1、Kubernetes概述
k8s缩写是因为k和s之间有八个字符。k8s是基于容器技术的分布式架构方案。官网:https://kubernetes.io/zh-cn/
Google在 2014年开源了Kubernetes项目,Kubernetes是一个用于自动化部署、扩展和管理容器化应用程序的开源系统。同样类似的容器编排工具还有docker swarm等,但kubernetes应用最为广泛,社区更为活跃。
为什么要使用 Kubernetes?
当你的应用只是跑在一台机器,直接一个 docker + docker compose 就够了,方便轻松;
当你的应用需要跑在 3,4 台机器上,你依旧可以每台机器单独配置运行环境 + 负载均衡;
当你应用访问数不断增加,机器逐渐增加到十几台、上百台、上千台时,每次加机器、软件更新、版本回滚,都会变得非常麻烦。单机走向集群已成为必然,这时Kubernetes 就可以一展身手了。
Kubernetes是一个开放的开发平台。没有限定任何编程接口,因此不管是Java、Go、C++仍是用Python编写的服务,均可以毫无困难地映射为Kubernetes的Service,并经过标准的TCP协议进行交互。此外,因为Kubernetes平台对现有的编程语言、编程框架、中间件没有任何侵入性,所以现有的系统很容易改造升级并迁移到Kubernetes平台上。
项目部署的发展历程,经历了物理机、虚拟机、容器化三个阶段的演变。
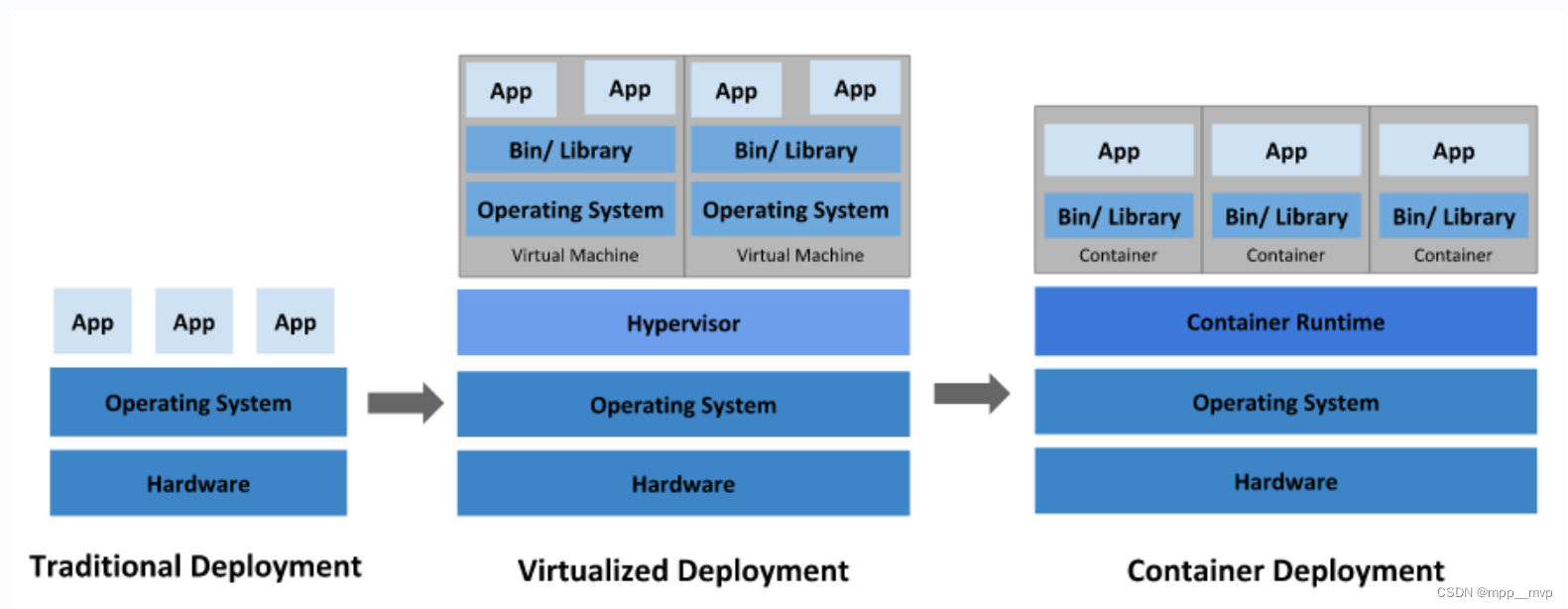
1、传统部署时代
早期,应用程序直接在物理服务器上运行,无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,结果可能导致其他应用程序的性能下降。一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展,并且维护许多物理服务器的成本很高。
2、虚拟化部署时代
为了解决物理机存在的弊端,引入了虚拟化技术,支持在单个物理服务器的CPU上运行多个虚拟机(VM),每个VM是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。虚拟化技术允许应用程序在VM之间隔离,提供一定程度的安全,一个应用程序的信息不能被另一应用程序随意访问。虚拟化技术能够更好地利用物理服务器上的资源,由于可轻松地添加或更新应用程序而实现更好的可伸缩性,降低了硬件成本。
3、容器部署时代
容器类似于VM,但是具有被放宽的隔离属性,可以在应用程序之间共享操作系统,因此容器被认为是轻量级的隔离。容器与VM类似,具有自己的文件系统、CPU、内存、进程空间等,由于它们与基础架构分离,因此可以跨云和操作系统发行版本进行移植。
随着微服务、容器化等技术的发展,解决了资源利用率不高的问题,但是随之而来却是如何进行容器管理,过多的容器使得运维工作也成为了一种负担,因此容器编排对于大型依托于容器化部署的分布式系统至关重要。在容器编排方面,Kubernetes所扮演的角色如下图所示:
Kubernetes相当于在容器之上,对服务器资源以及容器调度等过程进行管理。

Kubernetes设计架构,官方架构设计图:
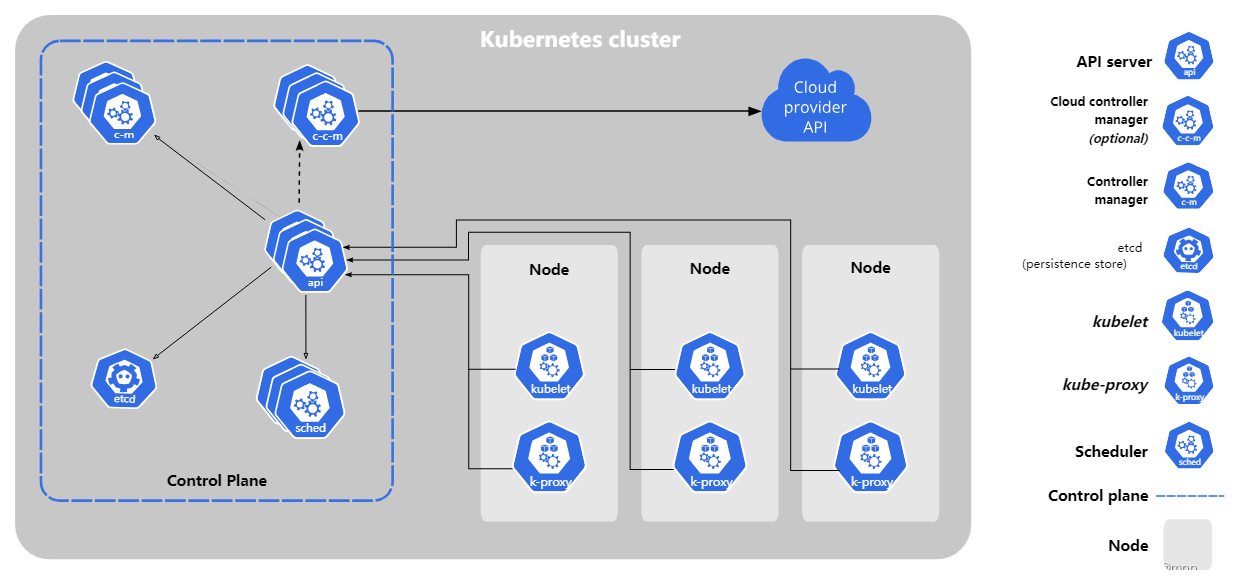
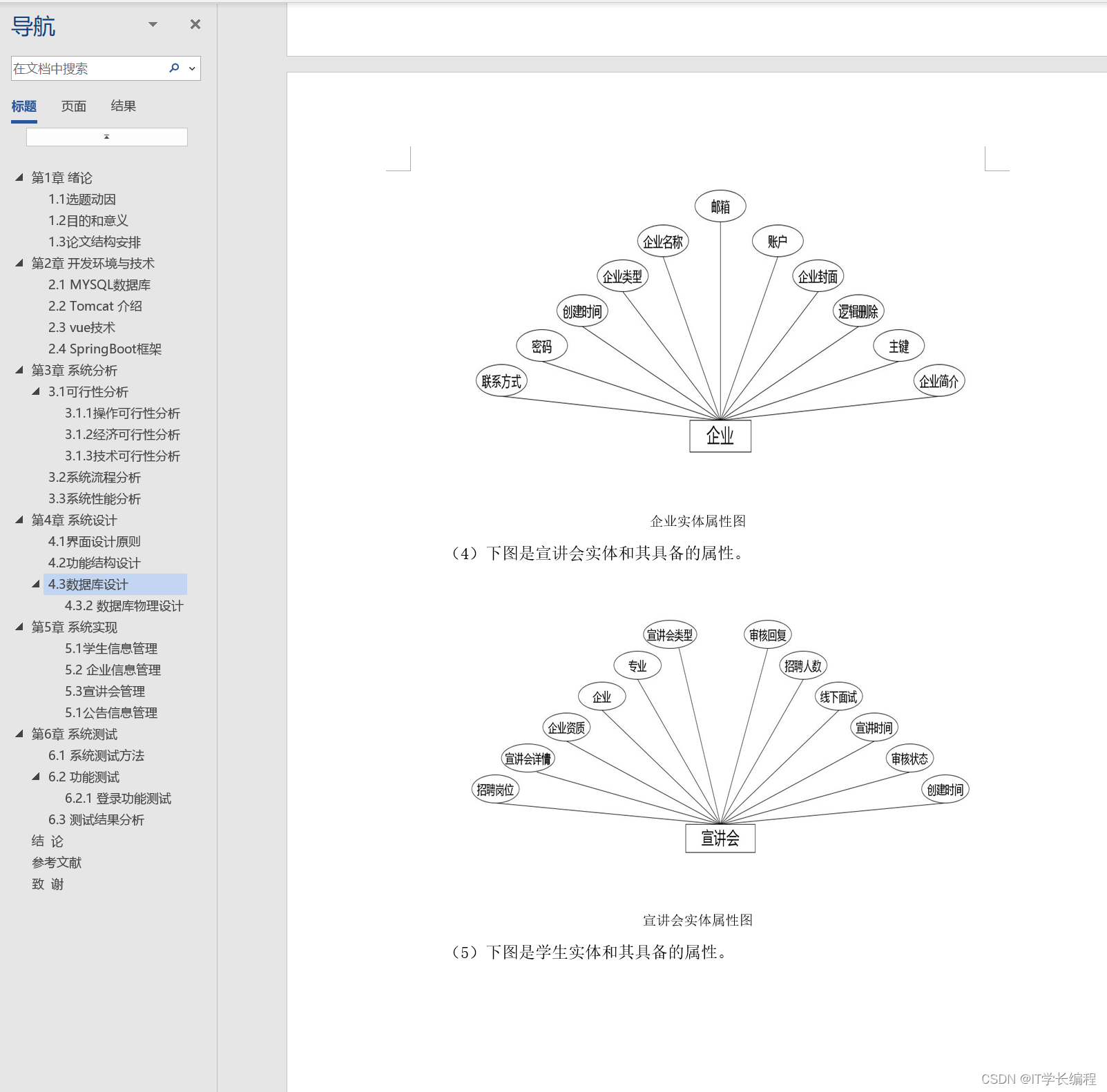
1、kube-apiserver:通过 API与Kubernetes 集群进行交互。Kubernetes API 是 Kubernetes 控制平面的前端,用于处理内部和外部请求。API 服务器会确定请求是否有效,如果有效,则对其进行处理。可以通过 REST 调用、kubectl 命令行界面或其他命令行工具(例如 kubeadm)来访问 API。
2、kube-scheduler:Kubernetes 调度程序会考虑容器集的资源需求(例如 CPU 或内存)以及集群的运行状况。它会将容器集安排到适当的计算节点。
3、kube-controller-manager:控制器负责实际运行集群,控制器用于查询调度程序,并确保有正确数量的容器集在运行。如果有容器集停止运行,另一个控制器会发现并做出响应。控制器会将服务连接至容器集,以便让请求前往正确的端点。还有一些控制器用于创建帐户和 API 访问令牌。
4、etcd:配置数据以及有关集群状态的信息位于 etcd(一个键值key-value存储数据库)中。
5、容器集Pod:容器集是 Kubernetes 对象模型中最小、最简单的单元。它代表了应用的单个实例。每个容器集都由一个容器(或一系列紧密耦合的容器)以及若干控制容器运行方式的选件组成。容器集可以连接至持久存储,以运行有状态应用。
6、kubelet:每个计算节点中都包含一个 kubelet,这是一个与控制平面通信的微型应用。kubelet 可确保容器在容器集内运行。当控制平面需要在节点中执行某个操作时,kubelet 就会执行该操作。
7、kube-proxy:每个计算节点中还包含 kube-proxy,这是一个用于优化 Kubernetes 网络服务的网络代理。kube-proxy 负责处理集群内部或外部的网络通信。
Minikube安装
minikube基于go语言开发,可以在单机环境下快速搭建可用的k8s集群,快速启动消耗机器资源较少,非常适合测试和本地开发,现有的大部分在线k8s实验环境也是基于minikube的。
Minikube架构,master 节点与其它节点合为一体,而整体则通过宿主机上的 kubectl 进行管理,这样可以更加节省资源。
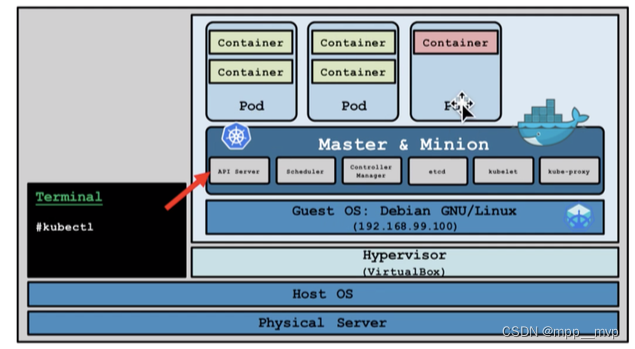
Minikube 支持 Windows、macOS、Linux 三种 OS,会根据平台不同,下载对应的虚拟机镜像,并在镜像内安装 K8S。
这里直接使用 Windows 安装minikube。
1、docker安装
1、下载地址:https://docs.docker.com/desktop/install/windows-install/
2、双击下载的 Docker for Windows Installer 安装文件,一路 Next,点击 Finish 完成安装。
3、安装好之后会重启电脑
2、安装minikube
1、minikube下载地址 https://minikube.sigs.k8s.io/docs/start/ ,下载 minikube.exe双击运行安装,
https://github.com/kubernetes/minikube/releases/latest/download/minikube-windows-amd64.exe
2、配置系统环境变量path,添加minikube.exe到path中,C:\minikube
3、命令行测试,需要保证docker启动
启动minikube,minikube start,minikube version,minikube status,minikube ip
4、进入minikube,docker环境,minikube ssh,docker ps
5、k8s命令kubectl,kubectl get nodes,kubectl get pods -A
6、停止minikube,minikube stop
2、裸机手动搭建K8S集群
1、三台VM一主二从,每台4颗cpu内存4G,NAT模式,10.1.1.111(master),10.1.1.112(node1),10.1.1.113(node2)
2、三台VM都要先安装docker
卸载旧的docker
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine
配置yum源、下载docker-ce.repo
yum install -y yum-utils
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装docker
yum install -y docker-ce docker-ce-cli containerd.io
配置阿里云镜像加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://qiyb9988.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
启动Docker
sudo systemctl start docker
设置开机自启动Docker
sudo systemctl enable docker
查看版本
docker version
3、安装k8s前的系统环境准备,官方要求的
每台节点设置不同的hostname
hostnamectl set-hostname masternew
hostnamectl set-hostname node1new
hostnamectl set-hostname node2new关闭防火墙,允许节点之间通信
systemctl stop firewalld
systemctl disable firewalld禁用selinux
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config 关闭swap分区
sudo swapoff -a
sudo sed -ri 's/.*swap.*/#&/' /etc/fstab允许 iptables 检查桥接流量(所有节点)
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOFcat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF重新加载配置文件
sudo sysctl --system
4、安装k8s集群三大组件 kubeadm、kubelet、kubectl
需要在每台机器上安装以下的软件包:
1、kubeadm:用来初始化集群的指令。
2、kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
3、kubectl:用来与集群通信的命令行工具。
参考阿里巴巴开源镜像站Kubernetes安装步骤:https://developer.aliyun.com/mirror/kubernetes
# 安装 kubeadm、kubelet 和 kubectl,配置yum文件,因为国内无法直接访问google,这里需要将官网中的google的源改为国内源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOFsetenforce 0
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet && systemctl start kubelet# 查看版本信息
kubectl version
5、安装cri环境(要先确保docker是启动的)
在 Kubernetes v1.24 及更早版本中,我们使用docker作为容器引擎在k8s上使用时,依赖一个dockershim的内置k8s组件;k8s v1.24发行版中将dockershim组件给移除了;取而代之的就是cri-dockerd(当然还有其它容器接口);简单讲CRI就是容器运行时接口(Container Runtime Interface,CRI),也就是说cri-dockerd就是以docker作为容器引擎而提供的容器运行时接口;即我们想要用docker作为k8s的容器运行引擎,我们需要先部署好cri-dockerd;用cri-dockerd来与kubelet交互,然后再由cri-dockerd和docker api交互,使我们在k8s能够正常使用docker作为容器引擎;
# 下载cri-docker
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.4/cri-dockerd-0.3.4.amd64.tgz# 解压cri-docker
tar xvf cri-dockerd-*.amd64.tgz
cp -r cri-dockerd/ /usr/bin/
chmod +x /usr/bin/cri-dockerd/cri-dockerd# 写入启动cri-docker配置文件
cat > /usr/lib/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process[Install]
WantedBy=multi-user.target
EOF# 写入cri-docker的socket配置文件
cat > /usr/lib/systemd/system/cri-docker.socket <<EOF
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker[Install]
WantedBy=sockets.target
EOF# 重新加载配置文件(如.service文件、socket文件等)
systemctl daemon-reload
# 启用并立即启动cri-docker.service
systemctl enable --now cri-docker.service
# 查看cri-docker.service运行状态
systemctl status cri-docker.service
6、安装并初始化master节点
# 所有节点添加master节点的域名映射
echo "10.1.1.111 masternew" >> /etc/hosts
# node节点ping测试映射是否成功
ping masternew
# 如果init初始化master失败,可以kubeadm重置,kubeadm:用来初始化集群的指令。
kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
# 只有主节点master初始化(只在master执行)
# 注意修改apiserver的地址为master节点的ip
# 注意service-cidr、pod-network-cidr的网络节点不能和master网络ip重叠(service网络、pod网络不要和宿主机一样)
kubeadm init \
--apiserver-advertise-address=10.1.1.111 \
--control-plane-endpoint=masternew \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.28.2 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.169.0.0/16 \
--cri-socket unix:///var/run/cri-dockerd.sock
等待命令运行完毕即可,执行成功后可以看到会返回一些命令,按照提示执行这些命令即可。
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:kubeadm join masternew:6443 --token 7izf2l.1ssrdhqux2vyradb \--discovery-token-ca-cert-hash sha256:c6995cbd84c701ef6ba2eff481d43b7ad3c2c1e49387a9c6f7bdc36c97ad590c \--control-plane # control-plane控制节点,这是加入控制节点命令Then you can join any number of worker nodes by running the following on each as root:kubeadm join masternew:6443 --token 7izf2l.1ssrdhqux2vyradb \--discovery-token-ca-cert-hash sha256:c6995cbd84c701ef6ba2eff481d43b7ad3c2c1e49387a9c6f7bdc36c97ad590c
[root@masternew ~]# mkdir -p $HOME/.kube
[root@masternew ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@masternew ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@masternew ~]# export KUBECONFIG=/etc/kubernetes/admin.conf
初始化完成后,可以使用命令查看节点信息了,发现是 NotReady 状态
[root@masternew ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
masternew NotReady control-plane 97s v1.28.2
7、工作节点加入k8s集群,加入节点命令是在初始化master完成后给出的,在每个工作节点执行。
[root@node1new ~]# kubeadm join masternew:6443 --token 7izf2l.1ssrdhqux2vyradb \
> --discovery-token-ca-cert-hash sha256:c6995cbd84c701ef6ba2eff481d43b7ad3c2c1e49387a9c6f7bdc36c97ad590c
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
To see the stack trace of this error execute with --v=5 or higher
如果由于当前版本不再默认支持docker,如果服务器使用的docker,
需要在命令后面加入参数--cri-socket unix:///var/run/cri-dockerd.sock
kubeadm join masternew:6443 --token 7izf2l.1ssrdhqux2vyradb \--discovery-token-ca-cert-hash sha256:c6995cbd84c701ef6ba2eff481d43b7ad3c2c1e49387a9c6f7bdc36c97ad590c \--cri-socket unix:///var/run/cri-dockerd.sock
[root@node1new ~]# kubeadm join masternew:6443 --token 7izf2l.1ssrdhqux2vyradb \
> --discovery-token-ca-cert-hash sha256:c6995cbd84c701ef6ba2eff481d43b7ad3c2c1e49387a9c6f7bdc36c97ad590c \
> --cri-socket unix:///var/run/cri-dockerd.sock
[preflight] Running pre-flight checks[WARNING Hostname]: hostname "node1new" could not be reached[WARNING Hostname]: hostname "node1new": lookup node1new on 8.8.8.8:53: no such host
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
#token默认的有效期为24小时,过期之后就不能用了,需要重新创建token,操作如下
kubeadm token create --print-join-command
# 另外,短时间内生成多个token时,生成新token后建议删除前一个旧的
#查看token命令
kubeadm token list
# 删除token命令
kubeadm token delete tokenid
[root@masternew ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
masternew NotReady control-plane 17m v1.28.2
node1new NotReady <none> 58s v1.28.2
node2new NotReady <none> 48s v1.28.2
8、部署 calico
安装pod网络插件是pod之间进行通信的必要条件,k8s支持众多网络方案,这里选用calico方案。
calico历史版本地址 https://docs.tigera.io/archive#v3.1.7
# 下载calico.yaml
curl https://docs.tigera.io/archive/v3.25/manifests/calico.yaml -O
在初始化master时配置的–pod-network-cidr=192.169.0.0/16,编辑calico.yaml配置文件,这里CALICO_IPV4POOL_CIDR也要改成192.169.0.0/16
calico 默认会找 eth0网卡,如果当前机器网卡不是这个名字会无法启动,需要手动配置下网卡名。
我这里是 ens33,编辑calico.yaml配置文件加入如下内容 ,在 CLUSTER_TYPE 同级目录下
- name: IP_AUTODETECTION_METHODvalue: "interface=ens33"
kubectl apply -f calico.yaml
kubectl apply 应用后需要等待一段时间节点状态才会变为Ready,主机内存cpu越少等待时间越久。
[root@masternew ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
masternew Ready control-plane 61m v1.28.2
node1new Ready <none> 45m v1.28.2
node2new Ready <none> 45m v1.28.2
查看所有的pod,要等一段时间这里状态才会变为Running
默认查询当前命名空间下对象,-A查询所有命名空间下对象,这里查询的对象是pod
[root@masternew ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-658d97c59c-6f5r4 0/1 ContainerCreating 0 22m
kube-system calico-node-hhxdx 0/1 PodInitializing 0 22m
kube-system calico-node-mvjtr 0/1 Init:2/3 0 22m
kube-system calico-node-rcgvh 0/1 Init:2/3 0 22m
kube-system coredns-6554b8b87f-4p8zd 0/1 ContainerCreating 0 61m
kube-system coredns-6554b8b87f-xrv4h 0/1 ContainerCreating 0 61m
kube-system etcd-masternew 1/1 Running 0 61m
kube-system kube-apiserver-masternew 1/1 Running 0 61m
kube-system kube-controller-manager-masternew 0/1 Running 6 (4m16s ago) 61m
kube-system kube-proxy-djnzr 1/1 Running 0 45m
kube-system kube-proxy-dz7wh 1/1 Running 0 61m
kube-system kube-proxy-nx8zq 1/1 Running 0 45m
kube-system kube-scheduler-masternew 0/1 Running 6 (2m1s ago) 61m[root@masternew ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-658d97c59c-6f5r4 1/1 Running 0 26m
kube-system calico-node-hhxdx 1/1 Running 1 (60s ago) 26m
kube-system calico-node-mvjtr 1/1 Running 0 26m
kube-system calico-node-rcgvh 1/1 Running 0 26m
kube-system coredns-6554b8b87f-4p8zd 1/1 Running 0 65m
kube-system coredns-6554b8b87f-xrv4h 1/1 Running 0 65m
kube-system etcd-masternew 1/1 Running 0 65m
kube-system kube-apiserver-masternew 1/1 Running 0 65m
kube-system kube-controller-manager-masternew 0/1 Running 7 (3m33s ago) 65m
kube-system kube-proxy-djnzr 1/1 Running 0 49m
kube-system kube-proxy-dz7wh 1/1 Running 0 65m
kube-system kube-proxy-nx8zq 1/1 Running 0 49m
kube-system kube-scheduler-masternew 1/1 Running 7 (3m2s ago) 65m
测试K8S的自愈能力,将一个工作节点关机或重启,查看工作节点状态变为NotReady
节点重启成功后,又会自动加入到集群中,再次查看工作节点状态变为Ready。
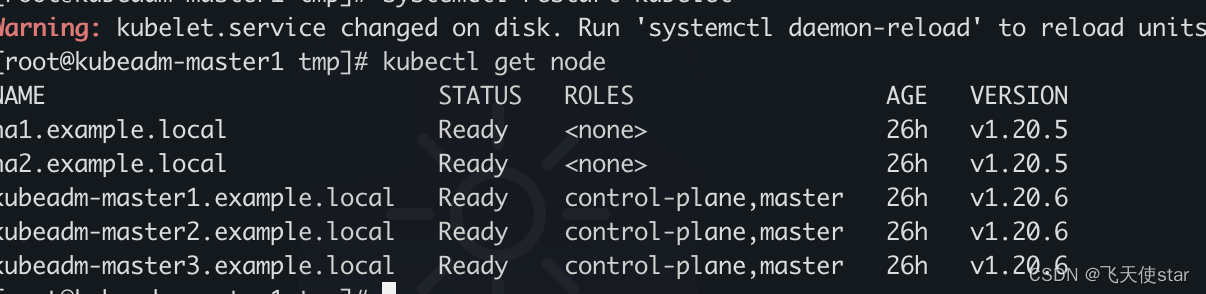
[root@masternew ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
masternew Ready control-plane 76m v1.28.2
node1new NotReady <none> 60m v1.28.2
node2new Ready <none> 60m v1.28.2
[root@masternew ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
masternew Ready control-plane 79m v1.28.2
node1new Ready <none> 63m v1.28.2
node2new Ready <none> 63m v1.28.2
3、Dashboard
Dashboard 是Kubernetes官方提供的可视化控制面板
项目地址:https://github.com/kubernetes/dashboard
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
下载失败的话,就网页访问,然后将网页内容复制粘贴,文件名可自定义。
kubectl apply -f recommended.yaml
默认查询当前命名空间下对象,-A查询所有命名空间下对象,这里查询的对象是svc服务service
[root@masternew ~]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 112m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 112m
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.149.225 <none> 8000/TCP 6m54s
kubernetes-dashboard kubernetes-dashboard ClusterIP 10.96.159.43 <none> 443/TCP 6m54s
官方下载的要修改才能正常使用,将type:ClusterIP改为type:NodePort
kubectl edit 在线修改,将type:ClusterIP改为type:NodePort,svc指服务service,-n指定命名空间
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
[root@masternew ~]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 119m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 119m
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.149.225 <none> 8000/TCP 13m
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.159.43 <none> 443:31260/TCP 13m
集群任意节点都可以访问,注意是https协议,https://集群任意节点ip:31260/ , https://10.1.1.111:31260/
登录需要Token,创建一个Token,名字可自定义,vi dash-token.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: adminannotations:rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccountname: adminnamespace: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:name: adminnamespace: kubernetes-dashboardlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcile
kubectl apply -f dash-token.yaml
dashboard获取登录令牌信息
kubectl create token admin -n kubernetes-dashboard
执行应用这个文件,获取令牌,成功登入。
4、NameSpace
命名空间用来隔离资源,是一种标识机制,不会隔离网络。不同的业务(web、数据库、消息中间件)可以部署在不同的命名空间,实现业务的隔离,并且可以对其进行资源配额,限制cpu、内存等资源的使用。
Namespace 适合用于隔离不同用户创建的资源,每一个添加到Kubernetes集群的工作负载必须放在一个命名空间中,不指定 namespace 默认都在 default 下面。
Kubernetes 启动时会创建4个初始命名空间:
1、default:Kubernetes 默认命名空间。
2、kube-system:用于 Kubernetes 系统创建的对象。
3、kube-node-lease:该名字空间包含用于与各个节点关联的 Lease(租约)对象。 节点租约允许 kubelet 发送心跳, 由此控制面能够检测到节点故障。
4、kube-public:所有的客户端(包括未经身份验证的客户端)都可以读取该名字空间。 该名字空间主要预留为集群使用,以便某些资源需要在整个集群中可见可读。
获取所有的ns,kubectl get ns
获取指定命名空间下的pod,kubectl get pod -n kube-system
如果不指定命名空间 指默认命名空间default,kubectl get pod
创建命名空间,kubectl create ns mpp
删除命名空间,假如这个ns里有服务资源也会被删除,kubectl delete ns mpp
Kubernetes资源创建的两种方式:命令行、yaml
[root@masternew ~]# cat mpp-ns.yaml
apiVersion: v1
kind: Namespace
metadata:name: hello-mpp
[root@masternew ~]# kubectl apply -f mpp-ns.yaml
[root@masternew ~]# kubectl delete -f mpp-ns.yaml
使用create创建资源是一次性的,如果使用apply创建,后期修改yaml文件再次执行apply可以实现更新资源
kubectl create -f xxx.yaml
kubectl apply -f xxx.yaml
直接修改资源对应的yaml文件,并用 kubectl apply -f xxx.yaml 更新应用文件使之生效
注意:当apply不生效时,先使用delete清除资源,再使用apply创建资源
删除yaml文件指定的资源,kubectl delete -f xxx.yaml
查看资源的yaml格式信息,kubectl get 资源类型 资源名称 -o yaml
[root@masternew ~]# kubectl get ns hello-mpp -o yaml
apiVersion: v1
kind: Namespace
metadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"v1","kind":"Namespace","metadata":{"annotations":{},"name":"hello-mpp"}}creationTimestamp: "2023-12-22T07:39:39Z"labels:kubernetes.io/metadata.name: hello-mppname: hello-mppresourceVersion: "44954"uid: d0422a9b-732b-4022-ace5-6b3144cf40c2
spec:finalizers:- kubernetes
status:phase: Active[root@masternew ~]# kubectl get ns kubernetes-dashboard -o yaml
apiVersion: v1
kind: Namespace
metadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"v1","kind":"Namespace","metadata":{"annotations":{},"name":"kubernetes-dashboard"}}creationTimestamp: "2023-12-21T10:54:25Z"labels:kubernetes.io/metadata.name: kubernetes-dashboardname: kubernetes-dashboardresourceVersion: "8620"uid: f64037a4-3713-40ec-ba7f-17807bbebd25
spec:finalizers:- kubernetes
status:phase: Active
yaml 格式
apiVersion: api版本标签信息
kind:资源类型
metadata:资源元数据信息
spec: 属性
apiVersion: apps/v1 //指定api版本标签
kind: Deployment //定义资源的类型/角色,Deployment为副本控制器,此处资源类型可以是Deployment、Job、Ingress、Service等
metadata: //定义资源的元数据信息,比如资源的名称、namespace、标签等信息name: nginx-deployment //定义资源的名称,在同一个namespace空间中必须是唯一的namespace: kube-public //定义资源所在命名空间labels: //定义资源标签app: nginxname: test01
spec: //定义资源需要的参数属性,如是否在容器失败时重新启动容器的属性replicas: 3 //副本数selector: //定义标签选择器matchLabels: //定义匹配标签app: nginx //需与.spec.template.metadata.labels 定义的标签保持一致template: //定义业务模板,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配metadata:labels: //定义Pod副本将使用的标签,需与.spec.selector.matchLabels 定义的标签保持一致app: nginxspec:containers: //定义容器属性- name: nignx //定义一个容器名,一个 - name: 定义一个容器image: nginx:1.21 //定义容器使用的镜像以及版本ports:- name: httpcontainerPort: 80 定义容器的对外的端口- name: httpscontainerPort: 443
5、Pod
Pod:运行中的一组容器,是 Kubernetes 中应用的最小单位,也是在 k8s 上运行容器化应用的资源对象,其他的资源对象都是用来支撑或者扩展 Pod 对象功能的。
k8s 不会直接处理容器,而是 Pod。Pod是多进程设计,运用多个应用程序,也就是一个Pod里面有多个容器,而一个容器里面运行一个应用程序。
创建pod默认在default名称空间下,kubectl run nginx01 --image=nginx
删除pod默认在default名称空间下,kubectl delete pod nginx01kubectl describe 查询对象详细信息
kubectl describe pod nginx01
kubectl logs 查看对象日志
kubectl logs nginx01
kubectl get 查询对象,-o wide 对象具体信息,-A 所有ns的全部对象,-n 指定命名空间对象
kubectl get pod -o wide 查询默认命名空间的pod对象的具体信息
[root@masternew ~]# cat nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: nginx02labels:run: nginx02
spec:containers:- image: nginxname: nginx02
[root@masternew ~]# kubectl apply -f nginx-pod.yaml
[root@masternew ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx01 1/1 Running 0 20m
nginx02 1/1 Running 0 103s
pod是k8s最小资源单位,在k8s中每一个pod都会分配一个ip,一个pod中有多个容器,一个pod可运行多个应用
[root@masternew ~]# kubectl get pod -o wide -o wide 查看详细信息
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx01 1/1 Running 0 22m 192.169.115.67 node2new <none> <none>
nginx02 1/1 Running 0 3m26s 192.169.66.3 node1new <none> <none>
通过ip+端口来访问pod中的容器服务,curl 192.169.66.3
进入容器,[root@masternew ~]# kubectl exec -it nginx02 -- /bin/bash
root@nginx02:/# cd /usr/share/nginx/html/
root@nginx02:/usr/share/nginx/html# ls
50x.html index.html
root@nginx02:/usr/share/nginx/html# echo hello > index.html
root@nginx02:/usr/share/nginx/html# exit
exit
command terminated with exit code 127
[root@masternew ~]# curl 192.169.66.3
hello
[root@masternew ~]# cat web.yaml
apiVersion: v1
kind: Pod
metadata:labels:run: webname: web
spec:containers:- image: nginxname: nginx- image: tomcat:8.5.92name: tomcat
[root@masternew ~]# kubectl apply -f web.yaml
[root@masternew ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web 2/2 Running 0 3m47s 192.169.66.4 node1new <none> <none>
nginx默认80端口,curl 192.169.66.4
tomcat默认80端口,curl 192.169.66.4:8080
Kubernetes中包含了众多组件,通过watch的机制进行每个组件的协作,每个组件之间的设计实现了解耦其工作流程如下图所示:
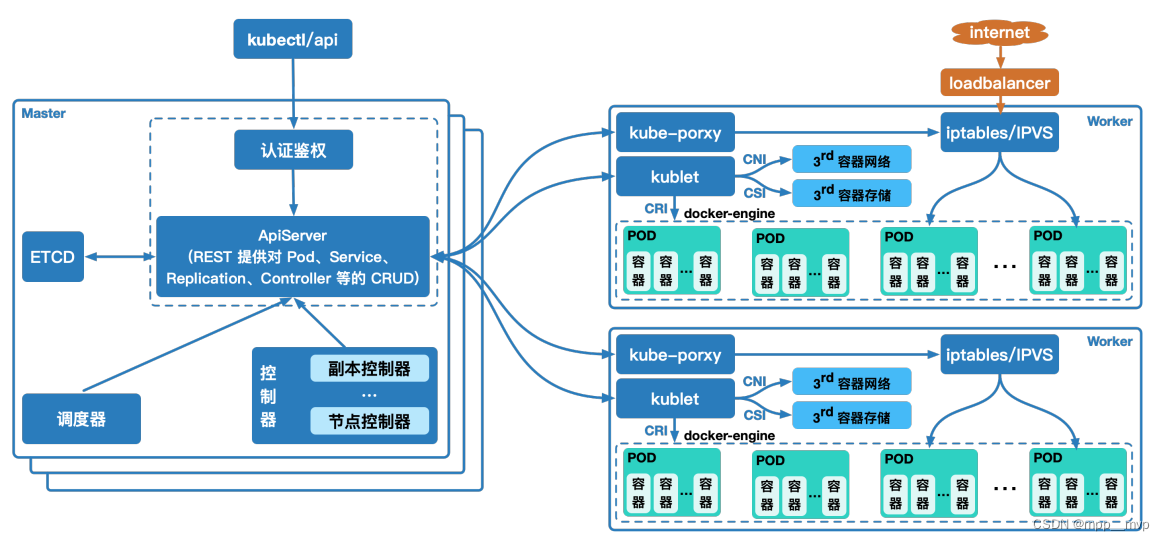
以创建Pod为例:
1、集群管理员或者开发人员通过kubectl或者客户端等构建REST请求,经由apiserver进行鉴权认证(使用kubeconfig文件),验证准入信息后将请求数据(metadata)写入etcd中;
2、ControllerManager(控制器组件)通过watch机制发现创建Pod的信息,并将整合信息通过apiservre写入etcd中,此时Pod处于可调度状态;
3、Scheduler(调度器组件)基于watch机制获取可调度Pod列表信息,通过调度算法(过滤或打分)为待调度Pod选择最适合的节点,并将创建Pod信息写入etcd中,创建请求发送给节点上的kubelet;
4、 kubelet收到Pod创建请求后,调用CNI接口为Pod创建网络环境,调用CRI接口创建Pod内部容器,调用CSI接口对Pod进行存储卷的挂载;
5、等待Pod内部运行环境创建完成,基于探针或者健康检查监测业务运行容器启动状态,启动完成后Pod处于Running状态,Pod进入运行阶段。
6、Deployment
为了更好地解决服务编排的问题,k8s在V1.2版本开始,引入了deployment控制器,这种控制器并不直接管理pod,而是通过管理replicaset来间接管理pod,即:deployment管理replicaset,replicaset管理pod。
k8s的最小单位是pod,通过deployment,使 pod 拥有多副本、自愈、扩缩容等能力。