【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解
文章目录
- 【图像分类】【深度学习】【Pytorch版本】 ResNeXt模型算法详解
- 前言
- ResNeXt讲解
- 分组卷积(Group Converlution)
- 分割-变换-合并策略(split-transform-merge)
- ResNeXt模型结构
- ResNeXt Pytorch代码
- 完整代码
- 总结
前言
ResNeXt是加利福尼亚大学圣迭戈分校的Xie, Saining等人在《Aggregated Residual Transformations for Deep Neural Networks【CVPR-2017】》【论文地址】一文中提出的模型,结合ResNet【参考】的卷积块堆叠的思想以及Inception【参考】的分割-变换-合并的策略,在不明显增加参数量级的情况下提升了模型的准确率。
ResNeXt讲解
Inception系列模型则证明精心设计的拓扑结构(采用分割-转换-合并策略),在拥有不错的表示能力同时计算复杂度大大降低:首先通过1×1的卷积将输入分割成多个低维度的嵌入,然后通过一组专门的过滤器(3×3,5×5等)分别进行转换,最后通过串联进行合并。
但是Inception系列的实现一直伴随着一系列复杂的因素:卷积核的数量和大小是为每个变换单独定制的,网络中的Inception模块也是逐个定制的。随着网络深度的增加,网络的超参数(卷积核个数、大小和步长等)也在增加,设计更好的网络架构以学习表征变得越来越困难。ResNets继承了VGGNet简单而有效的方法,采用相同拓扑结构的模块堆叠构建深度网络,不需要每层都单独设置超参数,减少了超参数的自由选择。
因此在论文中,ResNeXt提出了一个简单的架构,它以一种简单、可扩展的方式采用了ResNets的重复层策略,同时利用了Inception的分割-变换-合并策略。
分组卷积(Group Converlution)
在分组卷积中,将输入特征图的通道分成多个组,每个组内的通道只与相应组内的卷积核进行卷积运算,最后将各个组的输出特征图连接在一起,形成最终的输出特征图。
以下是博主绘制的普通卷积和分组卷积的示意图:

实际上无论普通卷积还是分组卷积,卷积核的数量没有发生改变,只不过分组卷积的卷积核的通道数变小了。
分组卷积的主要目的是减少卷积操作的计算量,特别适用于在计算资源有限的情况下进行模型设计。
分割-变换-合并策略(split-transform-merge)
注意:这个小节比较考验读者的对卷积过程的认知功底,建议大家好好理解下,有助于大家夯实基本功。
先说结论,下图是原论文中给出的结构示意图,a图结构是分割-变换-合并策略的体现,c图结构则是使用分组卷积后的对a图结构的等价替换。
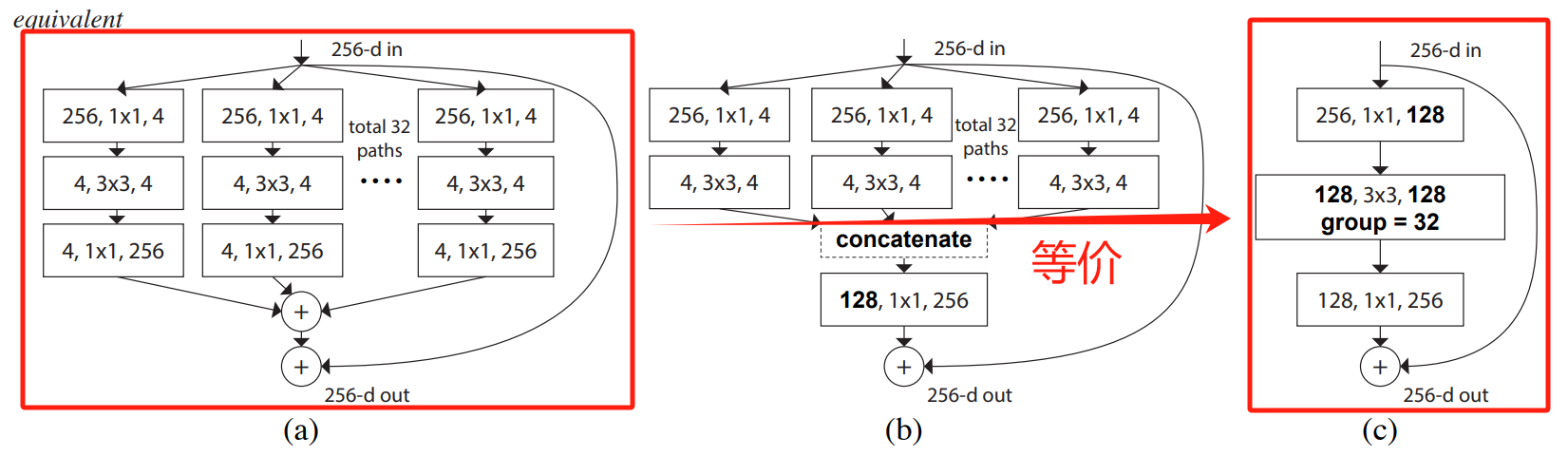
接下来博主就将详细讲解分割-变换-合并策略中每一个步骤的过程和作用,为了方便大家理解,博主采用了a图的结构进行讲解。
ResNeXt通过将输入数据分割成多个子集,每个子集进行独立的变换操作,网络可以学习到更多不同的特征表示。而通过合并操作,网络可以将这些不同的特征表示进行组合,从而得到更丰富的特征表达能力。
-
split:分割输入数据。
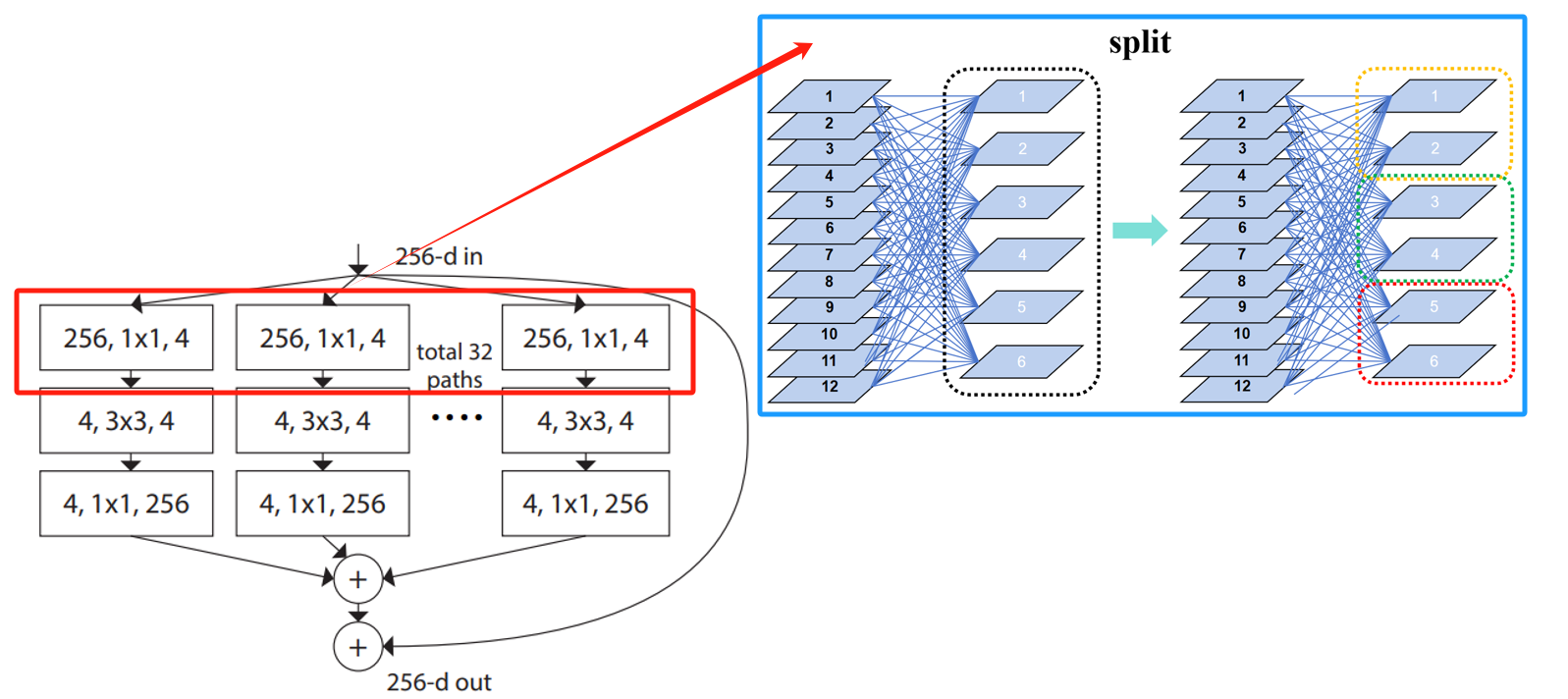
分割可以理解为将多个卷积核划分到不同组,每个组的卷积核个数一致。如示意图所示,将一层大卷积层拆分成多个小卷积层后处理同一个输入,假设将多个小卷积层的输出(子集)拼接成一起就等价于大卷积层的输出,因此俩者是等效的。个人理解:其实可以只用一个卷积层进行卷积,将输出的特征图按照组进行拆分即可,不需要对多个小卷积层单独分组。
-
transform:子集独立变换。
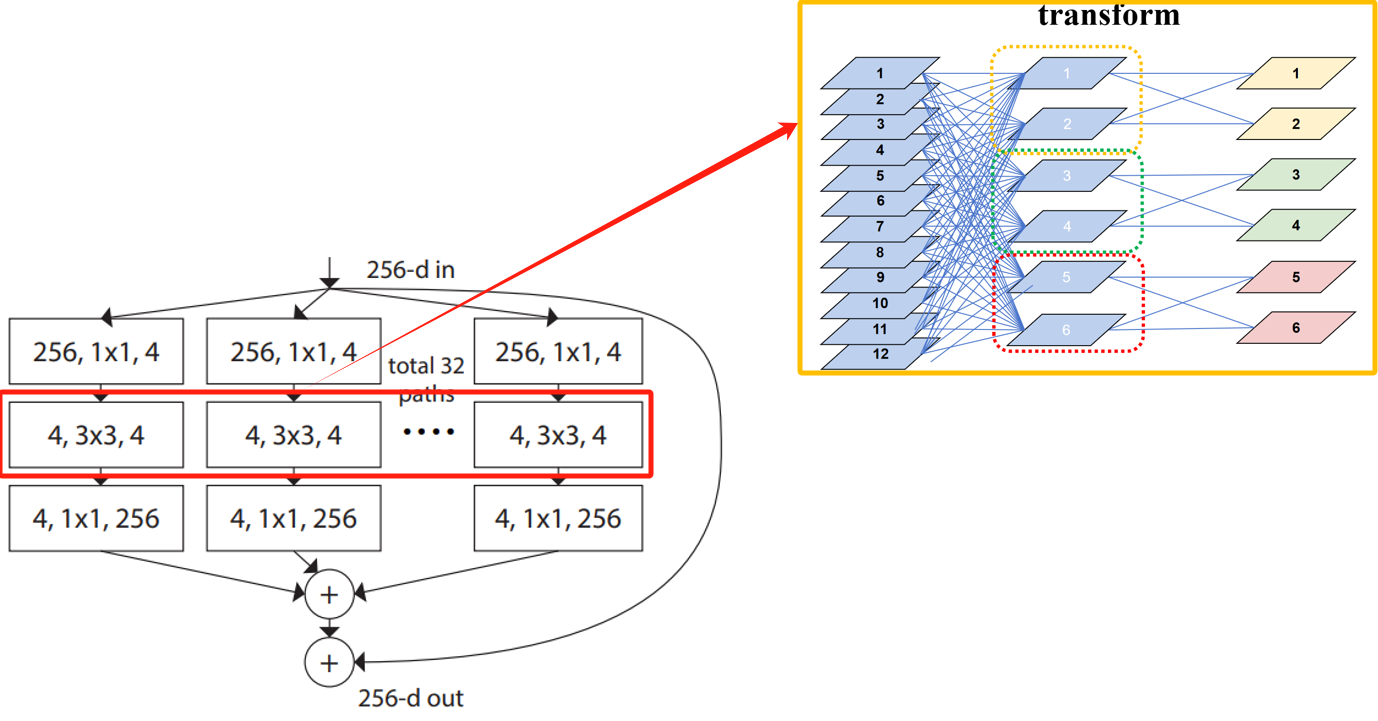
每个小卷积层的输出(子集)再经过一层各自的卷积层进行卷积变换。如示意图所示,等价于分组卷积。个人理解:早期深度学习框架不支持分组卷积,因此分组卷积的实现,需要在分组卷积事先将输入按照分组进行拆分,也是就split过程,然后对分组后的输入子集再进行小组内卷积。
-
merge:合并特征图。
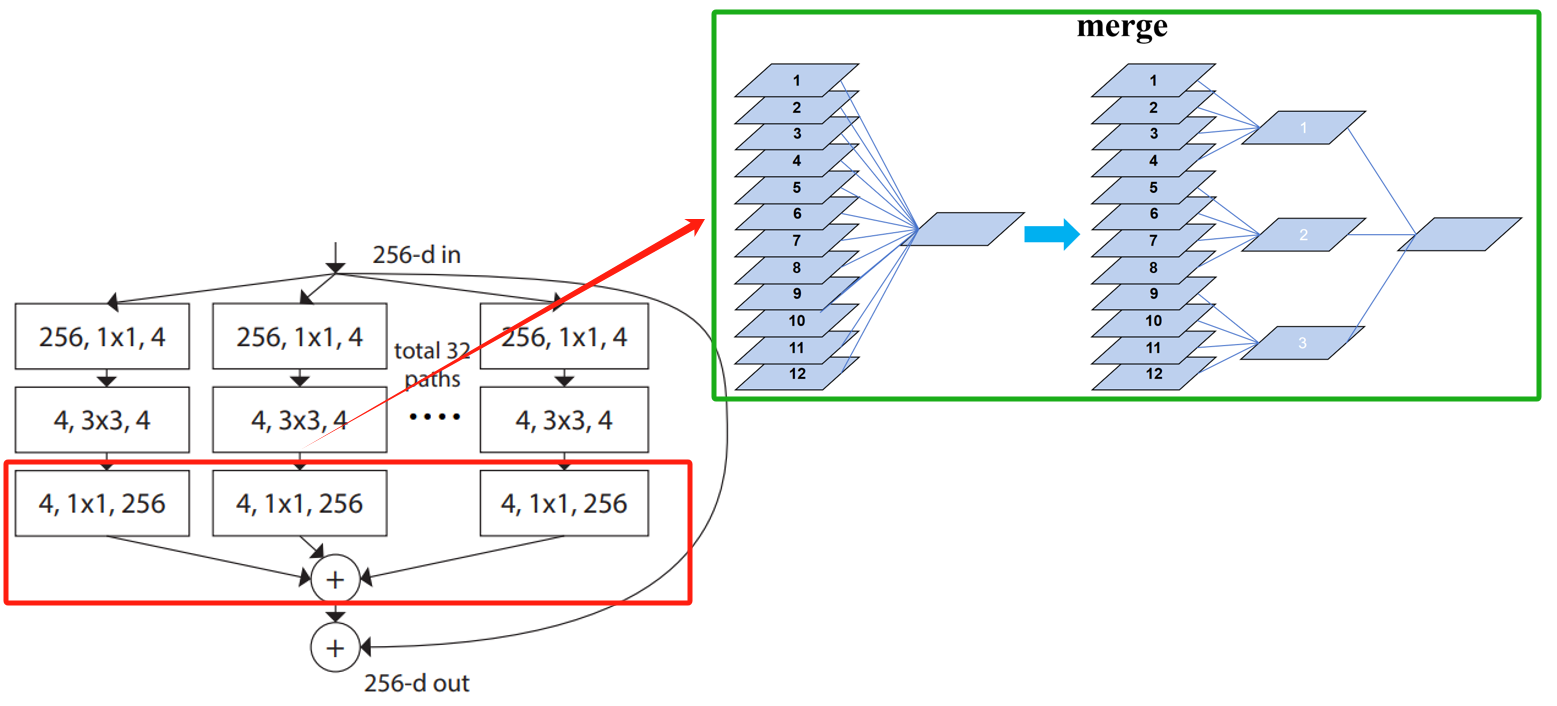
合并可以理解为将一个大卷积核划分成多个小卷积核,每个小卷积核拥有大卷积核的一部分通道,每个小卷积核的通道数量一致。如示意图所示,大卷积核通道数和拆分后的小卷积核的总通道数是一致的。回顾以下,传统的卷积运算(大卷积核)的输出特征是由每个通道的权重与对应输入特征进行运算和相加而来,即1到12一次性相加,那么小卷积就是将这个过程进行了拆分,即先是1到4、5到8和9到12分别相加,然后再对三个相加结果再进行相加。个人理解:其实先将多组输入的特征图进行拼接,只用一个大卷积核组成的卷积层进行卷积即可,不需要用多个小卷积核组成的卷积层。
ResNeXt模型结构
ResNeXt对ResNet进行了改进,采用了多分支的策略,在论文中作者提出了三种等价的模型结构,最后的ResNeXt采用了图c的结构来构建ResNeXt,因为c结构比较简洁而且速度更快。
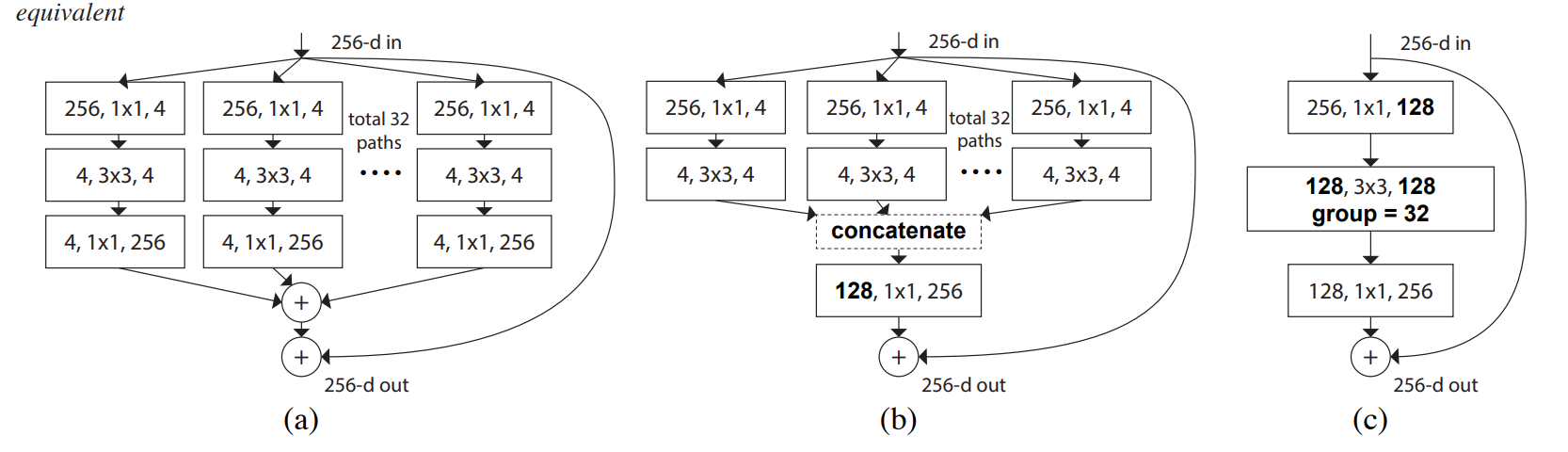
ResNeXt通过增加cardinality(group)参数,可以灵活地控制子集的数量,增加基数可以提高模型的性能,提高特征提取的能力,且要比增加宽度和深度更有效。
下图是原论文给出的关于ResNeXt模型结构的详细示意图:
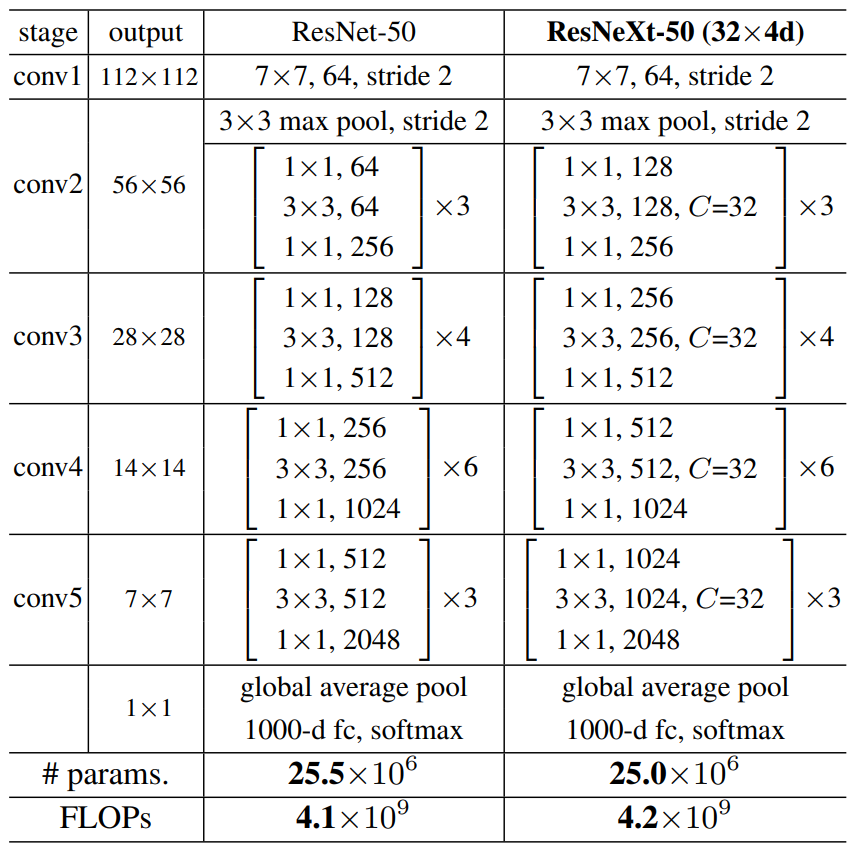
ResNeXt与ResNet一样也是构建基于两个准则:1.同阶段中的残差块使用相同的卷积核个数和卷积核尺寸;2.特征图减小时增加卷积核个数。基于上述准则,在ResNet-50模型的基础上,提出了ResNeXt-50模型。
ResNeXt在图像分类中分为两部分:backbone部分: 主要由残差结构、卷积层和池化层(汇聚层)组成,分类器部分:由全局平均池化层和全连接层组成 。
ResNeXt只能在残差块的深度超过2层时使用,所以ResNeXt不在ResNet18和34进行修改的原因。
ResNeXt Pytorch代码
分组卷积层:
# 3×3分组卷积
nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)
残差结构Bottleneck: 卷积层(或分组卷积层)+BN层+激活函数
class Bottleneck(nn.Module):expansion = 4# 残差结构参考了resnet的残差结构def __init__(self, in_channel, out_channel, stride=1, downsample=None,groups=1, width_per_group=64):super(Bottleneck, self).__init__()# 是为了保证卷积核个数能被组数整除,每组的卷积核个数不出现小数width = int(out_channel * (width_per_group / 64.)) * groups# 第一层(降维)self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,kernel_size=1, stride=1, bias=False) # squeeze channelsself.bn1 = nn.BatchNorm2d(width)# 第二层(分组卷积)self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)self.bn2 = nn.BatchNorm2d(width)# 第三层(升维)self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,kernel_size=1, stride=1, bias=False) # unsqueeze channelsself.bn3 = nn.BatchNorm2d(out_channel*self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out += identityout = self.relu(out)return out
完整代码
import torch.nn as nn
import torch
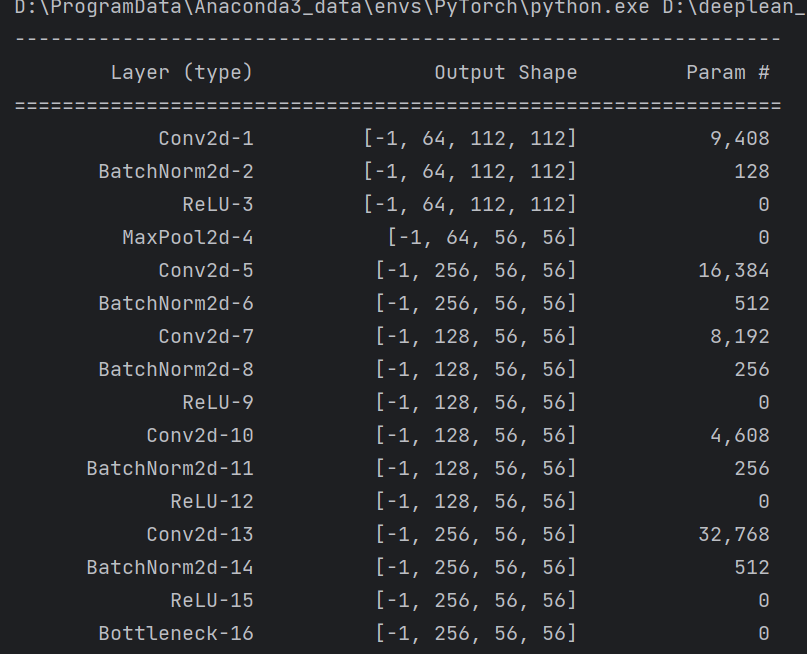
from torchsummary import summaryclass Bottleneck(nn.Module):expansion = 4# 残差结构参考了resnet的残差结构def __init__(self, in_channel, out_channel, stride=1, downsample=None,groups=1, width_per_group=64):super(Bottleneck, self).__init__()# 是为了保证卷积核个数能被组数整除,每组的卷积核个数不出现小数width = int(out_channel * (width_per_group / 64.)) * groups# 第一层(降维)self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,kernel_size=1, stride=1, bias=False) # squeeze channelsself.bn1 = nn.BatchNorm2d(width)# 第二层(分组卷积)self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)self.bn2 = nn.BatchNorm2d(width)# 第三层(升维)self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,kernel_size=1, stride=1, bias=False) # unsqueeze channelsself.bn3 = nn.BatchNorm2d(out_channel*self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out += identityout = self.relu(out)return outclass ResNeXt(nn.Module):def __init__(self,blocks_num,num_classes=1000,groups=1,width_per_group=64):super(ResNeXt, self).__init__()self.in_channel = 64# 组数self.groups = groups# 每组包含的卷积个数self.width_per_group = width_per_groupself.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,padding=3, bias=False)self.bn1 = nn.BatchNorm2d(self.in_channel)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 第一组残差块组self.layer1 = self._make_layer(Bottleneck, 64, blocks_num[0])# 第二组残差块组self.layer2 = self._make_layer(Bottleneck, 128, blocks_num[1], stride=2)# 第三组残差块组self.layer3 = self._make_layer(Bottleneck, 256, blocks_num[2], stride=2)# 第四组残差块组self.layer4 = self._make_layer(Bottleneck, 512, blocks_num[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)self.fc = nn.Linear(512 * Bottleneck.expansion, num_classes)# 权重初始化for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')def _make_layer(self, block, channel, block_num, stride=1):downsample = Noneif stride != 1 or self.in_channel != channel * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(channel * block.expansion))layers = []layers.append(block(self.in_channel,channel,downsample=downsample,stride=stride,groups=self.groups,width_per_group=self.width_per_group))self.in_channel = channel * block.expansionfor _ in range(1, block_num):layers.append(block(self.in_channel,channel,groups=self.groups,width_per_group=self.width_per_group))return nn.Sequential(*layers)def forward(self, x):# backbone主干网络部分# resnext50为例# N x 3 x 224 x 224x = self.conv1(x)# N x 64 x 112 x 112x = self.bn1(x)# N x 64 x 112 x 112x = self.relu(x)# N x 64 x 112 x 112x = self.maxpool(x)# N x 64 x 56 x 56x = self.layer1(x)# N x 256 x 56 x 56x = self.layer2(x)# N x 512 x 28 x 28x = self.layer3(x)# N x 1024 x 14 x 14x = self.layer4(x)# N x 2048 x 7 x 7x = self.avgpool(x)# N x 2048 x 1 x 1x = torch.flatten(x, 1)# N x 2048x = self.fc(x)# N x 1000return xdef resnext50_32x4d(num_classes=1000):# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pthgroups = 32width_per_group = 4return ResNeXt([3, 4, 6, 3],num_classes=num_classes,groups=groups,width_per_group=width_per_group)def resnext101_32x8d(num_classes=1000):# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pthgroups = 32width_per_group = 8return ResNeXt([3, 4, 23, 3],num_classes=num_classes,groups=groups,width_per_group=width_per_group)if __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = resnext50_32x4d().to(device)summary(model, input_size=(3, 224, 224))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了分组卷积的原理和在卷积神经网络中的作用,讲解了ResNeXt模型的结构和pytorch代码。