文章目录
- 网关端服务探活
- admin端服务探活
Shenyu HTTP服务探活是一种用于检测HTTP服务是否正常运行的机制。它通过建立Socket连接来判断服务是否可用。当服务不可用时,将服务从可用列表中移除。
网关端服务探活
以divide插件为例,看下divide插件是如何获取服务实例来发起调用的
public class DividePlugin extends AbstractShenyuPlugin {@Overrideprotected Mono<Void> doExecute(final ServerWebExchange exchange, final ShenyuPluginChain chain, final SelectorData selector, final RuleData rule) {ShenyuContext shenyuContext = exchange.getAttribute(Constants.CONTEXT);assert shenyuContext != null;// 获取规则的handle属性,即负载均衡策略,重试策略,超时时间等DivideRuleHandle ruleHandle = buildRuleHandle(rule);// 请求头大小校验if (ruleHandle.getHeaderMaxSize() > 0) {long headerSize = exchange.getRequest().getHeaders().values().stream().flatMap(Collection::stream).mapToLong(header -> header.getBytes(StandardCharsets.UTF_8).length).sum();if (headerSize > ruleHandle.getHeaderMaxSize()) {LOG.error("request header is too large");Object error = ShenyuResultWrap.error(exchange, ShenyuResultEnum.REQUEST_HEADER_TOO_LARGE);return WebFluxResultUtils.result(exchange, error);}}// request大小校验if (ruleHandle.getRequestMaxSize() > 0) {if (exchange.getRequest().getHeaders().getContentLength() > ruleHandle.getRequestMaxSize()) {LOG.error("request entity is too large");Object error = ShenyuResultWrap.error(exchange, ShenyuResultEnum.REQUEST_ENTITY_TOO_LARGE);return WebFluxResultUtils.result(exchange, error);}}// 获取后端服务列表List<Upstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());if (CollectionUtils.isEmpty(upstreamList)) {LOG.error("divide upstream configuration error: {}", selector);Object error = ShenyuResultWrap.error(exchange, ShenyuResultEnum.CANNOT_FIND_HEALTHY_UPSTREAM_URL);return WebFluxResultUtils.result(exchange, error);}// 请求IPString ip = Objects.requireNonNull(exchange.getRequest().getRemoteAddress()).getAddress().getHostAddress();// 根据负载均衡从服务列表中选择一个服务实例Upstream upstream = LoadBalancerFactory.selector(upstreamList, ruleHandle.getLoadBalance(), ip);if (Objects.isNull(upstream)) {LOG.error("divide has no upstream");Object error = ShenyuResultWrap.error(exchange, ShenyuResultEnum.CANNOT_FIND_HEALTHY_UPSTREAM_URL);return WebFluxResultUtils.result(exchange, error);}// set the http urlif (CollectionUtils.isNotEmpty(exchange.getRequest().getHeaders().get(Constants.SPECIFY_DOMAIN))) {upstream.setUrl(exchange.getRequest().getHeaders().get(Constants.SPECIFY_DOMAIN).get(0));}// set domainString domain = upstream.buildDomain();exchange.getAttributes().put(Constants.HTTP_DOMAIN, domain);// 设置http超时时间exchange.getAttributes().put(Constants.HTTP_TIME_OUT, ruleHandle.getTimeout());// 设置重试次数exchange.getAttributes().put(Constants.HTTP_RETRY, ruleHandle.getRetry());// 设置重试策略exchange.getAttributes().put(Constants.RETRY_STRATEGY, StringUtils.defaultString(ruleHandle.getRetryStrategy(), RetryEnum.CURRENT.getName()));// 设置负载均衡策略exchange.getAttributes().put(Constants.LOAD_BALANCE, StringUtils.defaultString(ruleHandle.getLoadBalance(), LoadBalanceEnum.RANDOM.getName()));// 设置当前选择器idexchange.getAttributes().put(Constants.DIVIDE_SELECTOR_ID, selector.getId());if (ruleHandle.getLoadBalance().equals(P2C)) {// 使用P2C负载均衡策略的逻辑return chain.execute(exchange).doOnSuccess(e -> responseTrigger(upstream)).doOnError(throwable -> responseTrigger(upstream));} else if (ruleHandle.getLoadBalance().equals(SHORTEST_RESPONSE)) {// 使用shortestResponse最短响应时间的负载均衡策略的逻辑beginTime = System.currentTimeMillis();return chain.execute(exchange).doOnSuccess(e -> successResponseTrigger(upstream));}// 执行下一个插件return chain.execute(exchange);}}
在divide插件中,通过UpstreamCacheManager获取服务列表
List<Upstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());
UpstreamCacheManager中的UpstreamCheckTask属性缓存了所有的上游服务列表,包括健康的以及不健康的
public final class UpstreamCacheManager {private UpstreamCheckTask task;public List<Upstream> findUpstreamListBySelectorId(final String selectorId) {return task.getHealthyUpstream().get(selectorId);}// ...
}
public final class UpstreamCheckTask implements Runnable {private final Map<String /* 选择器id */, List<Upstream>> healthyUpstream = Maps.newConcurrentMap();private final Map<String /* 选择器id */, List<Upstream>> unhealthyUpstream = Maps.newConcurrentMap();
}
那这个服务列表是如何更新的呢?我们先从UpstreamCacheManager构造方法开始看起
private void scheduleHealthCheck() {// 默认是关闭的if (checkEnable) {// 开启任务task.schedule();// executor for log printif (printEnable) {ThreadFactory printFactory = ShenyuThreadFactory.create("upstream-health-print", true);new ScheduledThreadPoolExecutor(1, printFactory).scheduleWithFixedDelay(task::print, printInterval, printInterval, TimeUnit.MILLISECONDS);}}
}
checkEnable参数默认是false,说明网关默认情况下是不会主动去探活来更新服务列表,需要由admin端同步过来。
如果有需要,可以在网关配置文件中手动配置shenyu.upstreamCheck.enabled=true开启服务探活
shenyu:upstreamCheck:enabled: true
然后调用UpstreamCheckTask的schedule方法
public final class UpstreamCheckTask implements Runnable {//...public void schedule() {// 健康检查任务的线程池ThreadFactory healthCheckFactory = ShenyuThreadFactory.create("upstream-health-check", true);// 开启检查任务new ScheduledThreadPoolExecutor(1, healthCheckFactory).scheduleWithFixedDelay(this, 3000, checkInterval, TimeUnit.MILLISECONDS);// 健康 检查任务中发送socket请求的线程池// 向上游服务尝试发送socket请求也是通过线程池,防止请求阻塞住健康检查任务线程ThreadFactory requestFactory = ShenyuThreadFactory.create("upstream-health-check-request", true);executor = new ScheduledThreadPoolExecutor(poolSize, requestFactory);}
}
创建一个只有一个核心线程的线程池,任务就是当前对象,每隔10s执行一次,执行逻辑就是run方法中
@Override
public void run() {// 健康检查healthCheck();
}private void healthCheck() {try {/** 如果这里没有锁,当检查结束并且所有检查结果都在futures列表中,* 与此同时,删除选择器,triggerRemoveAll()方法在waitFinish()方法之前被调用,服务列表删除,* 然后waitFinish()方法执行,又会把服务重新添加到服务列表中,造成脏数据*/synchronized (lock) {if (tryStartHealthCheck()) {// 并发执行检查doHealthCheck();// 等待检查完成,将连通的服务放到健康列表中,将不连通的放到不健康列表中waitFinish();}}} catch (Exception e) {LOG.error("[Health Check] Meet problem: ", e);} finally {finishHealthCheck();}
}
这里主要就是分为两步:
- 真正执行健康检查操作。
- 等待全部检查完成后处理检查结果。
private void doHealthCheck() {// 检查健康列表check(healthyUpstream);// 检查不健康列表check(unhealthyUpstream);
}
因为维护了两个列表,一个是健康的,一个是暂时不健康的,需要分别两个列表进行检查,两个检查都是调用check方法
private void check(final Map<String, List<Upstream>> map) {for (Map.Entry<String, List<Upstream>> entry : map.entrySet()) {String key = entry.getKey();List<Upstream> value = entry.getValue();for (Upstream upstream : value) {// 异步执行检查,多个服务实例并发检查CompletableFuture<UpstreamWithSelectorId> future = CompletableFuture.supplyAsync(() -> check(key, upstream), executor);futures.add(future);}}
}private UpstreamWithSelectorId check(final String selectorId, final Upstream upstream) {// 测试能否连通boolean pass = UpstreamCheckUtils.checkUrl(upstream.getUrl(), checkTimeout);if (pass) {if (upstream.isHealthy()) {// 服务连通并且原先也是健康的,只更新上次健康时间为当前时间即可upstream.setLastHealthTimestamp(System.currentTimeMillis());} else {// 服务从下线状态变更为上线状态long now = System.currentTimeMillis();long interval = now - upstream.getLastUnhealthyTimestamp();if (interval >= (long) checkInterval * healthyThreshold) {upstream.setHealthy(true);upstream.setLastHealthTimestamp(now);LOG.info("[Health Check] Selector [{}] upstream {} health check passed, server is back online.",selectorId, upstream.getUrl());}}} else {if (!upstream.isHealthy()) {// 服务不连通并且原先也是不健康的,只更新上次不健康时间为当前时间即可upstream.setLastUnhealthyTimestamp(System.currentTimeMillis());} else {// 服务下线了long now = System.currentTimeMillis();long interval = now - upstream.getLastHealthTimestamp();if (interval >= (long) checkInterval * unhealthyThreshold) {upstream.setHealthy(false);upstream.setLastUnhealthyTimestamp(now);LOG.info("[Health Check] Selector [{}] upstream {} health check failed, server is offline.",selectorId, upstream.getUrl());}}}return new UpstreamWithSelectorId(selectorId, upstream);
}
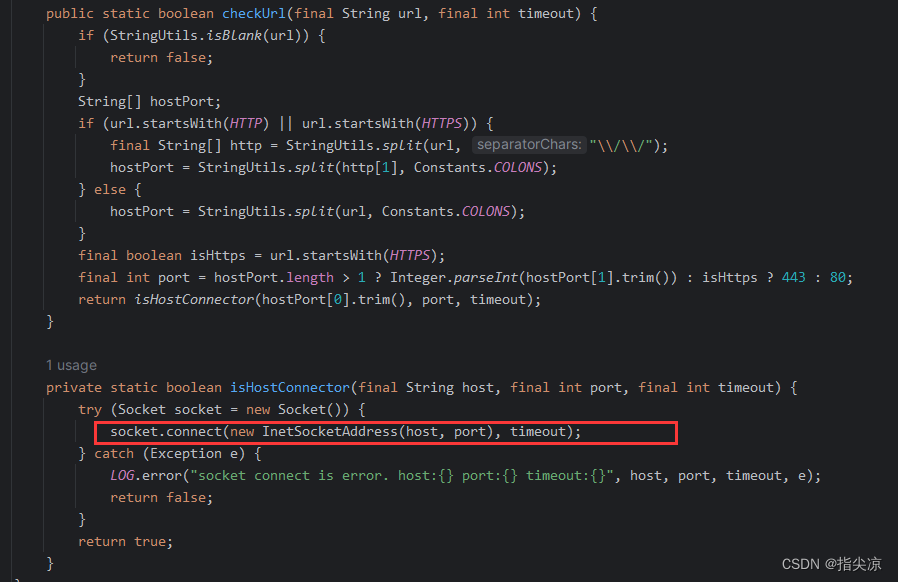
探活的逻辑也比较简单,通过sokect尝试连接,不报错就是连接成功,异常那服务就是有问题了。当然,如果服务之前是不健康的,healthy是false,这次连接成功也不会立马就直接认定为健康的,这要根据阈值判断。
代码中有这么一句interval >= (long) checkInterval * healthyThreshold,只有这个是true,才会将healthy设置为true,healthyThreshold参数定义了健康检查的阈值。
当连续健康检查成功次数超过healthyThreshold时,shenyu才会将上游服务标记为健康状态。这意味着,只有当连续健康检查成功次数超过healthyThreshold时,shenyu才会认为上游服务是可用的。相反也是一样的,只有当连续健康检查失败次数超过healthyThreshold时,shenyu才会认为上游服务是不可用的。
通过设置healthyThreshold参数,可以控制shenyu对上游服务健康状态的判断。较高的阈值意味着需要更多的连续健康检查成功才能将服务标记为健康,这可以增加容错能力。而较低的阈值则可能导致更快的将服务标记为健康,但也可能增加错误标记的风险。
由于这些检查任务都是在线程池中异步执行,所以需要通过future.get()方法来获取检查结果,所以接下来就需要阻塞等待每个任务的执行结果。
private void waitFinish() throws ExecutionException, InterruptedException {for (CompletableFuture<UpstreamWithSelectorId> future : futures) {// 获取检查结果,包括选择器id,上有服务,以及服务状态UpstreamWithSelectorId entity = future.get();// 将服务根据健康状态put到各自的map中putEntityToMap(entity);}futures.clear();
}private void putEntityToMap(final UpstreamWithSelectorId entity) {// 上游服务Upstream upstream = entity.getUpstream();// 如果是健康的,就加入到健康列表,并从不健康列表移除// 如果是不健康的,就加入到不健康列表,并从健康列表移除if (upstream.isHealthy()) {putToMap(healthyUpstream, entity.getSelectorId(), upstream);removeFromMap(unhealthyUpstream, entity.getSelectorId(), upstream);} else {putToMap(unhealthyUpstream, entity.getSelectorId(), upstream);removeFromMap(healthyUpstream, entity.getSelectorId(), upstream);}
}
最后清空futures列表,一次网关探活任务就完成了。
认真看就会发现,上面探活任务只涉及到服务的健康状态更新,服务的增加以及删除呢?
由于无法直接操作网关,所以网关中的任何变更都是由admin端同步过来的,服务是跟选择器绑定的,所以在admin上新增删除选择器或http服务启动和停止都会将服务实例同步给网关。网关监听到选择器的变更后,最终都会调用到CommonPluginDataSubscriber类的updateCacheData()方法或removeCacheData()方法。
private <T> void updateCacheData(@NonNull final T data) {if (data instanceof PluginData) {//...} else if (data instanceof SelectorData) {//...// 对应插件自己的处理逻辑,比如更新插件里的缓存,divide插件更新上游服务实例列表Optional.ofNullable(handlerMap.get(selectorData.getPluginName())).ifPresent(handler -> handler.handlerSelector(selectorData));//...} else if (data instanceof RuleData) {//...}
}private <T> void removeCacheData(@NonNull final T data) {if (data instanceof PluginData) { // 删除插件//...} else if (data instanceof SelectorData) { // 删除选择器//...// 插件自己还有的逻辑,比如divide插件还要删除上游服务列表Optional.ofNullable(handlerMap.get(selectorData.getPluginName())).ifPresent(handler -> handler.removeSelector(selectorData));//...} else if (data instanceof RuleData) { // 删除规则//...}
}
如果是divide插件下的选择器,就会执行到DividePluginDataHandler,去UpstreamCacheManager中更新上游服务实例。
public class DividePluginDataHandler implements PluginDataHandler {/*** 新增选择器或更新选择器*/@Overridepublic void handlerSelector(final SelectorData selectorData) {if (Objects.isNull(selectorData) || Objects.isNull(selectorData.getId())) {return;}// 该选择器里配置的服务实例列表List<DivideUpstream> upstreamList = GsonUtils.getInstance().fromList(selectorData.getHandle(), DivideUpstream.class);// 更新上游服务实例缓存UpstreamCacheManager.getInstance().submit(selectorData.getId(), convertUpstreamList(upstreamList));// the update is also need to clean, but there is no way to// distinguish between crate and update, so it is always cleanMetaDataCache.getInstance().clean();if (!selectorData.getContinued()) {CACHED_HANDLE.get().cachedHandle(CacheKeyUtils.INST.getKey(selectorData.getId(), Constants.DEFAULT_RULE), DivideRuleHandle.newInstance());}}/*** 删除选择器*/@Overridepublic void removeSelector(final SelectorData selectorData) {// 删除上游服务实例缓存UpstreamCacheManager.getInstance().removeByKey(selectorData.getId());MetaDataCache.getInstance().clean();CACHED_HANDLE.get().removeHandle(CacheKeyUtils.INST.getKey(selectorData.getId(), Constants.DEFAULT_RULE));}//。。。
}
admin端服务探活
admin端也有一个http服务探活任务UpstreamCheckService,类似网关那边,也分别维护两个健康和不健康的列表。UPSTREAM_MAP里面的服务对象有两个来源,一个来自于原有的数据库,一个来自于其他http服务的注册。
@Component
public class UpstreamCheckService {/*** 正常服务列表*/private static final Map<String /** 选择器id **/, List<CommonUpstream>> UPSTREAM_MAP = Maps.newConcurrentMap();/*** 僵尸服务列表。* 如果健康检查通过,服务将被添加到正常服务列表中;* 如果健康检查失败,则不会直接丢弃,而是将该服务并添加到僵尸节点中*/private static final Set<ZombieUpstream> ZOMBIE_SET = Sets.newConcurrentHashSet();public UpstreamCheckService(final SelectorMapper selectorMapper,final ApplicationEventPublisher eventPublisher,final PluginMapper pluginMapper,final SelectorConditionMapper selectorConditionMapper,final ShenyuRegisterCenterConfig shenyuRegisterCenterConfig,final SelectorHandleConverterFactor converterFactor) {this.selectorMapper = selectorMapper;this.eventPublisher = eventPublisher;this.pluginMapper = pluginMapper;this.selectorConditionMapper = selectorConditionMapper;this.converterFactor = converterFactor;Properties props = shenyuRegisterCenterConfig.getProps();this.checked = Boolean.parseBoolean(props.getProperty(Constants.IS_CHECKED, Constants.DEFAULT_CHECK_VALUE));this.scheduledThreads = Integer.parseInt(props.getProperty(Constants.ZOMBIE_CHECK_THREADS, Constants.ZOMBIE_CHECK_THREADS_VALUE));this.zombieCheckTimes = Integer.parseInt(props.getProperty(Constants.ZOMBIE_CHECK_TIMES, Constants.ZOMBIE_CHECK_TIMES_VALUE));this.scheduledTime = Integer.parseInt(props.getProperty(Constants.SCHEDULED_TIME, Constants.SCHEDULED_TIME_VALUE));this.registerType = shenyuRegisterCenterConfig.getRegisterType();zombieRemovalTimes = Integer.parseInt(props.getProperty(Constants.ZOMBIE_REMOVAL_TIMES, Constants.ZOMBIE_REMOVAL_TIMES_VALUE));// 只有http方式注册的才会启动服务探活任务if (REGISTER_TYPE_HTTP.equalsIgnoreCase(registerType)) {setup();}}
}
UpstreamCheckService的构造方法中,只有通过http方式注册的才会启动服务探活任务,即admin配置shenyu.register.registerType=http时才会生效。
/**1. 启动探活任务*/
public void setup() {if (checked) {// 从数据库中读取服务列表(selector的handle字段),保存到UPSTREAM_MAPthis.fetchUpstreamData();// 开启探活任务,每隔10秒执行一次executor = new ScheduledThreadPoolExecutor(1, ShenyuThreadFactory.create("scheduled-upstream-task", false));scheduledFuture = executor.scheduleWithFixedDelay(this::scheduled, 10, scheduledTime, TimeUnit.SECONDS);ThreadFactory requestFactory = ShenyuThreadFactory.create("upstream-health-check-request", true);invokeExecutor = new ScheduledThreadPoolExecutor(this.scheduledThreads, requestFactory);}
}
这里做了两件事:
- 读取数据库中的
selector,将handle字段解析为服务对象,保存到UPSTREAM_MAP。
public void fetchUpstreamData() {final List<PluginDO> pluginDOList = pluginMapper.selectByNames(PluginEnum.getUpstreamNames());if (CollectionUtils.isEmpty(pluginDOList)) {return;}Map<String /* 插件id */, String /* 插件名 */> pluginMap = pluginDOList.stream().filter(Objects::nonNull).collect(Collectors.toMap(PluginDO::getId, PluginDO::getName, (value1, value2) -> value1));// rpc插件下的选择器final List<SelectorDO> selectorDOList = selectorMapper.findByPluginIds(new ArrayList<>(pluginMap.keySet()));long currentTimeMillis = System.currentTimeMillis();Optional.ofNullable(selectorDOList).orElseGet(ArrayList::new).stream().filter(selectorDO -> Objects.nonNull(selectorDO) && StringUtils.isNotEmpty(selectorDO.getHandle())).forEach(selectorDO -> {String name = pluginMap.get(selectorDO.getPluginId());// 过滤出选择器handle中的状态为开启的实例,并转为CommonUpstreamList<CommonUpstream> commonUpstreams = converterFactor.newInstance(name).convertUpstream(selectorDO.getHandle()).stream().filter(upstream -> upstream.isStatus() || upstream.getTimestamp() > currentTimeMillis - TimeUnit.SECONDS.toMillis(zombieRemovalTimes)).collect(Collectors.toList());if (CollectionUtils.isNotEmpty(commonUpstreams)) {// 将commonUpstreams保存到UPSTREAM_MAPUPSTREAM_MAP.put(selectorDO.getId(), commonUpstreams);PENDING_SYNC.add(NumberUtils.INTEGER_ZERO);}});
}
- 开启探活任务,每隔10秒执行一次。
执行方式跟网关那边的差不多,也是用一个线程执行健康检查任务,另外一个线程池执行sokect请求任务。
private void scheduled() {try {// 开始多线程异步检查doCheck();// 等待所有任务执行完waitFinish();} catch (Exception e) {LOG.error("upstream scheduled check error -------- ", e);}
}
也是异步检查然后等待检查完成
private void doCheck() {// 检查僵尸服务if (!ZOMBIE_SET.isEmpty()) {ZOMBIE_SET.forEach(this::checkZombie);}// 检查健康的服务if (!UPSTREAM_MAP.isEmpty()) {UPSTREAM_MAP.forEach(this::check);}
}
分别对僵尸服务和健康的服务进行检查
僵尸服务检查
private void checkZombie(final ZombieUpstream zombieUpstream) {CompletableFuture<Void> future = CompletableFuture.runAsync(() -> checkZombie0(zombieUpstream), invokeExecutor);futures.add(future);
}private void checkZombie0(final ZombieUpstream zombieUpstream) {ZOMBIE_SET.remove(zombieUpstream);String selectorId = zombieUpstream.getSelectorId();CommonUpstream commonUpstream = zombieUpstream.getCommonUpstream();// 检查僵尸服务是否存活了final boolean pass = UpstreamCheckUtils.checkUrl(commonUpstream.getUpstreamUrl());if (pass) {// 僵尸服务又重新存活了// 设置启动为当前时间commonUpstream.setTimestamp(System.currentTimeMillis());// 状态启动commonUpstream.setStatus(true);LOG.info("UpstreamCacheManager check zombie upstream success the url: {}, host: {} ", commonUpstream.getUpstreamUrl(), commonUpstream.getUpstreamHost());// 原本selectorId下存活的实例服务List<CommonUpstream> old = ListUtils.unmodifiableList(UPSTREAM_MAP.getOrDefault(selectorId, Collections.emptyList()));// 更新UPSTREAM_MAP,更新数据库,发布事件同步网关this.submit(selectorId, commonUpstream);updateHandler(selectorId, old, UPSTREAM_MAP.get(selectorId));} else {LOG.error("check zombie upstream the url={} is fail", commonUpstream.getUpstreamUrl());// 检查次数减1,如果次数使用完还没连通,则彻底移除if (zombieUpstream.getZombieCheckTimes() > NumberUtils.INTEGER_ZERO) {zombieUpstream.setZombieCheckTimes(zombieUpstream.getZombieCheckTimes() - NumberUtils.INTEGER_ONE);ZOMBIE_SET.add(zombieUpstream);}}
}
僵尸服务检查成功,则将状态设为true,更新UPSTREAM_MAP,更新数据库,发布selector更新事件同步网关。如果还是失败,则将检查次数-1,如果次数使用完还没连通,则会彻底移除。
健康服务检查
private void check(final String selectorId, final List<CommonUpstream> upstreamList) {final List<CompletableFuture<CommonUpstream>> checkFutures = new ArrayList<>(upstreamList.size());for (CommonUpstream commonUpstream : upstreamList) {checkFutures.add(CompletableFuture.supplyAsync(() -> {// 检查连通性final boolean pass = UpstreamCheckUtils.checkUrl(commonUpstream.getUpstreamUrl());if (pass) {// 通过则更新启动时间戳if (!commonUpstream.isStatus()) {commonUpstream.setTimestamp(System.currentTimeMillis());commonUpstream.setStatus(true);PENDING_SYNC.add(commonUpstream.hashCode());LOG.info("UpstreamCacheManager check success the url: {}, host: {} ", commonUpstream.getUpstreamUrl(), commonUpstream.getUpstreamHost());}return commonUpstream;} else {// 检查失败则状态置为false,加入到僵尸列表commonUpstream.setStatus(false);ZOMBIE_SET.add(ZombieUpstream.transform(commonUpstream, zombieCheckTimes, selectorId));LOG.error("check the url={} is fail ", commonUpstream.getUpstreamUrl());}return null;}, invokeExecutor).exceptionally(ex -> {LOG.error("An exception occurred during the check of url {}: {}", commonUpstream.getUpstreamUrl(), ex);return null;}));}this.futures.add(CompletableFuture.runAsync(() -> {// 过滤出返回值不为空的即检查成功的List<CommonUpstream> successList = checkFutures.stream().map(CompletableFuture::join).filter(Objects::nonNull).collect(Collectors.toList());// 更新UPSTREAM_MAP,更新数据库并发布更新事件,同步到网关updateHandler(selectorId, upstreamList, successList);}));
}
健康服务检查成功,更新时间,返回commonUpstream实例,如果检查失败,则状态设为false,加入到ZOMBIE_SET中,成为僵尸服务。最后也是更新UPSTREAM_MAP,更新数据库并发布selector更新事件,同步到网关。
在Shenyu探活服务中,僵尸列表的作用主要是用来记录那些已经失效或不再活跃的服务节点。这些服务节点可能因为各种原因(如网络抖动,网络故障、服务器宕机等)无法正常响应探活请求,因此被判定为僵尸节点。
ShenYu探活服务定期检查这些节点的状态,并在适当的时候将其从服务列表中移除。因为有可能由于网络抖动导致这次的健康检查没有成功,但是服务本身还是正常的,如果直接就将这个服务移除,就导致调用不到这台这台正常的服务。暂时标记为僵尸节点,等下次健康检查成功后就可以重新恢复为健康的节点。这有助于保持服务的高可用性和稳定性,避免因网络原因导致的服务中断或性能下降。
参考资料
Soul网关中的Http服务探活
![21、同济、微软亚研院、西安电子科技大提出HPT:层次化提示调优,独属于提示学习的[安妮海瑟薇]](https://img-blog.csdnimg.cn/direct/8dc1cbf4123241708542212863d828ec.jpeg)