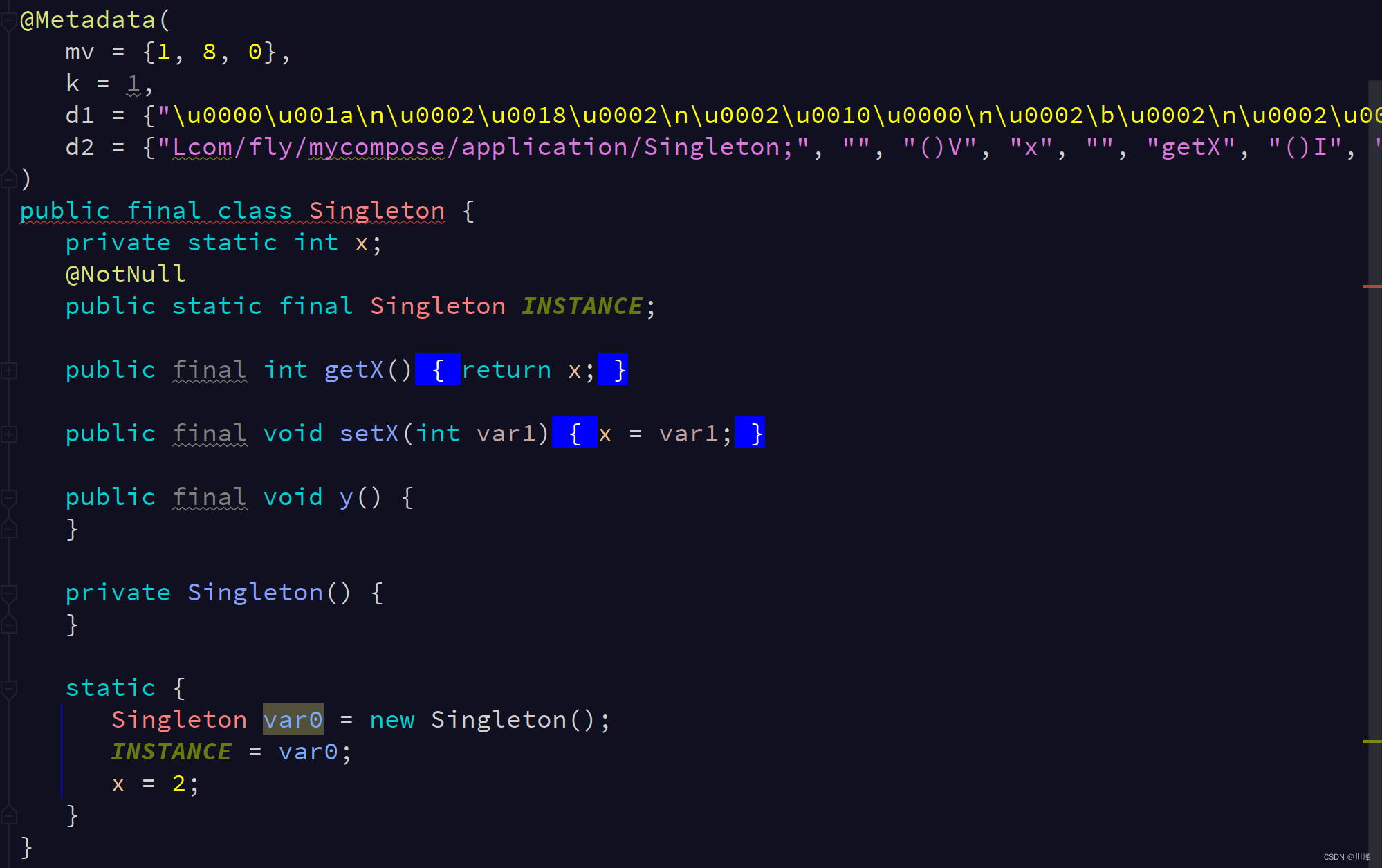
其实它就是恶汉模式的单例。
如果是一个普通类想生成单例,可以使用伴生对象 companion object 来生成:
class Singleton {companion object {var x: Int = 2fun y() { }}
}
上面代码翻译成 Java 后长下面这样:
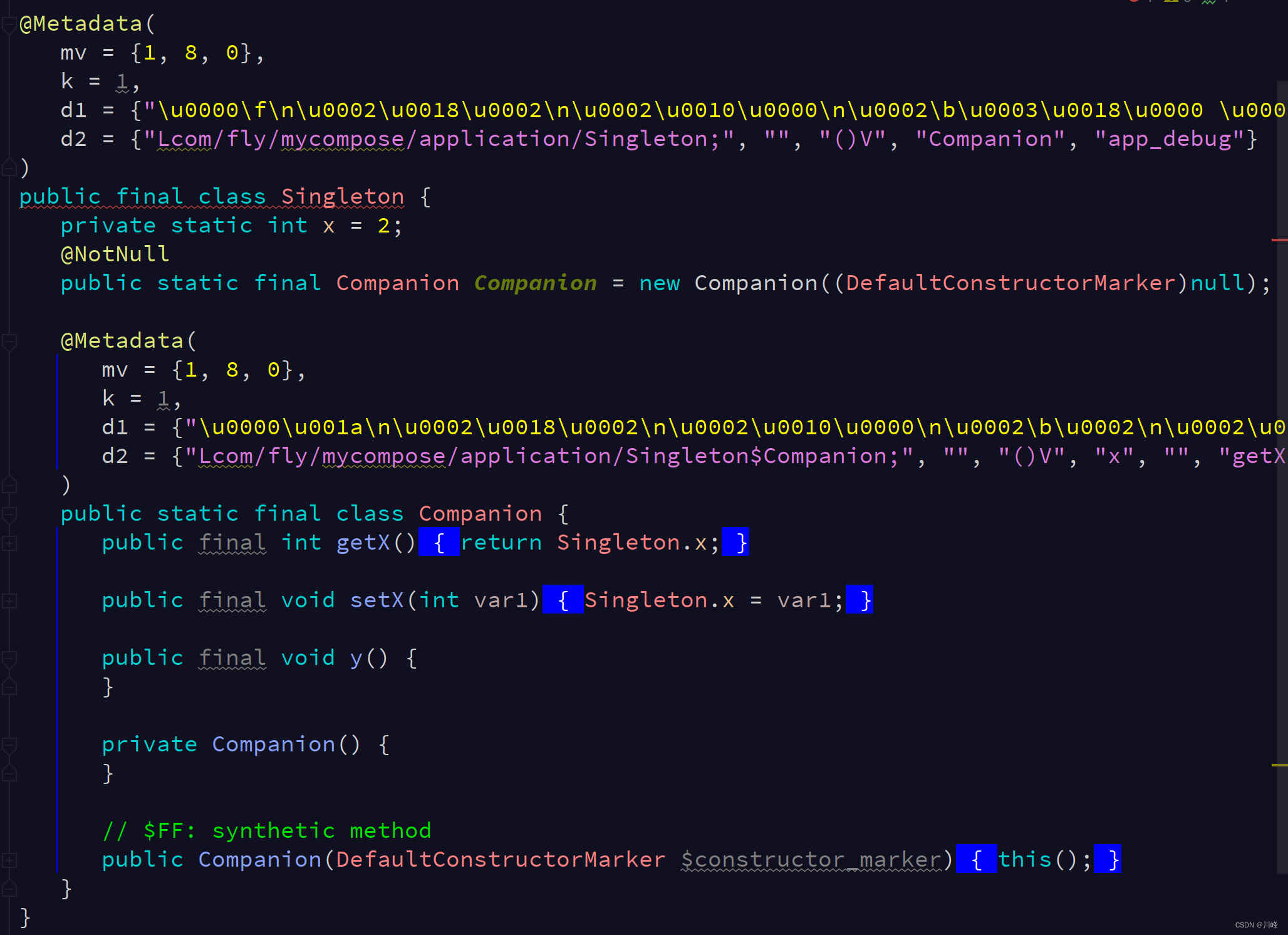
我们看到它还是一个恶汉模式的单例,只不过这个恶汉的对象实例是一个名为 Companion 的静态内部类的实例对象。另外,只有 companion object 中的成员属性是放到外部类中的,而 companion object 中的成员方法是放在静态内部类中的。
如果要实现 Java 中静态内部类版本的单例模式:
public class Singleton {private Singleton() {}private static class SingletonHolder {/** 静态初始化器,由 JVM 类加载过程来保证线程安全 */private static Singleton instance = new Singleton();}public static Singleton getInstance() {return SingletonHolder.instance;}
}
可以像下面这样写:
class Singleton private constructor() {private object Holder {val INSTANCE = Singleton()}companion object {val instance = Holder.INSTANCE}
}
Kotlin 中很没用的两个东西 Nothing 与 Unit
之所以说这两个东西没啥用,是因为这两个相当于是用来进行标记、提示之类的作用;只能说它们的实际用处不是那么大,但是用来标记和提醒比较方便。
比如在 Java 中,各种源码中可以看到类似下面的写法:
/**
* 当遇到姓名为空的时候,请调用这个函数来抛异常
* @return throw NullPointerException
*/
public String throwOnNameNull() {throw new NullPointerException("姓名不能为空!");
}
对应到 Kotlin 的等价写法:
/*** 当遇到姓名为空的时候,请调用这个函数来抛异常*/
fun throwOnNameNull() : String {throw NullPointerException("姓名不能为空!")
}
这个函数的主要作用是用来抛出一个异常,但是如果这么写会让人很困惑,明明只是抛出异常,返回值却是一个String,所以这个时候可以用 Unit 或者 Nothing 代替它:
/*** 当遇到姓名为空的时候,请调用这个函数来抛异常*/
fun throwOnNameNull() : Nothing {throw NullPointerException("姓名不能为空!")
}
这样开发者在看到这个函数时,就会知道,它什么也不会返回。就是一个提醒的作用。
Nothing 还可以用作泛型实参,以起到一个空白占位符的作用,例如:
val emptyList: List<Nothing> = listOf()
var apples: List<Apple> = emptyList
var users: List<User> = emptyList
var phones: List<Phone> = emptyList
var images: List<Image> = emptyList val emptySet: Set<Nothing> = setOf()
var apples: Set<Apple> = emptySet
var users: Set<User> = emptySet
var phones: Set<Phone> = emptySet
var images: Set<Image> = emptySet val emptyMap: Map<String, Nothing> = emptyMap()
var apples: Map<String, Apple> = emptyMap
var users: Map<String, User> = emptyMap
var phones: Map<String, Phone> = emptyMap
var images: Map<String, Image> = emptyMap
val emptyProducer: Producer<Nothing> = Producer()
var appleProducer: Producer<Apple> = emptyProducer
var userProducer: Producer<User> = emptyProducer
var phoneProducer: Producer<Phone> = emptyProducer
var imageProducer: Producer<Image> = emptyProducer
这样写唯一的好处就是,简单方便,节省内存。
Nothing 还有一个作用就是当你不知道返回什么的时候,就可以返回它,例如:
fun sayMyName(first: String, second: String) {val name = if (first == "Walter" && second == "White") { "Heisenberg"} else {return // 语法层面的返回值类型为 Nothing,赋值给 name }println(name)
}
这里虽然没有显示的写出来,但是在语法层面这里的 return 返回的就是 Nothing。
对于 Unit,它主要用来对标 Java 中的 void 关键字,表示什么也不返回,即返回空。为什么要设计一个这个呢,直接使用 void 不就行了吗?这是因为 Java 中的 void 关键字,虽然表示返回空,但是它不是一个实际的类型,在某些地方,你就不能用它来作为一个类型去表达“什么也不返回”的含义,例如最常见的例子就是以前开发中经常使用的 AsyncTask:
class BackgroundTask extends AsyncTask<String, Void, Void> {@Overrideprotected Void doInBackground(String... strings) {// do somethingreturn null;}@Overrideprotected void onProgressUpdate(Void[] values) {super.onProgressUpdate(values);}@Overrideprotected void onPostExecute(Void o) {}
}
回忆一下AsyncTask的三个泛型参数:public abstract class AsyncTask<Params, Progress, Result>
Params:doInBackground方法的接受参数类型Progress:onProgressUpdate方法的接受参数类型Result:onPostExecute方法的接受参数类型,以及doInBackground方法的返回参数类型
在上面代码中,由于void是一个关键字,而不是一个类型,所以不能用于泛型的位置作为实参,所以就会出现很尴尬的场景,我们必须再造一个类似于void关键字的类型,也就是大写的 Void(它其实是一个类),并且上面代码中,我们看到 doInBackground 方法的返回参数类型是 Void,但实际上是 return 了一个 null,而且你不写这个 null 又不行编译不过。这就令人非常尴尬了。
为了避免这种令人尴尬的场景,kotlin 就干脆直接定义了一个 Unit 类型来代表这种 Void,它是一个实际的类型,你可以用它来定义变量,它也可以出现在任何需要类型的地方。

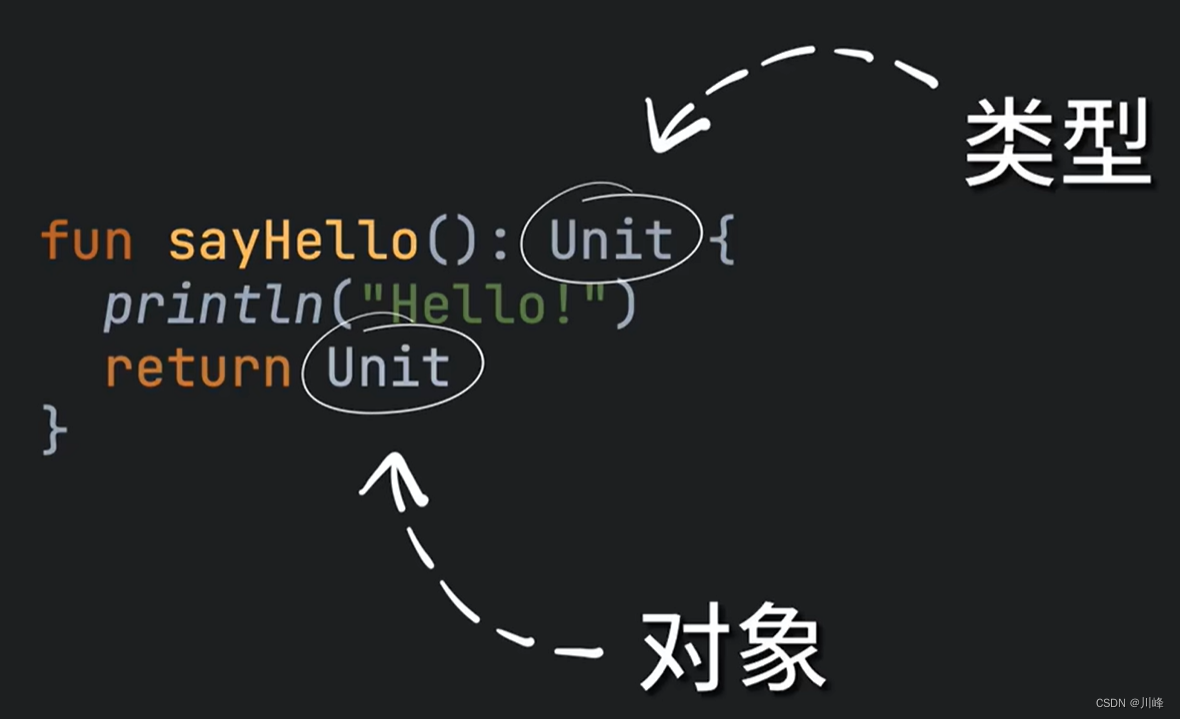
但是 Kotlin 中一般函数没有返回值时,我们可以省略写这个 Unit。
Unit 更常见的身影是 lambda 表达式以及高阶函数的参数定义中,例如:
fun foo(block : (Int, String) -> Unit) : Unit {return block(123, "hello")
}
val sum : (Int, Int) -> Unit = { x, y -> x + y }
fun main() {val a = sum(1, 2)
}
确切的说,在 Kotlin 中它的主要用途是用来表达函数类型,因为如果只是一个关键字的话,而不是一个类型,那么你就无法把它在需要表达函数类型的地方写出来。
关于 Unit 另外一个比较常见的场景是在 Jetpack Compose 的副作用 API 中的使用,例如:
LaunchedEffect(Unit) {...
}
这种写法显得比较奇怪,但是看一眼 Unit 的源码就明白了:
/*** The type with only one value: the `Unit` object. This type corresponds to the `void` type in Java.*/
public object Unit {override fun toString() = "kotlin.Unit"
}
我们发现它就是一个 object 单例,而 object 对应到 Java 中就是一个 final 类,因此 object 单例在运行时是不变的,它就是一个常量。
所以LaunchedEffect(Unit)也可以写成LaunchedEffect(1)、LaunchedEffect(2)、LaunchedEffect("aaa")、LaunchedEffect(true)都可以,只不过你想不到写啥的时候,直接写 Unit 会更方便。
接口代理 by
它跟代理模式差不多,但是有一点不同的 kotlin 的 by 更多的是将一个接口的实现委托给一个实现类对象。
比如 Android 中的 ContextWrapper 就是将对 Context 的操作全部都委托给了内部一个叫做 mBase 的 Context 成员对象去处理:
public class ContextWrapper extends Context {Context mBase;public ContextWrapper(Context base) { mBase = base; }@Overridepublic AssetManager getAssets() {return mBase.getAssets(); }@Overridepublic Resources getResources() {return mBase.getResources(); }@Overridepublic PackageManager getPackageManager() {return mBase.getPackageManager(); }@Overridepublic ContentResolver getContentResolver() { return mBase.getContentResolver(); }...
}
再比如我想定制一个类型是 User 的 List 对象,实现按年龄排序之类的需求,可以这样写:
class UserList implements List<User> {List<User> userList;public UserList(List<User> userList) { this.userList = userList; } public List<User> higherRiskUsers() { ...}public void sortWithAge() { ...} @Overridepublic int size() { return 0; } @Overridepublic boolean isEmpty() { return false;} @Overridepublic boolean contains(@Nullable Object o) { return false;}......
}
这样就是将对 List的操作委托给了内部的userList去操作,你可以传入一个ArrayList或者一个LinkedList的实现给它。
但是这样写的话,我们发现里面多了很多不需要但是不得不写的方法,例如size()、isEmpty()等等,如果使用 Kotlin 的 by 关键字进行委托,就会简化很多,例如:
class UserList(private val list: List<User>): List<User> by list {public List<User> higherRiskUsers() { ...}public void sortWithAge() { ...}
}
这样那些不得不写但又没有营养的方法,我们就可以不用手动去写了,而是交给构造函数中传入的 list 参数的实现类实例对象去自动实现这些方法。我们只需要关心在这个类中,如何实现真正需要添加的业务方法即可。
总结一下它的语法就是:
class 类名(val 实际接口的实现者[a] : 接口类) : 接口类 by [a] {}
其中 a 传入的就是要实现的接口的实际实现对象实例。
当然在使用 by 关键字也可以不完全委托给构造函数传入的实例对象,如果在类中覆写了所实现接口的某个方法,就会以你覆写的为准,而不是交给委托的对象,这一点比较灵活。
比如 Kotlin 的协程源码中有一个叫 SubscribedSharedFlow 就是对 SharedFlow 进行了委托,但是它没有完全委托给构造函数传入的sharedFlow对象,而是重写了SharedFlow接口的 collect 方法:
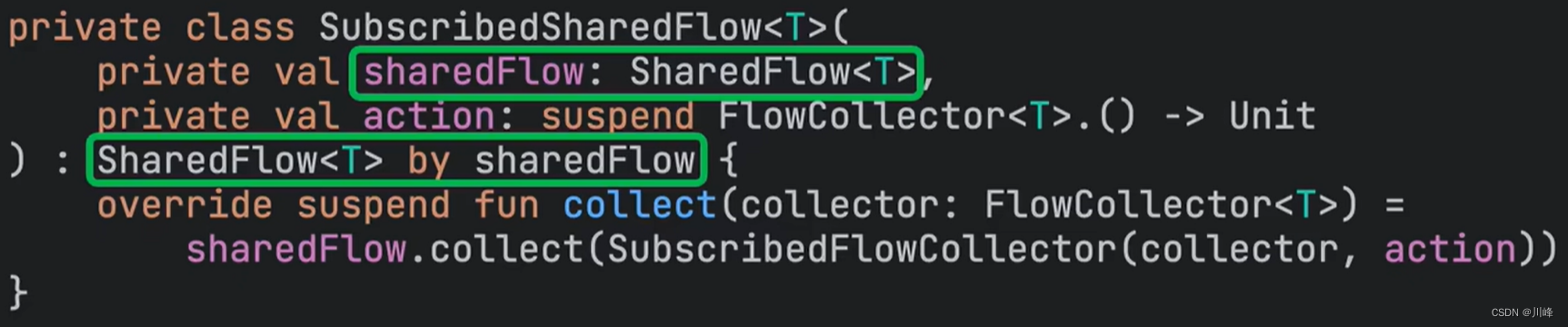
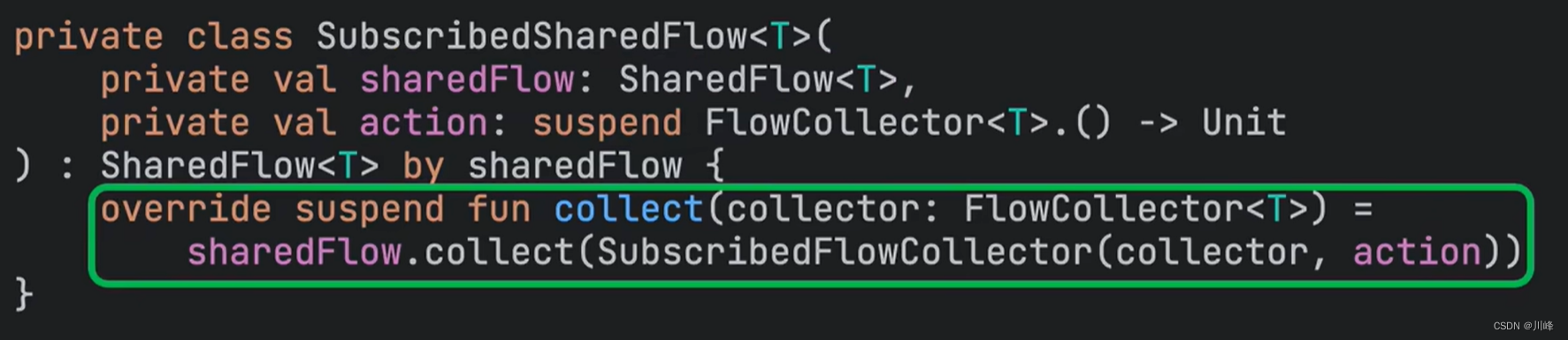
通过这种 方式我们可以进行某种“局部定制”功能,这个感觉有点类似 Java 里面你继承一个父类抽象类,但是懒于实现其每个抽象方法,但是又想在需要的时候自由覆盖其某个抽象方法,kotlin一个by关键字解决了这个麻烦。