Java学习+面试指南:https://javaxiaobear.cn
命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。
哪些应用场景需要用到分布式命名服务呢?典型的有:
-
分布式API目录
-
分布式节点命名
-
分布式ID生成器
1、分布式API目录
为分布式系统中各种API接口服务的名称、链接地址,提供类似JNDI(Java命名和目录接口)中的文件系统的功能。借助于ZooKeeper的树形分层结构就能提供分布式的API调用功能。
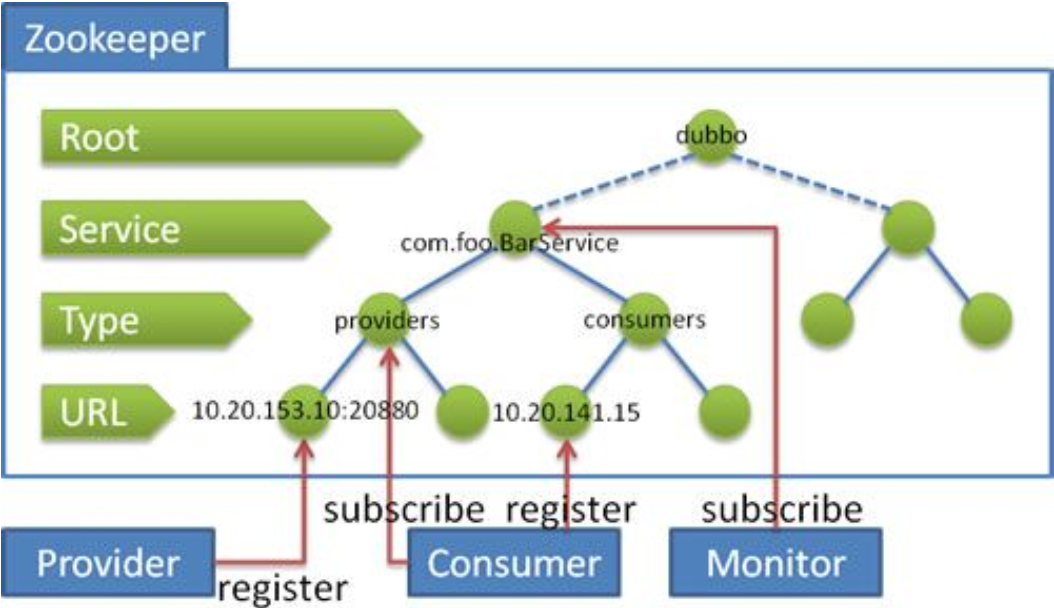
著名的Dubbo分布式框架就是应用了ZooKeeper的分布式的JNDI功能。在Dubbo中,使用ZooKeeper维护的全局服务接口API的地址列表。大致的思路为:
-
服务提供者(Service Provider)在启动的时候,向ZooKeeper上的指定节点/dubbo/${serviceName}/providers写入自己的API地址,这个操作就相当于服务的公开。
-
服务消费者(Consumer)启动的时候,订阅节点/dubbo/{serviceName}/providers下的服务提供者的URL地址,获得所有服务提供者的API。
2、分布式节点命名
一个分布式系统通常会由很多的节点组成,节点的数量不是固定的,而是不断动态变化的。比如说,当业务不断膨胀和流量洪峰到来时,大量的节点可能会动态加入到集群中。而一旦流量洪峰过去了,就需要下线大量的节点。再比如说,由于机器或者网络的原因,一些节点会主动离开集群。
如何为大量的动态节点命名呢?一种简单的办法是可以通过配置文件,手动为每一个节点命名。但是,如果节点数据量太大,或者说变动频繁,手动命名则是不现实的,这就需要用到分布式节点的命名服务。
可用于生成集群节点的编号的方案:
(1)使用数据库的自增ID特性,用数据表存储机器的MAC地址或者IP来维护。
(2)使用ZooKeeper持久顺序节点的顺序特性来维护节点的NodeId编号。
在第2种方案中,集群节点命名服务的基本流程是:
-
启动节点服务,连接ZooKeeper,检查命名服务根节点是否存在,如果不存在,就创建系统的根节点。
-
在根节点下创建一个临时顺序ZNode节点,取回ZNode的编号把它作为分布式系统中节点的NODEID。
-
如果临时节点太多,可以根据需要删除临时顺序ZNode节点。
3、分布式ID生成器
在分布式系统中,分布式ID生成器的使用场景非常之多:
-
大量的数据记录,需要分布式ID。
-
大量的系统消息,需要分布式ID。
-
大量的请求日志,如restful的操作记录,需要唯一标识,以便进行后续的用户行为分析和调用链路分析。
-
分布式节点的命名服务,往往也需要分布式ID。
-
。。。
传统的数据库自增主键已经不能满足需求。在分布式系统环境中,迫切需要一种全新的唯一ID系统,这种系统需要满足以下需求:
(1)全局唯一:不能出现重复ID。
(2)高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,就会造成严重影响。
有哪些分布式的ID生成器方案呢?大致如下:
- Java的UUID。
- 分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID。
- Twitter的SnowFlake算法。
- ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的ID。
- MongoDb的ObjectId:MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。
前面我写过一篇关于分布式ID的设计与实现,关于其他的实现可参考这篇哈
1、基于Zookeeper实现分布式ID生成器
在ZooKeeper节点的四种类型中,其中有以下两种类型具备自动编号的能力
-
PERSISTENT_SEQUENTIAL持久化顺序节点。
-
EPHEMERAL_SEQUENTIAL临时顺序节点。
ZooKeeper的每一个节点都会为它的第一级子节点维护一份顺序编号,会记录每个子节点创建的先后顺序,这个顺序编号是分布式同步的,也是全局唯一的。
可以通过创建ZooKeeper的临时顺序节点的方法,生成全局唯一的ID
/*** @author 小熊学Java* @version 1.0* @description: TODO* @date 2023/12/17 21:08*/
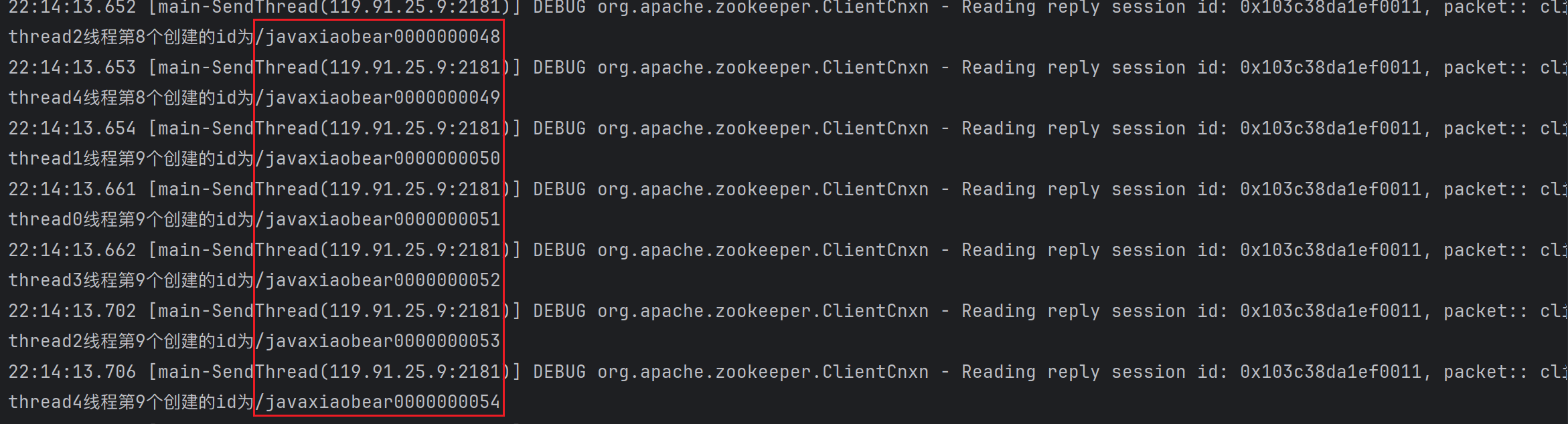
public class IDMaker {private static final String ZOOKEEPER_ADDRESS = "ip:2181";private static final int SESSION_TIMEOUT = 3000;public CuratorFramework client;public IDMaker() {// 重试策略RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);client = CuratorFrameworkFactory.newClient(ZOOKEEPER_ADDRESS, retryPolicy);client.start();}/*** 根据路径创建* @param path* @return* @throws Exception*/public String createSeqNode(String path) throws Exception{return client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);}public String createId(String path) throws Exception{String seqNode = createSeqNode(path);if (!StringUtils.isBlank(seqNode)){//获取末尾的序号int i = seqNode.lastIndexOf(path);if (i > 0){i += path.length();return i <= seqNode.length() ? seqNode.substring(i) : "";}}return seqNode;}public static void main(String[] args) throws InterruptedException {IDMaker idMaker = new IDMaker();String nodePath = "/javaxiaobear";for(int i=0;i<5;i++){new Thread(()->{for (int j=0;j<10;j++){String id = null;try {id = idMaker.createId(nodePath);System.out.println(Thread.currentThread().getName() + "线程第" + j + "个创建的id为"+ id);} catch (Exception e) {e.printStackTrace();}}},"thread"+i).start();}Thread.sleep(Integer.MAX_VALUE);}
}
执行结果
2、基于Zookeeper实现SnowFlakeID算法
Twitter(推特)的SnowFlake算法是一种著名的分布式服务器用户ID生成算法。SnowFlake算法所生成的ID是一个64bit的长整型数字,如图10-2所示。这个64bit被划分成四个部分,其中后面三个部分分别表示时间戳、工作机器ID、序列号。
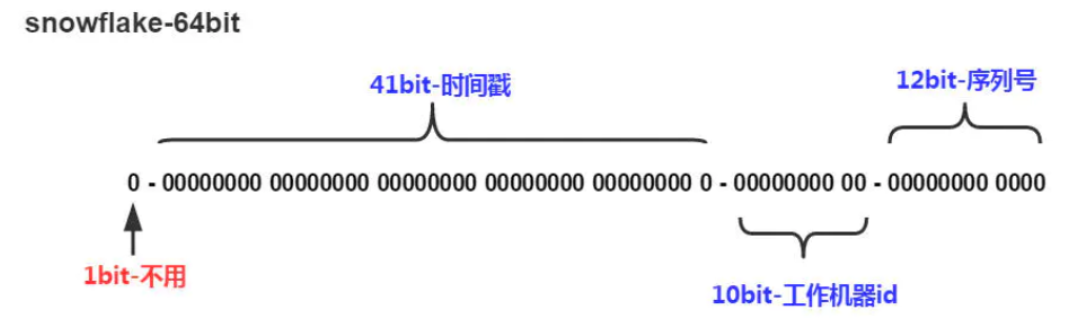
SnowFlakeID的四个部分,具体介绍如下:
(1)第一位 占用1 bit,其值始终是0,没有实际作用。
(2)时间戳 占用41 bit,精确到毫秒,总共可以容纳约69年的时间。
(3)工作机器id占用10 bit,最多可以容纳1024个节点。
(4)序列号 占用12 bit。这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。
在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒最多可以生成的ID数量为: 1024 * 4096 =4194304,在绝大多数并发场景下都是够用的。
SnowFlake算法的优点:
-
生成ID时不依赖于数据库,完全在内存生成,高性能和高可用性。
-
容量大,每秒可生成几百万个ID。
-
ID呈趋势递增,后续插入数据库的索引树时,性能较高。
SnowFlake算法的缺点:
-
依赖于系统时钟的一致性,如果某台机器的系统时钟回拨了,有可能造成ID冲突,或者ID乱序。
-
在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险。
基于zookeeper实现雪花算法:
public class SnowflakeIdGenerator {/*** 单例*/public static SnowflakeIdGenerator instance =new SnowflakeIdGenerator();/*** 初始化单例** @param workerId 节点Id,最大8091* @return the 单例*/public synchronized void init(long workerId) {if (workerId > MAX_WORKER_ID) {// zk分配的workerId过大throw new IllegalArgumentException("woker Id wrong: " + workerId);}instance.workerId = workerId;}private SnowflakeIdGenerator() {}/*** 开始使用该算法的时间为: 2017-01-01 00:00:00*/private static final long START_TIME = 1483200000000L;/*** worker id 的bit数,最多支持8192个节点*/private static final int WORKER_ID_BITS = 13;/*** 序列号,支持单节点最高每毫秒的最大ID数1024*/private final static int SEQUENCE_BITS = 10;/*** 最大的 worker id ,8091* -1 的补码(二进制全1)右移13位, 然后取反*/private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);/*** 最大的序列号,1023* -1 的补码(二进制全1)右移10位, 然后取反*/private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);/*** worker 节点编号的移位*/private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;/*** 时间戳的移位*/private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + SEQUENCE_BITS;/*** 该项目的worker 节点 id*/private long workerId;/*** 上次生成ID的时间戳*/private long lastTimestamp = -1L;/*** 当前毫秒生成的序列*/private long sequence = 0L;/*** Next id long.** @return the nextId*/public Long nextId() {return generateId();}/*** 生成唯一id的具体实现*/private synchronized long generateId() {long current = System.currentTimeMillis();if (current < lastTimestamp) {// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1return -1;}if (current == lastTimestamp) {// 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1sequence = (sequence + 1) & MAX_SEQUENCE;if (sequence == MAX_SEQUENCE) {// 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳current = this.nextMs(lastTimestamp);}} else {// 当前的时间戳已经是下一个毫秒sequence = 0L;}// 更新上次生成id的时间戳lastTimestamp = current;// 进行移位操作生成int64的唯一ID//时间戳右移动23位long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;//workerId 右移动10位long workerId = this.workerId << WORKER_ID_SHIFT;return time | workerId | sequence;}/*** 阻塞到下一个毫秒*/private long nextMs(long timeStamp) {long current = System.currentTimeMillis();while (current <= timeStamp) {current = System.currentTimeMillis();}return current;}
}