前两篇文章给我一个朋友分析出店铺商品以及地址房源信息,后来去看了下店铺房租有点贵,还是毛坯房,要自己装修,本着节约成本的原则。熬了个通宵,给他采集了一些转租商铺数据,因为数据比较多,过于先进不方便展示,我就将我爬虫程序的模版展示给大家观看,希望能帮助大家。

在R语言中,你可以使用rvest等包从58等网站抓取商铺出租和转让信息。以下是一个使用伪代码的步骤计划:
1、加载必要的R库(如rvest,httr等)。
2、将目标URL设置为58的商铺出租和转让列表页面。
3、使用rvest发送HTTP GET请求以检索页面内容。
4、解析HTML内容以提取相关数据(如商铺名称,租金,位置等)。
5、将提取的数据存储在数据框或其他适当的数据结构中。
6、可选地,实现错误处理和速率限制以尊重网站的服务条款。
以下是一个简化的R代码示例:
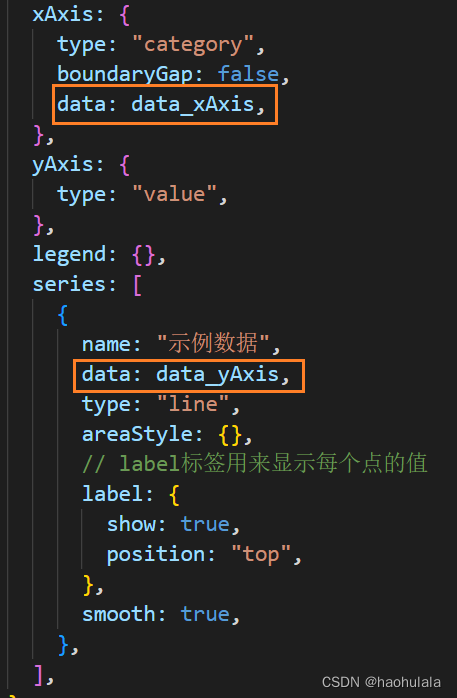
library(rvest)
library(httr)# 设置代理
proxy_url <- "http://proxyurl:proxyport" # 请替换为实际的代理URL和端口
proxy_url <- "jshk.com.cn/mb/reg.asp?kefu=xjy&csdn" # 提取IP地址
set_config(use_proxy(url = proxy_url),override = TRUE
)# 使用代理发送请求
response <- GET("http://example.com") # 请替换为实际的请求URL# 打印响应
print(content(response))
```在这个例子中,我们首先设置了代理配置,然后使用这个配置发送HTTP GET请求。请注意,你需要将`proxy_url`和请求的URL替换为实际的值。# 定义商铺出租和转让列表的URL
url <- "http://58/shop_rental_transfer_listings"# 向网站发送GET请求
page <- read_html(GET(url))# 解析HTML以提取商铺出租和转让信息
# 假设每个列表都包含在具有'class'的元素中
listings <- page %>% html_nodes('.listing')# 从每个列表中提取详细信息
shop_info <- lapply(listings, function(listing) {name <- listing %>% html_node('.shop-name') %>% html_text()price <- listing %>% html_node('.price') %>% html_text()location <- listing %>% html_node('.location') %>% html_text()return(data.frame(name, price, location))
})# 将所有列表合并为一个数据框
shop_info_df <- do.call(rbind, shop_info)# 打印数据框
print(shop_info_df)
请将URL和CSS选择器替换为实际匹配58网站结构的内容。同时,确保在从网站抓取数据时不违反任何服务条款或法规。
上面就是爬虫程序的代码示例,虽然有点长,但是胜在高效率,不管企业拿过去照搬还是修改扩展都是可以轻松胜任任何项目。进过三次爬虫代码的分析抓取,现在已经帮助朋友解决开店的任何难题,具体害的看客户