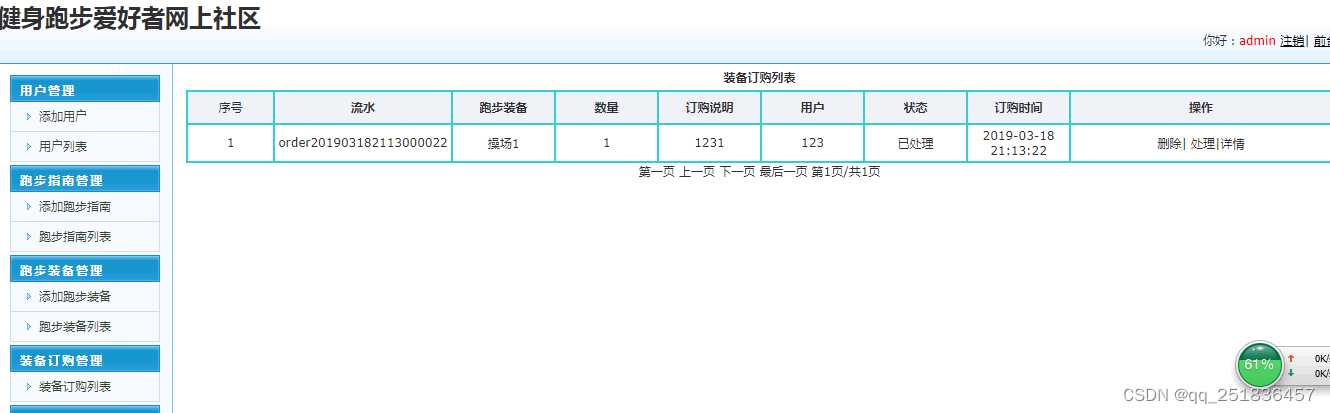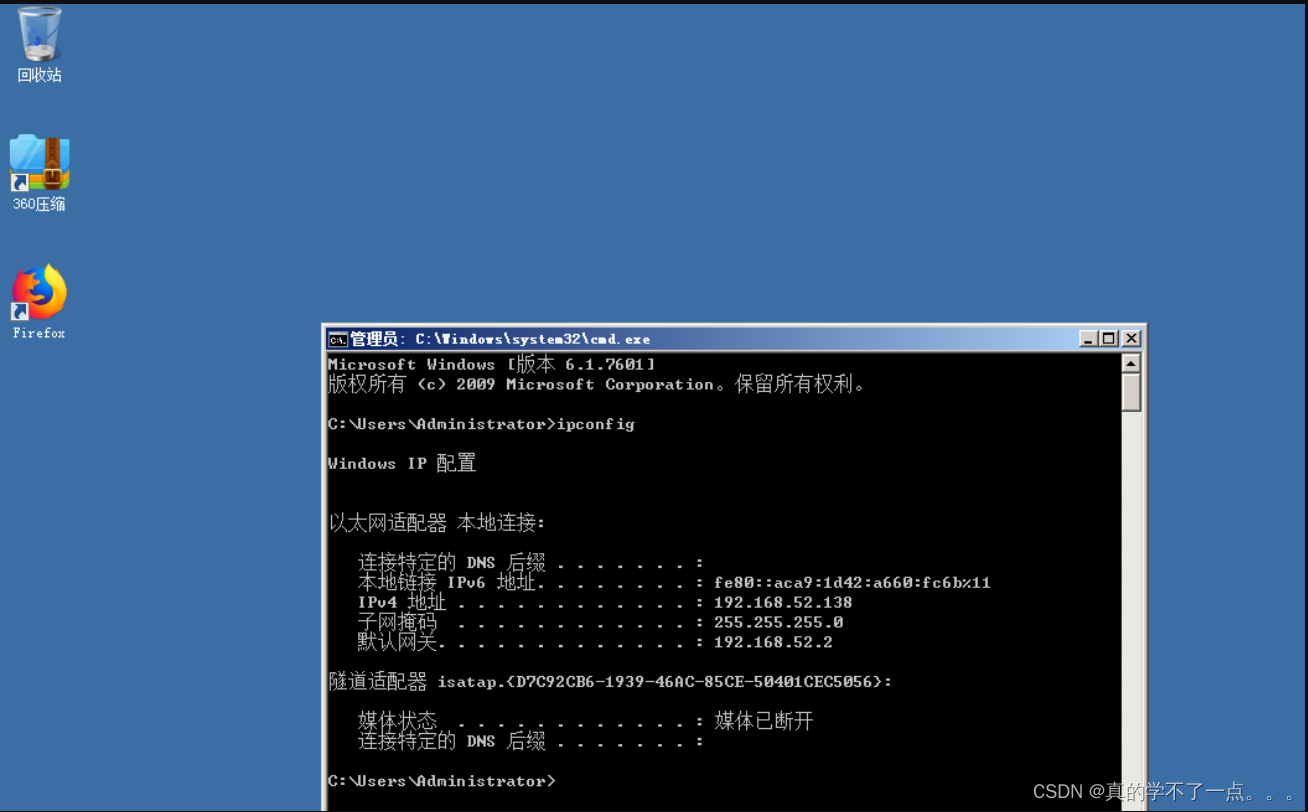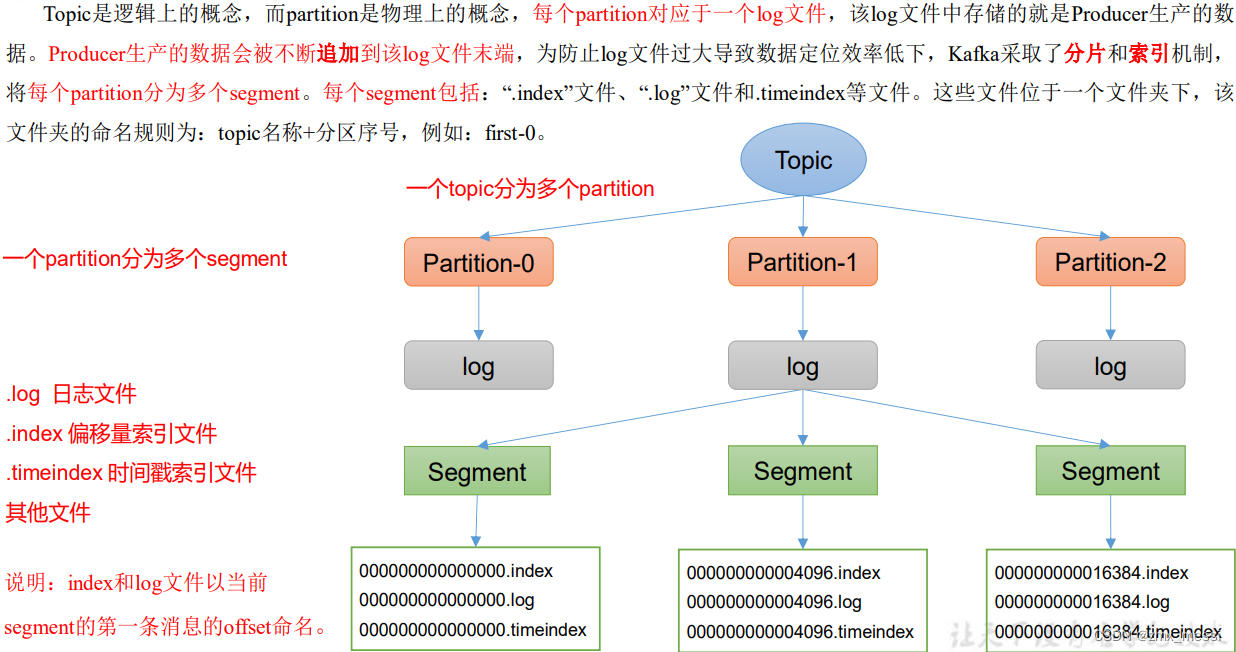
Topic分为好几个partition分区,每个分区对应于一个log文件,log文件其实是虚的,Kafka采取了分片和索引机制, 将每个partition分为多个segment(大小为1G)。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该 文件夹的命名规则为:topic名称+分区序号,例如:first-0。
index和log文件以当前 segment的第一条消息的offset命名。
index 文件和 log 文件详解
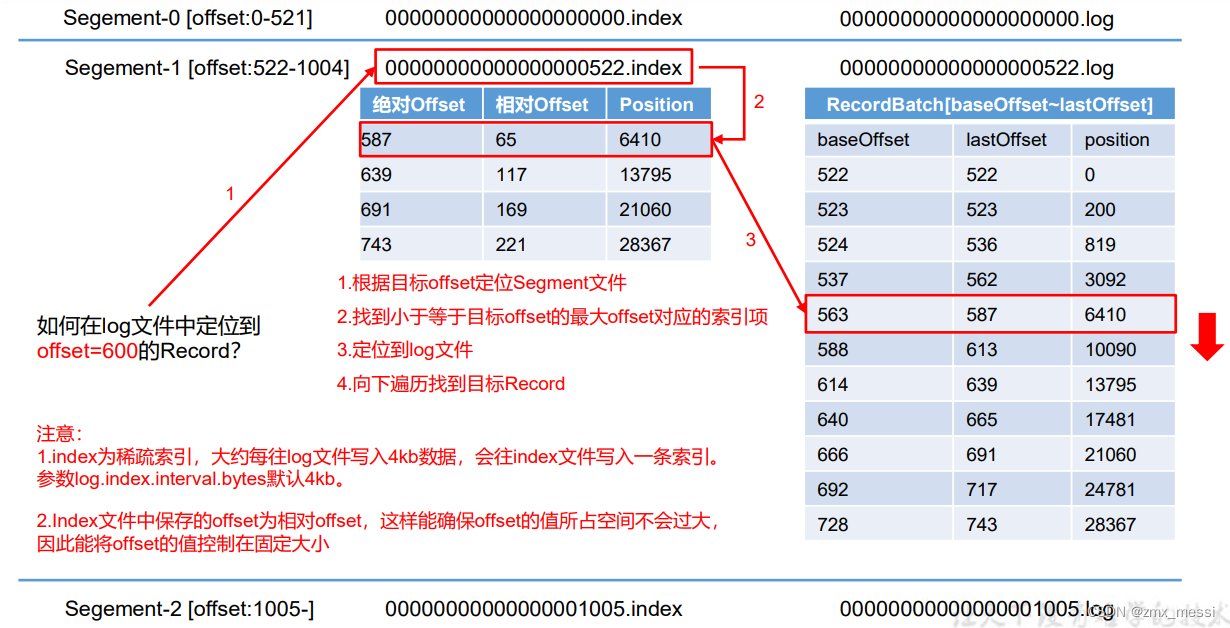
index文件往往不大,其实是因为index为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引。
index文件内部是这样的:
offset: 3 position: 152
而 log文件是存储真实数据的:
Dumping datas/first-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
0 CreateTime: 1636338440962 size: 75 magic: 2 compresscodec: none crc: 2745337109 isvalid:
true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
75 CreateTime: 1636351749089 size: 77 magic: 2 compresscodec: none crc: 273943004 isvalid:
true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
152 CreateTime: 1636351749119 size: 77 magic: 2 compresscodec: none crc: 106207379 isvalid:
true
baseOffset: 4 lastOffset: 8 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
229 CreateTime: 1636353061435 size: 141 magic: 2 compresscodec: none crc: 157376877 isvalid:
true
baseOffset: 9 lastOffset: 13 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position:
370 CreateTime: 1636353204051 size: 146 magic: 2 compresscodec: none crc: 4058582827 isvalid:
true
.Index文件中保存的offset为相对offset,这样能确保offset的值所占空间不会过大, 因此能将offset的值控制在固定大小,后面的position去log文件里对应的position去找,向下遍历,直到定位到存储位置。