文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
- 1、创建Maven项目
- 2、添加相关依赖
- 3、创建日志属性文件
- 4、创建学生实体类
- 5、创建科目平均分映射器类
- 6、创建科目平均分归并器类
- 7、创建科目平均分驱动器类
- 8、启动应用,查看结果
一、实战概述
-
在本次实战中,我们将利用Hadoop MapReduce处理学生月考成绩数据,目标是计算每个同学语文、数学和英语的平均分。通过启动Hadoop服务、准备数据、创建Maven项目以及实现Mapper、Reducer和Driver类,我们将深入实践大数据处理流程。此任务将帮助我们理解MapReduce的工作原理,并提升大数据分析能力。一起来探索分布式计算的力量,揭示隐藏在海量数据中的学习表现趋势。
-
我们首先启动Hadoop服务,并在虚拟机上创建包含语文、数学、英语成绩的文本文件
chinese.txt、math.txt和english.txt。然后,我们将这三个文件上传到HDFS的/subjectavg/input目录。 -
接下来,我们通过Maven创建一个名为
SubjectAvg的项目,并添加hadoop和junit依赖。在项目中,我们创建了日志属性文件log4j.properties以配置日志输出。 -
为了处理数据,我们创建了学生实体类
Student,该类实现了Writable接口,以便在Mapper和Reducer中使用。在Student类中,我们定义了姓名、语文、数学和英语成绩的属性以及相关的getter和setter方法。 -
我们还创建了科目平均分映射器类
SubjectAvgMapper,该类继承自Mapper<LongWritable, Text, Text, Student>。在map方法中,我们获取文件切片对象以确定读取的是哪个科目成绩文件,然后解析输入行并创建Student对象,根据科目设置相应的成绩。 -
科目平均分归并器类
SubjectAvgReducer继承自Reducer<Text, Student, Text, Student>。在reduce方法中,我们遍历学生迭代器,累加各科成绩,然后计算平均分并更新Student对象。 -
最后,我们创建了科目平均分驱动器类
SubjectAvgDriver,在其中设置了作业的相关配置,包括Mapper类、Reducer类、输入路径和输出路径。通过运行此驱动器类,我们可以得到每个同学各科的平均分。
二、提出任务
- 语文月考成绩 -
chinese.txt
1 张晓云 89
2 张晓云 73
3 张晓云 67
4 张晓云 70
5 张晓云 79
6 张晓云 87
7 张晓云 99
8 张晓云 83
9 张晓云 97
10 张晓云 92
11 张晓云 67
12 张晓云 86
1 王东林 49
2 王东林 83
3 王东林 67
4 王东林 49
5 王东林 93
6 王东林 87
7 王东林 65
8 王东林 92
9 王东林 60
10 王东林 94
11 王东林 81
12 王东林 90
1 李宏宇 77
2 李宏宇 66
3 李宏宇 89
4 李宏宇 87
5 李宏宇 96
6 李宏宇 79
7 李宏宇 87
8 李宏宇 96
9 李宏宇 69
10 李宏宇 87
11 李宏宇 96
12 李宏宇 79
- 数学月考成绩 -
math.txt
1 张晓云 79
2 张晓云 83
3 张晓云 77
4 张晓云 90
5 张晓云 89
6 张晓云 67
7 张晓云 89
8 张晓云 93
9 张晓云 90
10 张晓云 82
11 张晓云 77
12 张晓云 96
1 王东林 78
2 王东林 94
3 王东林 76
4 王东林 70
5 王东林 90
6 王东林 83
7 王东林 85
8 王东林 82
9 王东林 84
10 王东林 78
11 王东林 99
12 王东林 93
1 李宏宇 86
2 李宏宇 81
3 李宏宇 76
4 李宏宇 93
5 李宏宇 88
6 李宏宇 82
7 李宏宇 81
8 李宏宇 93
9 李宏宇 86
10 李宏宇 90
11 李宏宇 67
12 李宏宇 88
- 英语月考成绩 -
english.txt
1 张晓云 78
2 张晓云 83
3 张晓云 92
4 张晓云 66
5 张晓云 82
6 张晓云 89
7 张晓云 79
8 张晓云 68
9 张晓云 96
10 张晓云 91
11 张晓云 87
12 张晓云 82
1 王东林 69
2 王东林 86
3 王东林 73
4 王东林 99
5 王东林 67
6 王东林 95
7 王东林 74
8 王东林 92
9 王东林 76
10 王东林 88
11 王东林 92
12 王东林 56
1 李宏宇 88
2 李宏宇 78
3 李宏宇 92
4 李宏宇 78
5 李宏宇 89
6 李宏宇 76
7 李宏宇 92
8 李宏宇 75
9 李宏宇 88
10 李宏宇 92
11 李宏宇 97
12 李宏宇 85
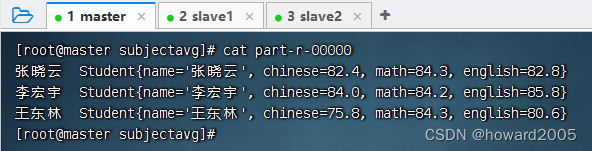
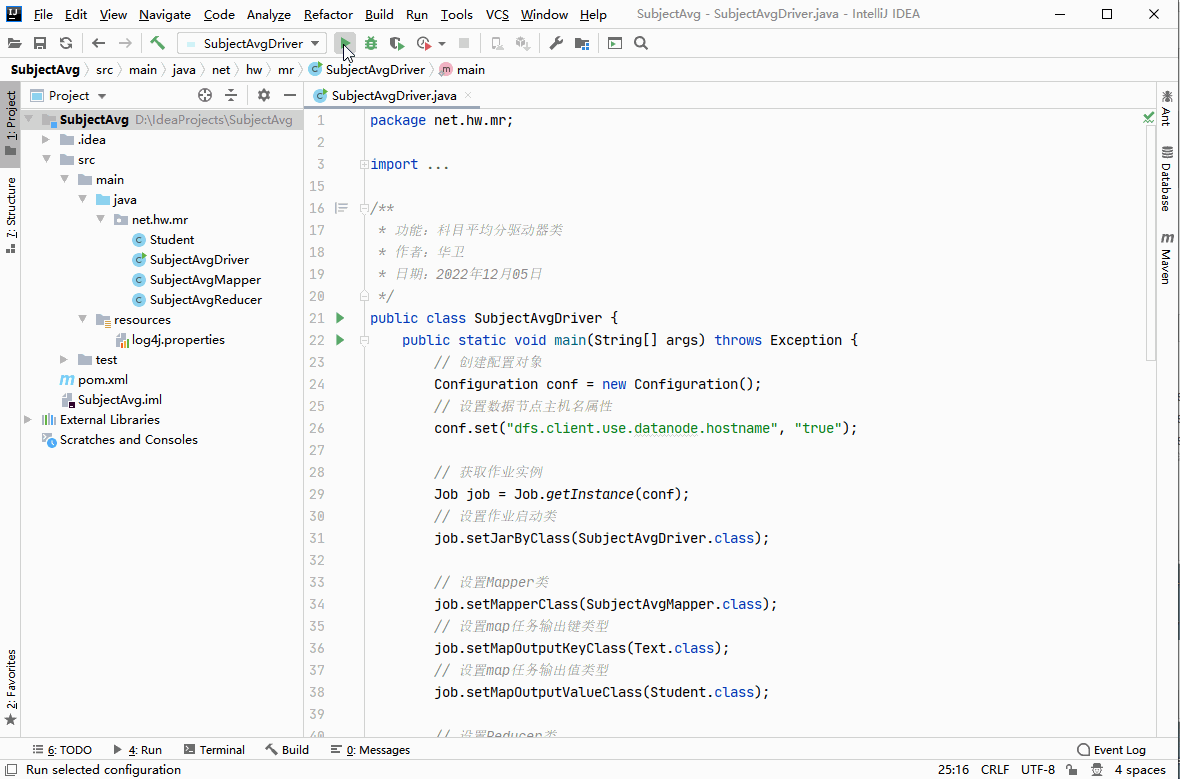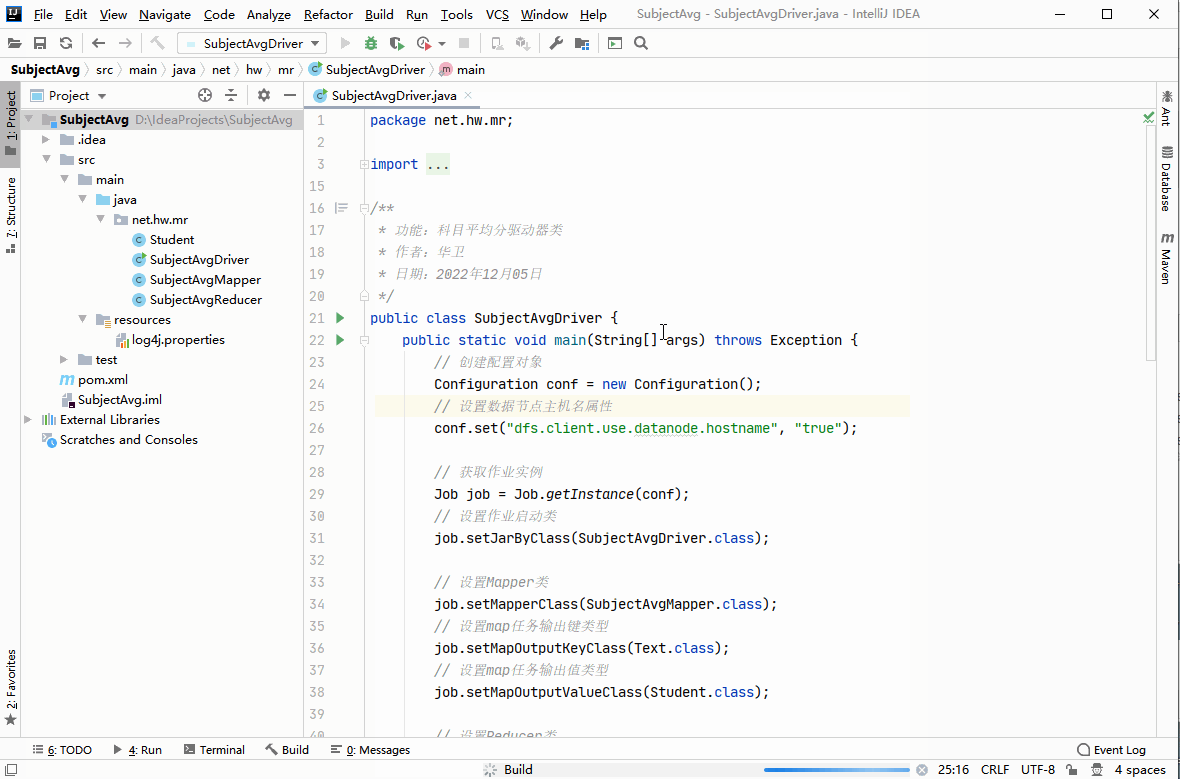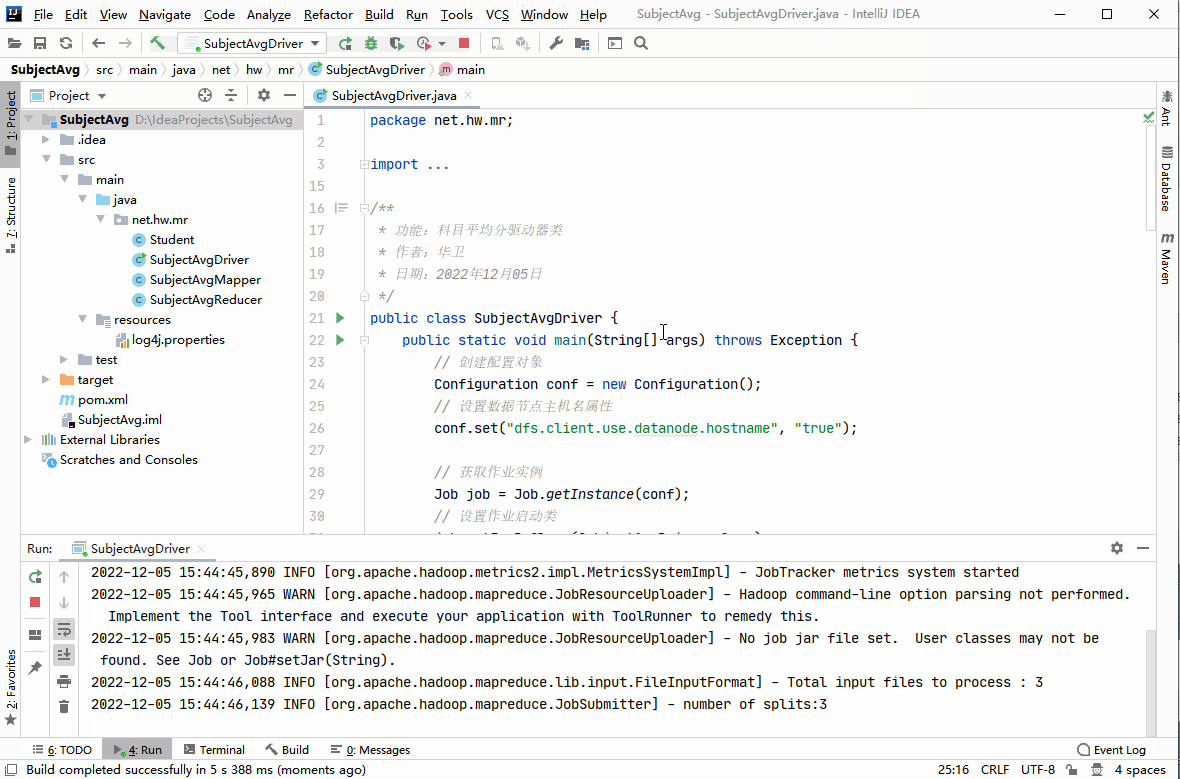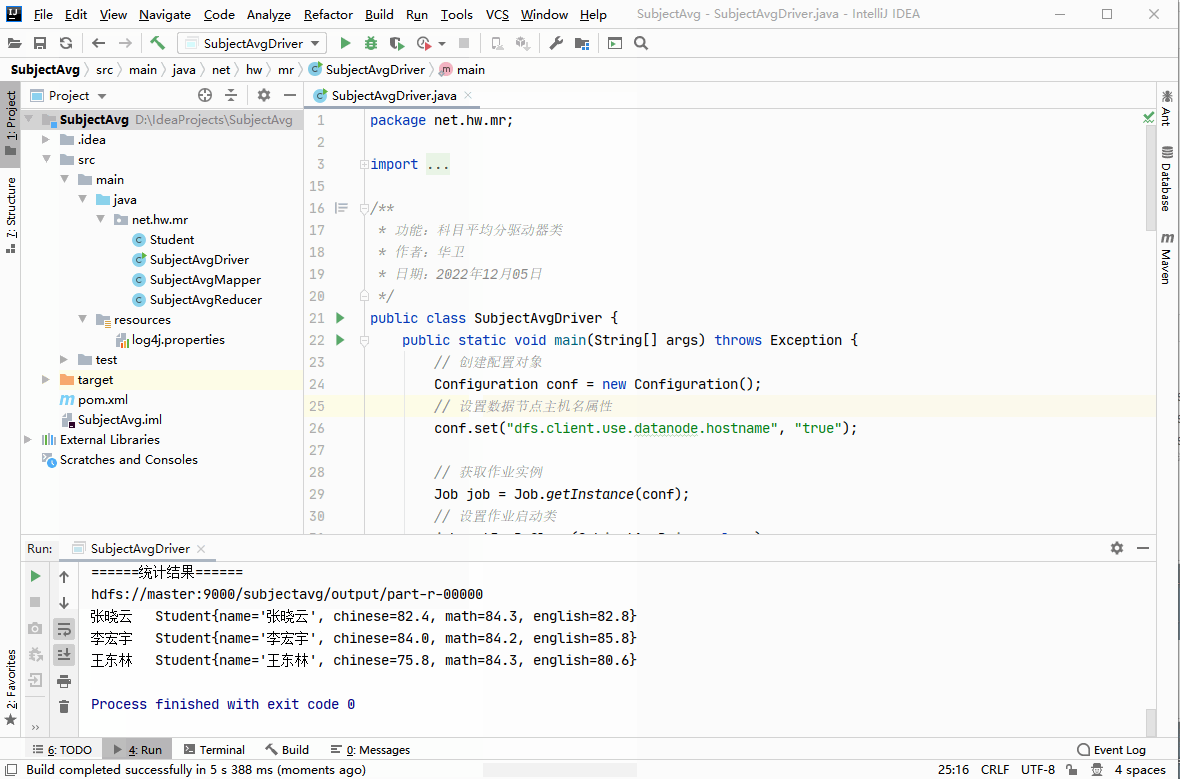
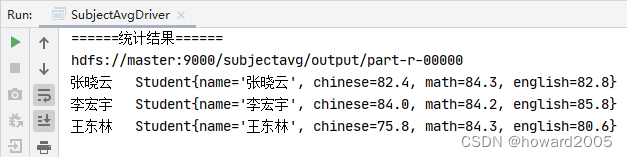
- 统计每个同学各科月考平均分
张晓云 Student{name='张晓云', chinese=82.4, math=84.3, english=82.8}
李宏宇 Student{name='李宏宇', chinese=84.0, math=84.2, english=85.8}
王东林 Student{name='王东林', chinese=75.8, math=84.3, english=80.6}
三、完成任务
(一)准备数据
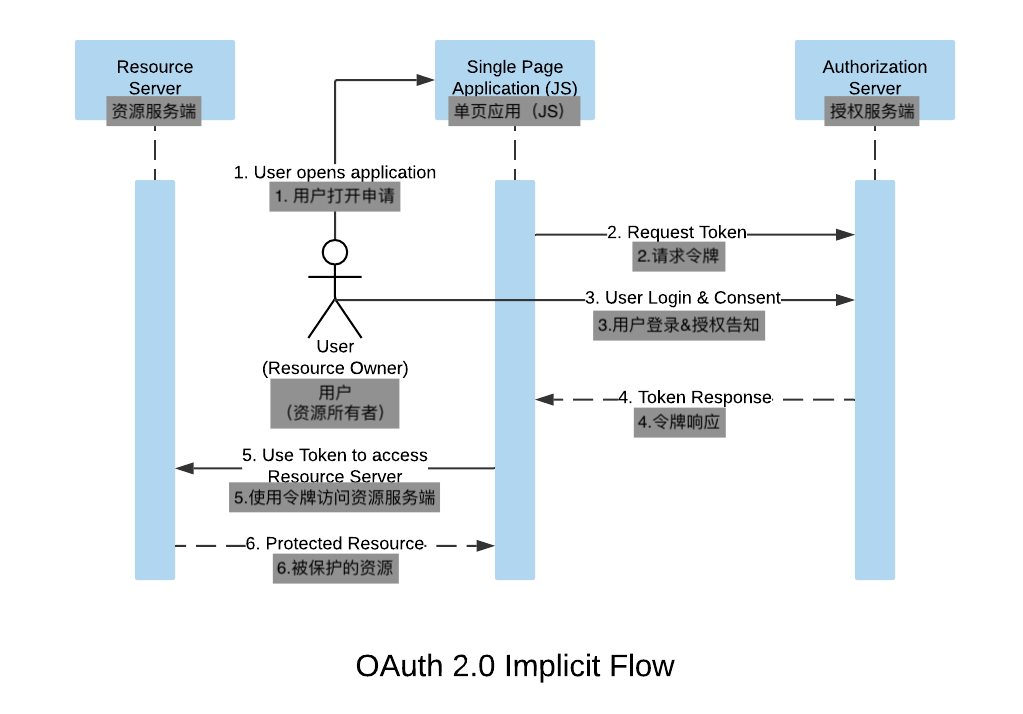
- 启动hadoop服务
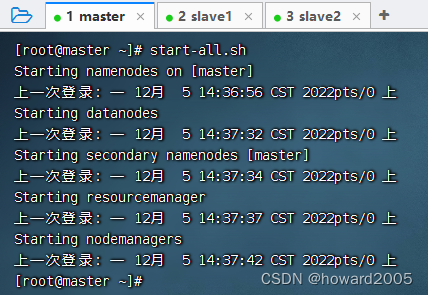
1、在虚拟机上创建文本文件
- 创建
subjectavg目录,在里面创建chinese.txt文件(数据没有显示全)
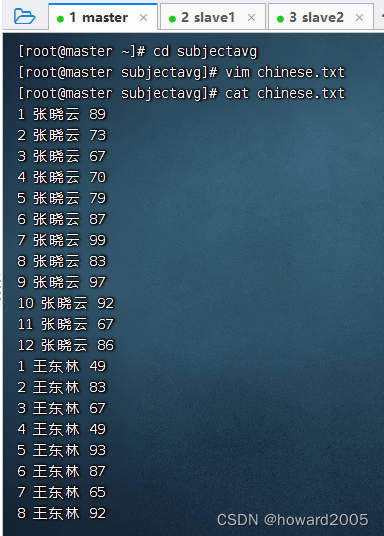
- 创建
math.txt(数据没有显示全)
- 创建
english.txt(数据没有显示全)
2、上传文件到HDFS指定目录
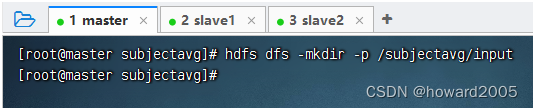
- 创建
/subjectavg/input目录,执行命令:hdfs dfs -mkdir -p /subjectavg/input
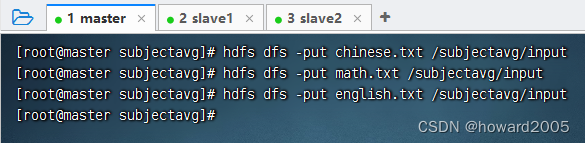
- 将文本文件
chinese.txt、math.txt与english.txt,上传到HDFS的/subjectavg/input目录
(二)实现步骤
1、创建Maven项目
- Maven项目 -
SubjectAvg
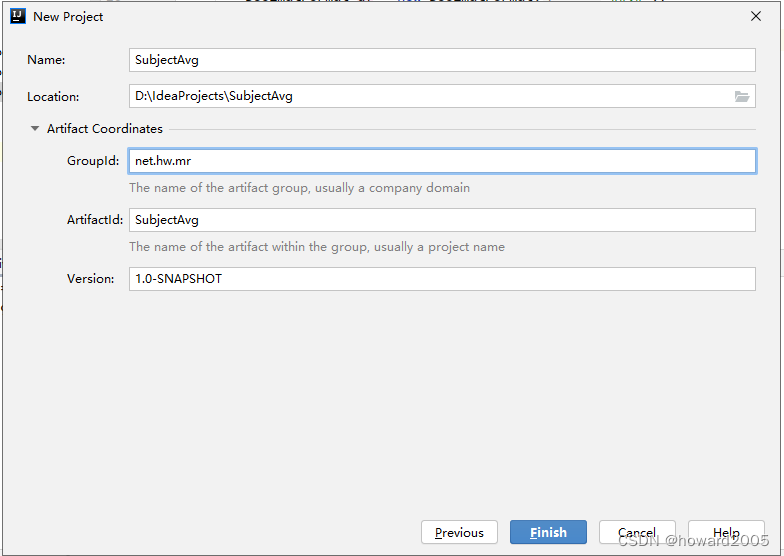
- 单击【Finish】按钮
2、添加相关依赖
- 在
pom.xml文件里添加hadoop和junit依赖
<dependencies> <!--hadoop客户端--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--单元测试框架--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency>
</dependencies>
3、创建日志属性文件
- 在
resources目录里创建log4j.properties文件
log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/subjectavg.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、创建学生实体类
- 在
net.hw.mr包里创建Student类

- 注意:学生实体类必须实现
Writable接口,才能作为Mapper和Reducer的输出值类型
package net.hw.mr;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;/*** 功能:学生实体类* 作者:华卫* 日期:2022年12月05日*/
public class Student implements Writable {private String name;private double chinese;private double math;private double english;public String getName() {return name;}public void setName(String name) {this.name = name;}public double getChinese() {return chinese;}public void setChinese(double chinese) {this.chinese = chinese;}public double getMath() {return math;}public void setMath(double math) {this.math = math;}public double getEnglish() {return english;}public void setEnglish(double english) {this.english = english;}public void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(name);dataOutput.writeDouble(chinese);dataOutput.writeDouble(math);dataOutput.writeDouble(english);}public void readFields(DataInput dataInput) throws IOException {name = dataInput.readUTF();chinese = dataInput.readDouble();math = dataInput.readDouble();english = dataInput.readDouble();}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", chinese=" + chinese +", math=" + math +", english=" + english +'}';}
}
5、创建科目平均分映射器类
- 在
net.hw.mr包里创建SubjectAvgMapper类
- 由于MR程序读取
/subjectavg/input目录里的三个科目成绩文件,在Mapper获取文件切片时就要区分读取的是哪一个文件,可以通过context的getInputSplit()方法获得文件切片对象,由此可以获取该切片对应的文件名,从而知道读取的是哪一科的成绩文件。
package net.hw.mr;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;/*** 功能:科目平均分映射器类* 作者:华卫* 日期:2022年12月05日*/
public class SubjectAvgMapper extends Mapper<LongWritable, Text, Text, Student> {@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 获取文件切片对象(将输入切片强转成文件切片)FileSplit split = (FileSplit) context.getInputSplit();// 获取文件切片对应的文件名String filename = split.getPath().getName();// 拆分行获取成绩数据String line = value.toString();String[] data = line.split(" ");String name = data[1];int score = Integer.parseInt(data[2]);// 创建学生实体Student student = new Student();// 设置姓名属性student.setName(name);// 根据读取文件名来设置相应科目成绩if (filename.contains("chinese")) {student.setChinese(score);} else if (filename.contains("math")) {student.setMath(score);} else if (filename.contains("english")){student.setEnglish(score);}context.write(new Text(name), student);}
}
6、创建科目平均分归并器类
- 在
net.hw.mr包里创建SubjectAvgReducer类
package net.hw.mr;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.text.DecimalFormat;/*** 功能:科目平均分归并器类* 作者:华卫* 日期:2022年12月05日*/
public class SubjectAvgReducer extends Reducer<Text, Student, Text, Student> {@Overrideprotected void reduce(Text key, Iterable<Student> values, Context context) throws IOException, InterruptedException {// 创建学生对象Student student = new Student();// 设置姓名属性student.setName(key.toString());// 遍历学生迭代器,累加各科成绩for (Student value : values) {student.setChinese(student.getChinese() + value.getChinese());student.setMath(student.getMath() + value.getMath());student.setEnglish(student.getEnglish() + value.getEnglish());}// 求各科平均分DecimalFormat df = new DecimalFormat("##.#");student.setChinese(Double.parseDouble(df.format(student.getChinese() / 12)));student.setMath(Double.parseDouble(df.format(student.getMath() / 12)));student.setEnglish(Double.parseDouble(df.format(student.getEnglish() / 12)));// 输出处理后的键值对context.write(key, student);}
}
7、创建科目平均分驱动器类
- 在
net.hw.mr包里创建SubjectAvgDriver类

package net.hw.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** 功能:成绩和驱动器类* 作者:华卫* 日期:2022年12月02日*/
public class ScoreSumDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(ScoreSumDriver.class);// 设置Mapper类job.setMapperClass(ScoreSumMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(IntWritable.class);// 设置Reducer类job.setReducerClass(ScoreSumReducer.class);// 设置reduce任务输出键类型job.setOutputKeyClass(Text.class);// 设置reduce任务输出值类型job.setOutputValueClass(NullWritable.class);// 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/scoresum/input");// 创建输出目录Path outputPath = new Path(uri + "/scoresum/output");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录(第二个参数设置是否递归)fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录(只能一个)FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件系统数据字节输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
8、启动应用,查看结果
-
运行
SubjectAvgDriver类
-
下载结果文件 -
part-r-00000

-
查看结果文件 -
part-r-00000