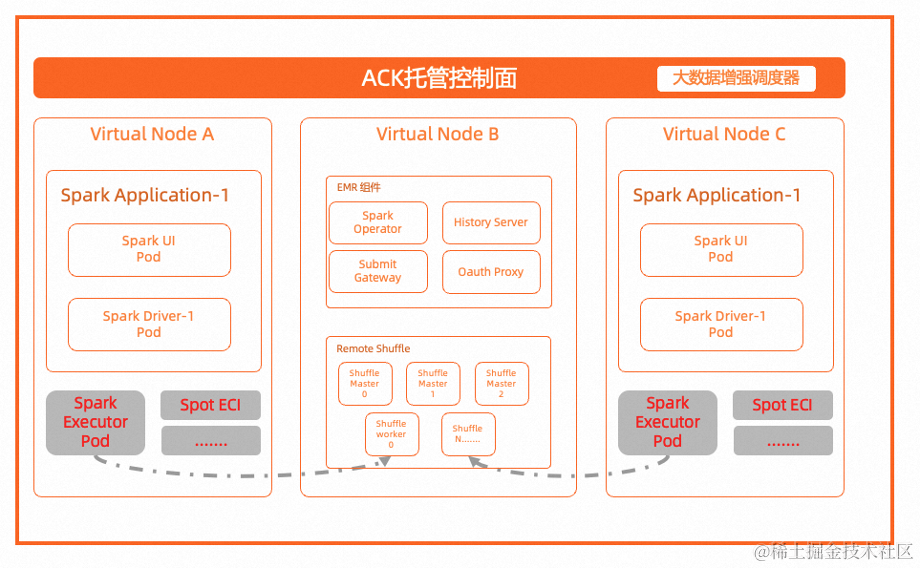
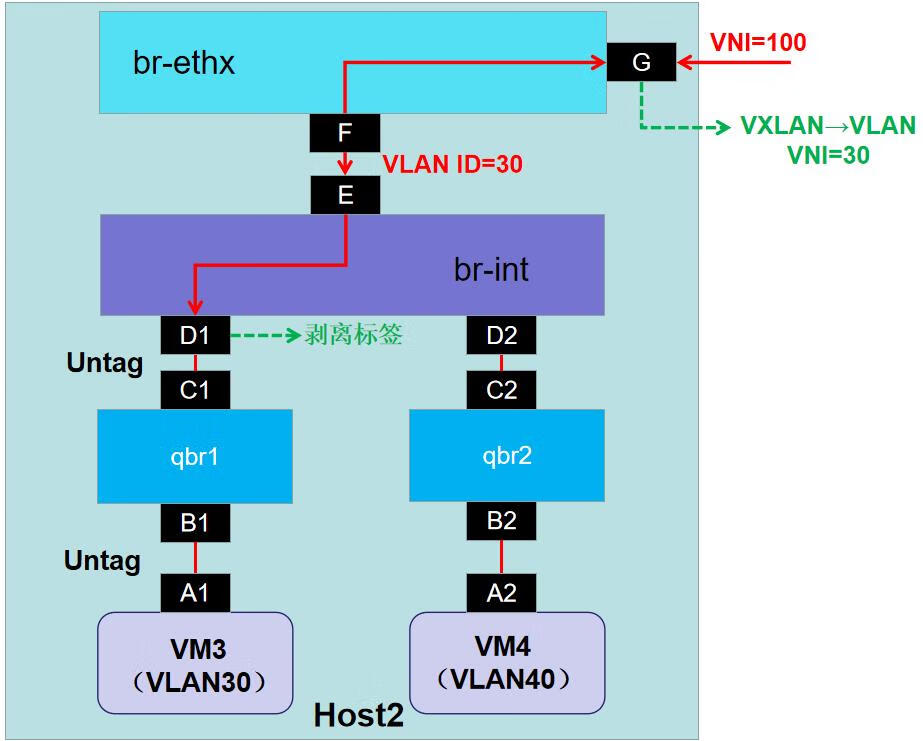
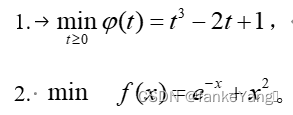Flink提供了丰富的客户端操作来提交任务和与任务进行交互。下面主要从Flink命令行、Scala Shell、SQL Client、Restful API和 Web五个方面进行整理。
在Flink安装目录的bin目录下可以看到flink,start-scala-shell.sh和sql-client.sh等文件,这些都是客户端操作的入口。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/0641e2577aab4433bdf972f8cc8250cc.png)
flink 常见操作:可以通过 -help 查看帮助
run 运行任务
-d:以分离模式运行作业
-c:如果没有在jar包中指定入口类,则需要在这里通过这个参数指定;
-m:指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager,可以说是yarn集群名称;
-p:指定程序的并行度。可以覆盖配置文件中的默认值;
-s:保存点savepoint的路径以还原作业来自(例如hdfs:///flink/savepoint-1537);
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID dce7b69ad15e8756766967c46122736f
就可以看到我们提交的JobManager,默认是一个并发。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/668711322ab84cb094da11a12ac990eb.png)
点进去就可以看到详细的信息
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/f0e73bf42a394838a8f74d2e2deb6400.png)
点击左侧TaskManager —Stdout能看到具体输出的日志信息。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/5229a6c1d4d6459dbb7b4cb5cef0f8d8.png)
或者查看TaskManager节点的log目录下的*.out文件,也能看到具体的输出信息。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/0c40b1ae05d140458cf205d6874d4d6a.png)
list 查看任务列表
-m:jobmanager<arg>作业管理器(主)的地址连接。
[root@hadoop1 flink-1.10.1]# bin/flink list -m 127.0.0.1:8081
Waiting for response...
------------------ Running/Restarting Jobs -------------------
09.07.2020 16:44:09 : dce7b69ad15e8756766967c46122736f : CarTopSpeedWindowingExample (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
Stop 停止任务
需要指定jobmanager的ip:prot和jobId。如下报错可知,一个job能够被stop要求所有的source都是可以stoppable的,即实现了 StoppableFunction接口。
[root@hadoop1 flink-1.10.1]# bin/flink stop -m 127.0.0.1:8081 dce7b69ad15e8756766967c46122736f
Suspending job "dce7b69ad15e8756766967c46122736f" with a savepoint.------------------------------------------------------------The program finished with the following exception:org.apache.flink.util.FlinkException: Could not stop with a savepoint job "dce7b69ad15e8756766967c46122736f".at org.apache.flink.client.cli.CliFrontend.lambda$stop$5(CliFrontend.java:458)
StoppableFunction接口如下,属于优雅停止任务。
/*** @Description 需要 stoppabel 的函数必须实现此接口,例如流式任务 source** stop() 方法在任务收到 stop信号的时候调用* source 在接收到这个信号后,必须停止发送新的数据优雅的停止。* @Date 2020/7/9 17:26*/@PublicEvolvingpublic interface StoppableFunction {/*** 停止 source,与 cancel() 不同的是,这是一个让 source优雅停止的请求。* 等待中的数据可以继续发送出去,不需要立即停止*/void stop();
}
Cancel 取消任务
如果在conf/flink-conf.yaml里面配置state.savepoints.dir,会保存savepoint,否则不会保存savepoint。(重启)
state.savepoints.dir: file:///tmp/savepoint
执行 Cancel命令 取消任务
[root@hadoop1 flink-1.10.1]# bin/flink cancel -m 127.0.0.1:8081 -s e8ce0d111262c52bf8228d5722742d47
DEPRECATION WARNING: Cancelling a job with savepoint is deprecated. Use "stop" instead.
Cancelling job e8ce0d111262c52bf8228d5722742d47 with savepoint to default savepoint directory.
Cancelled job e8ce0d111262c52bf8228d5722742d47. Savepoint stored in file:/tmp/savepoint/savepoint-e8ce0d-f7fa96a085d8.
也可以在停止的时候显示指定savepoint目录
1 [root@hadoop1 flink-1.10.1]# bin/flink cancel -m 127.0.0.1:8081 -s /tmp/savepoint f58bb4c49ee5580ab5f27fdb24083353
DEPRECATION WARNING: Cancelling a job with savepoint is deprecated. Use "stop" instead.
Cancelling job f58bb4c49ee5580ab5f27fdb24083353 with savepoint to /tmp/savepoint.
Cancelled job f58bb4c49ee5580ab5f27fdb24083353. Savepoint stored in file:/tmp/savepoint/savepoint-f58bb4-127b7e84910e.
取消和停止(流作业)的区别如下:
● cancel()调用, 立即调用作业算子的cancel()方法,以尽快取消它们。如果算子在接到cancel()调用后没有停止,Flink将开始定期中断算子线程的执行,直到所有算子停止为止。
● stop()调用 ,是更优雅的停止正在运行流作业的方式。stop()仅适用于source实现了StoppableFunction接口的作业。当用户请求停止作业时,作业的所有source都将接收stop()方法调用。直到所有source正常关闭时,作业才会正常结束。这种方式,使 作业正常处理完所有作业。
触发 savepoint
当需要生成savepoint文件时,需要手动触发savepoint。如下,需要指定正在运行的 JobID 和生成文件的存放目录。同时,我们也可以看到它会返回给用户存放的savepoint的文件名称等信息。
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/TopSpeedWindowing.jar Executing TopSpeedWindowing example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.Job has been submitted with JobID 216c427d63e3754eb757d2cc268a448d[root@hadoop1 flink-1.10.1]# bin/flink savepoint -m 127.0.0.1:8081 216c427d63e3754eb757d2cc268a448d /tmp/savepoint/Triggering savepoint for job 216c427d63e3754eb757d2cc268a448d.Waiting for response...Savepoint completed. Path: file:/tmp/savepoint/savepoint-216c42-154a34cf6bfdYou can resume your program from this savepoint with the run command.
savepoint和checkpoint的区别:
● checkpoint是增量做的,每次的时间较短,数据量较小,只要在程序里面启用后会自动触发,用户无须感知;savepoint是全量做的,每次的时间较长,数据量较大,需要用户主动去触发。
● checkpoint是作业failover的时候自动使用,不需要用户指定。savepoint一般用于程序的版本更新,bug修复,A/B Test等场景,需要用户指定。
从指定 savepoint 中启动
[root@hadoop1 flink-1.10.1]# bin/flink run -d -s /tmp/savepoint/savepoint-f58bb4-127b7e84910e/ examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 1a5c5ce279e0e4bd8609f541b37652e2
查看JobManager的日志能够看到Reset the checkpoint ID为我们指定的savepoint文件中的ID
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/4db15037b5554195a289c273572b4c7b.png)
modify 修改任务并行度
这里修改master的conf/flink-conf.yaml将task slot数修改为4。并通过xsync分发到 两个slave节点上。
taskmanager.numberOfTaskSlots: 4
修改参数后需要重启集群生效:关闭/启动集群
[root@hadoop1 flink-1.10.1]# bin/stop-cluster.sh && bin/start-cluster.sh
Stopping taskexecutor daemon (pid: 8236) on host hadoop2.
Stopping taskexecutor daemon (pid: 8141) on host hadoop3.
Stopping standalonesession daemon (pid: 22633) on host hadoop1.
Starting cluster.
Starting standalonesession daemon on host hadoop1.
Starting taskexecutor daemon on host hadoop2.
Starting taskexecutor daemon on host hadoop3.
启动任务
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 2e833a438da7d8052f14d5433910515a
从页面上能看到Task Slots总计变为了8,运行的Slot为1,剩余Slot数量为7。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/a3840dc2c17f411e901d20419435b7af.png)
这时候默认的并行度是1
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/30e6676adc0c4e7e8d8fe2bfb9a15128.png)
Flink1.0版本命令行flink modify已经没有这个行为了,被移除了。。。Flink1.7上是可以运行的。
[root@hadoop1 flink-1.10.1]# bin/flink modify -p 4 cc22cc3d09f5d65651d637be6fb0a1c3
"modify" is not a valid action.
Info 显示程序的执行计划
[root@hadoop1 flink-1.10.1]# bin/flink info examples/streaming/TopSpeedWindowing.jar
----------------------- Execution Plan -----------------------
{"nodes":[{"id":1,"type":"Source: Custom Source","pact":"Data Source","contents":"Source: Custom Source","parallelism":1},{"id":2,"type":"Timestamps/Watermarks","pact":"Operator","contents":"Timestamps/Watermarks","parallelism":1,"predecessors":[{"id":1,"ship_strategy":"FORWARD","side":"second"}]},{"id":4,"type":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)","pact":"Operator","contents":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)","parallelism":1,"predecessors":[{"id":2,"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":1,"predecessors":[{"id":4,"ship_strategy":"FORWARD","side":"second"}]}]}
--------------------------------------------------------------
拷贝输出的json内容,粘贴到这个网站:http://flink.apache.org/visualizer/可以生成类似如下的执行图。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/f691bb698954496b8f0dd957c86d0cd9.png)
可以与实际运行的物理执行计划进行对比。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/3e520b005fcc4ba8abf894fab4ec924c.png)
SQL Client Beta
进入 Flink SQL
[root@hadoop1 flink-1.10.1]# bin/sql-client.sh embedded
Select查询,按Q退出如下界面;
Flink SQL> select 'hello word';SQL Query Result (Table)Table program finished. Page: Last of 1 Updated: 16:37:04.649EXPR$0hello wordQ Quit + Inc Refresh G Goto Page N Next Page O Open Row
R Refresh - Dec Refresh L Last Page P Prev Page
打开http://hadoop1:8081能看到这条select语句产生的查询任务已经结束了。这个查询采用的是读取固定数据集的Custom Source,输出用的是Stream Collect Sink,且只输出一条结果。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/8f7df91d86a0494fa84962471ba16f02.png)
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/845f52fc8c6e401da5be70008d3a62a5.png)
explain 查看 SQL 的执行计划。
Flink SQL> explain SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
== Abstract Syntax Tree == //抽象语法树
LogicalAggregate(group=[{0}], cnt=[COUNT()])
+- LogicalValues(type=[RecordType(VARCHAR(5) name)], tuples=[[{ _UTF-16LE'Bob' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg' }, { _UTF-16LE'Bob' }]])== Optimized Logical Plan == //优化后的逻辑执行计划
GroupAggregate(groupBy=[name], select=[name, COUNT(*) AS cnt])
+- Exchange(distribution=[hash[name]])+- Values(type=[RecordType(VARCHAR(5) name)], tuples=[[{ _UTF-16LE'Bob' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg' }, { _UTF-16LE'Bob' }]])== Physical Execution Plan == //物理执行计划
Stage 13 : Data Sourcecontent : Source: Values(tuples=[[{ _UTF-16LE'Bob' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg' }, { _UTF-16LE'Bob' }]])Stage 15 : Operatorcontent : GroupAggregate(groupBy=[name], select=[name, COUNT(*) AS cnt])ship_strategy : HASH
结果展示
SQL Client支持两种模式来维护并展示查询结果:
table mode
在内存中物化查询结果,并以分页table形式展示。用户可以通过以下命令启用table mode:例如如下案例;
Flink SQL> SET execution.result-mode=table;
[INFO] Session property has been set.Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;SQL Query Result (Table)Table program finished. Page: Last of 1 Updated: 16:55:08.589name cntAlice 1Greg 1Bob 2Q Quit + Inc Refresh G Goto Page N Next Page O Open Row
R Refresh - Dec Refresh L Last Page P Prev Page
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/c7412859eabf4b3fad3ddb2cccfc710a.png)
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/1087d007317045dcaa030439ca6b627d.png)
changelog mode
不会物化查询结果,而是直接对continuous query产生的添加和撤回retractions结果进行展示:如下案例中的-表示撤回消息
Flink SQL> SET execution.result-mode=changelog;
[INFO] Session property has been set.Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;SQL Query Result (Changelog)Table program finished. Updated: 16:58:05.777+/- name cnt+ Bob 1+ Alice 1+ Greg 1- Bob 1+ Bob 2Q Quit + Inc Refresh O Open Row
R Refresh - Dec Refresh
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/374f6f2c91a3467683fc7c43959dcaae.png)
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/e97f9ece7ebc4cc292b619996a030755.png)
Environment Files
CREATE TABLE 创建表DDL语句:
Flink SQL> CREATE TABLE pvuv_sink (
> dt VARCHAR,
> pv BIGINT,
> uv BIGINT
> ) ;
[INFO] Table has been created.
SHOW TABLES 查看所有表名
Flink SQL> show tables;
pvuv_sink
DESCRIBE 表名 查看表的详细信息;
Flink SQL> describe pvuv_sink;
root|-- dt: STRING|-- pv: BIGINT|-- uv: BIGINT
插入等操作均与关系型数据库操作语句一样,省略N个操作
Restful API
接下来我们演示如何通过rest api来提交jar包和执行任务。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/4952f119ae2a4bf692e62fb5d85ec0fd.png)
通过Show Plan可以看到执行图
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/339bf285020b462b82ea13836b939fd4.png)
提交之后的操作,取消的话点击页面的Cancel Job
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/a1011c88daf04744967d1cc2c2e23848.png)