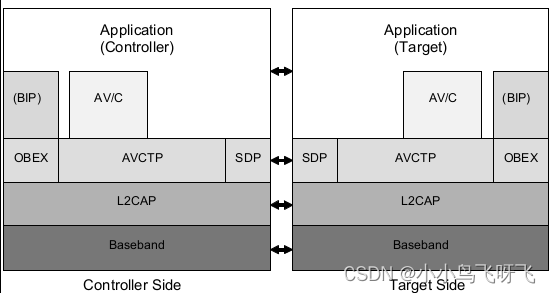
目录
一、矩阵与数组
二、列表
三、数据框
四、因子
五、缺失数据
六、字符串
七、日期和时间
参考
一、矩阵与数组
matrix:创建矩阵,nrow 和 ncol 可以省略,但其值必须满足分配条件,否则会报错
只写一个值则自动分配,默认按列分配
byrow属性可以控制矩阵按行排列



dimnames(m):定义矩阵行和列的名字
dim(x):输出x的维度
dim(x) <- c(2,5):为 x 添加维度(创建数组),三个数字则为三维数组


array函数创建数组
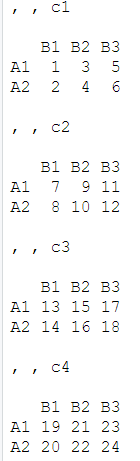
array(1:24, c(2,3,4), dimnames=list(dim1, dim2, dim3)):1:24表示向量,c(2,3,4)为设置的维度,dimnames=list(dim1, dim2, dim3))为每个维度的名字
输出为:

矩阵的索引
m[2,3]:索引第二行第三列的元素
m[2,c(3,4,5)]:索引第二行,第三四五列的元素
m[c(1,2), c(3:5)]:取矩阵一二行中的三四五列
m[2,]:取第二行
m[,2]:取第二列
m[2]:取第二行第一个元素
m['R1', 'C2']:





矩阵的运算:对矩阵中的每个元素进行运算
直接计算矩阵的函数
colSums(x):计算矩阵每一列的和
rowSums(x):计算矩阵每一行的和
colMeans(x):计算矩阵每一列的均值
m*n:为矩阵的内积
m%*%n:为矩阵的外积
diag(x):返回矩阵x对角线位置的值
t(x):对矩阵进行转置

二、列表
生成列表
访问列表中的一个活多个元素
为每个对象添加名称
使用属性名访问列表元素




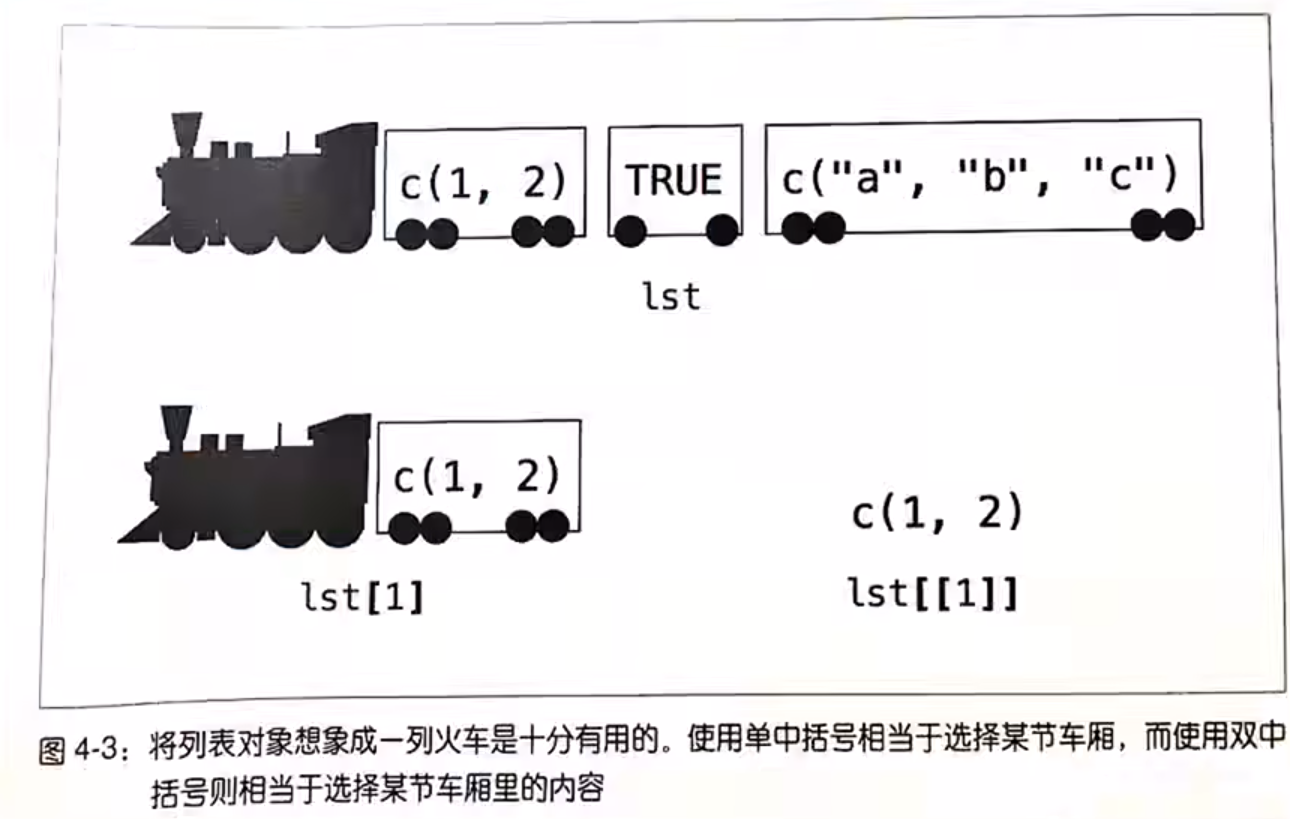
使用一个“[ ]”输出的是列表,两个“[ ]”输出的是元素本身

给列表添加值
添加新值要用 “ [[ ]] ”
删除列表中的元素:使用负索引的方式
或者将元素值赋值为 “NULL”



“ [ ] ” 和 “ [[ ]] ” 的区别:
三、数据框
数据框是一种表格形式的数据结构,数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
数据框实际上是一个列表,列表中的元素是向量,这些向量构成数据框的列,每一列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。
矩阵与数据框的区别:数据框形状很想矩阵;数据框是比较规则的列表;矩阵必须为同一数据类型;数据框每一列必须为同一类型,每一行可以不同。
创建数据框
数据框的访问:通过索引访问数据
取出对应的列
取出对应的行
使用 “$” 的方式可以快速取出一列
使用数据框的多列数据,attach加载数据框,使用完后用 detach 释放
使用with根据列名获取数据








四、因子
变量分类:名义型变量、有序型变量、连续型变量。
在R中,名义型变量和有序型变量被称为因子,这些分类变量的可能值称为一个水平,例如good、better、best都称为一个水平。
这些水平值构成的向量就称为因子。因子本身是向量的集合。
因子的应用:计算频数,独立性检验,相关性检验,方差分析,主成分分析,因子分析。。。
mtcars中的cyl是一个向量,table是对其做频数统计
factor(vector):定义因子
定义因子中水平的顺序
将向量转化为因子
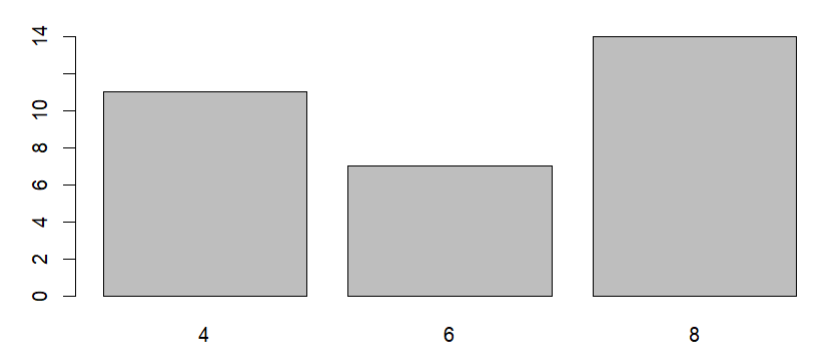
向量和因子输出的plot有什么区别
plot(mtcars$cyl):输出散点图
plot(factor(mtcars$cyl)):输出条形图
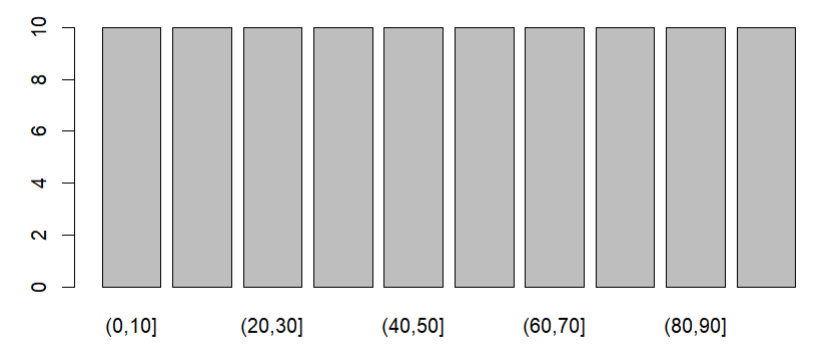
cut(vector):将一个连续型数据按level分类






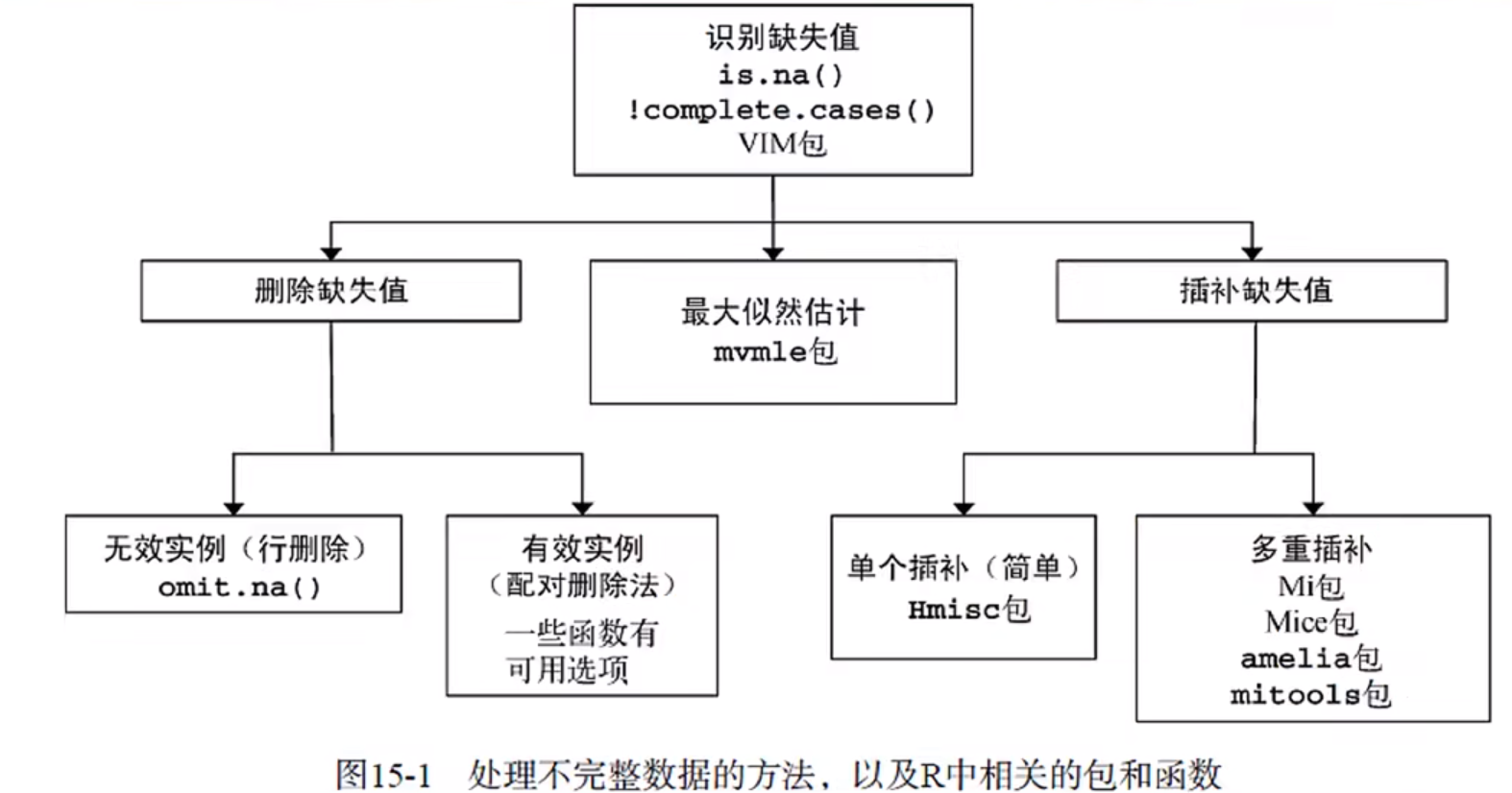
五、缺失数据

在R中, NA代表缺失值,NA是不可用,not available的简称,用来存储缺失信息。
NA表示未知,不知道是几,也不知道有几个数。
定义 na.rm = T 就可以计算有效值,表示去除NA值
验证是否有NA值,有则在对应位置返回TRUE
na.omit():去除缺失值,如果omit应用于数据框,则是将包含NA的每一行都删除。



缺失值的专门处理方式:
缺失数据NaN,代表不可能的值。
Inf表示无穷,分为正无穷和负无穷,代表无穷大和无穷小。
1/0,0不能做除数,所以输出不可能的数。
不同缺失值之间的差别
1.NA是存在的值,但是不知道是多少
2.NaN是不存在的
3.Inf存在,是无穷大或者无穷小,但是表示不可能的值。

六、字符串
正则表达式

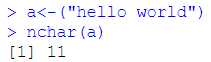
nchar:统计字符串的长度,空格也算一个字符串
nchar():返回向量中每个元素的长度
length():返回向量中的元素个数
paste():将多个字符串合并为一个
使用 “sep”设置分隔符
向量和字符串的连接,向量中的每个元素都和字符串相连
substr(string, start, stop):提取子字符串
toupper(string):将字符串转化为大写
tolower(string):将字符串转化为小写
首字母大写
首字母小写
grep():查找字符串
在x中查找“A+”,若fixed为TRUE,则表示在x中查找“A+”,若fixed为FALSE,则表示在x中查找以“A”开头的字符串,“+”表示匹配任意字符。
也可用 match 进行匹配
strsplit(string, 分隔符):分割字符串,返回的值是一个列表
strsplit可以对多个向量进行分割
outer():生成两个字符串之间的所有组合,paste表示连接两个字符串, sep设置连接符,默认为空格
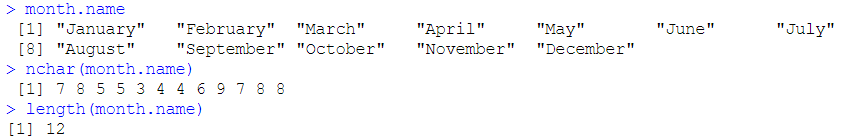
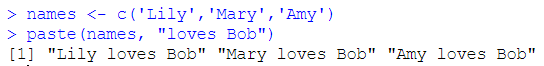






七、日期和时间
Sys.Date():系统当前时间
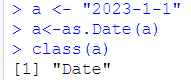
as.Date():定义一个时间类型,使用 “?strftime” 命令可以查看格式化参数
seq(start, end, step):创建连续的时间点
ts():生成时间序列,frequenc为12表示以年为单位,为4表示以季度为单位


参考
R语言入门与数据分析