目录
15.4.6 绘制直方图
die_visual.py
注意
15.4.7 同时掷两个骰子
dice_visual.py
15.4.8 同时掷两个面数不同的骰子
different_dice.py
15.5 小结
第 16 章
16.1 CSV 文件格式
16.1.1 分析 CSV 文件头
highs_lows.py
注意
16.1.2 打印文件头及其位置
highs_lows.py
往期快速传送门👆(在文章最后):
感谢大家的支持!欢迎订阅收藏!专栏将持续更新!

15.4.6 绘制直方图
有了频率列表后,我们就可以绘制一个表示结果的直方图。直方图是一种条形图,指出了各 种结果出现的频率。创建这种直方图的代码如下:
die_visual.py
import pygal
--snip--
# 分析结果
frequencies = []
for value in range(1, die.num_sides+1):frequency = results.count(value)frequencies.append(frequency)
# 对结果进行可视化
1 hist = pygal.Bar()
hist.title = "Results of rolling one D6 1000 times."
2 hist.x_labels = ['1', '2', '3', '4', '5', '6']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
3 hist.add('D6', frequencies)
hist.render_to_file('die_visual.svg')为创建条形图,我们创建了一个pygal.Bar()实例,并将其存储在hist中(见1)。接下来, 我们设置hist的属性title(用于标示直方图的字符串),将掷D6骰子的可能结果用作x轴的标签 (见2),并给每个轴都添加了标题。在3处,我们使用add()将一系列值添加到图表中(向它传递要给添加的值指定的标签,还有一个列表,其中包含将出现在图表中的值)。最后,我们将这个 图表渲染为一个SVG文件,这种文件的扩展名必须为.svg。
要查看生成的直方图,最简单的方式是使用Web浏览器。为此,在任何Web浏览器中新建一 个标签页,再在其中打开文件die_visual.svg(它位于die_visual.py所在的文件夹中)。你将看到一 个类似于图15-11所示的图表(为方便印刷,我稍微修改了这个图表;默认情况下,Pygal生成的 图表的背景比你在图15-11中看到的要暗)。
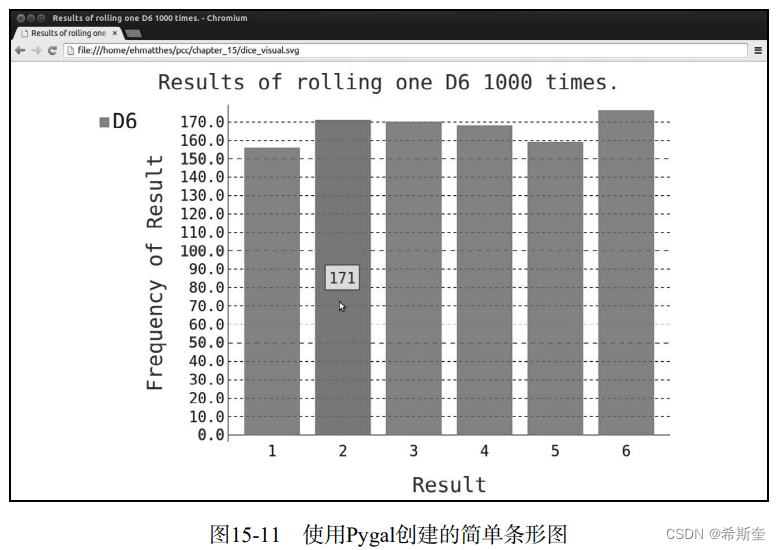
注意
Pygal让这个图表具有交互性:如果你将鼠标指向该图表中的任何条形,将看到与之 相关联的数据。在同一个图表中绘制多个数据集时,这项功能显得特别有用。
15.4.7 同时掷两个骰子
同时掷两个骰子时,得到的点数更多,结果分布情况也不同。下面来修改前面的代码,创建 两个D6骰子,以模拟同时掷两个骰子的情况。每次掷两个骰子时,我们都将两个骰子的点数相 加,并将结果存储在results中。请复制die_visual.py并将其保存为dice_visual.py,再做如下修改:
dice_visual.py
import pygal
from die import Die
# 创建两个D6骰子
die_1 = Die()
die_2 = Die()
# 掷骰子多次,并将结果存储到一个列表中
results = []
for roll_num in range(1000):
1 result = die_1.roll() + die_2.roll()
results.append(result)
# 分析结果
frequencies = []
2 max_result = die_1.num_sides + die_2.num_sides
3 for value in range(2, max_result+1):frequency = results.count(value)frequencies.append(frequency)
# 可视化结果
hist = pygal.Bar()
4 hist.title = "Results of rolling two D6 dice 1000 times."
hist.x_labels = ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add('D6 + D6', frequencies)
hist.render_to_file('dice_visual.svg')创建两个Die实例后,我们掷骰子多次,并计算每次的总点数(见1)。可能出现的最大点数 12为两个骰子的最大可能点数之和,我们将这个值存储在了max_result中(见2)。可能出现的最 小总点数2为两个骰子的最小可能点数之和。分析结果时,我们计算2到max_result的各种点数出 现的次数(见3)。我们原本可以使用range(2, 13),但这只适用于两个D6骰子。模拟现实世界 的情形时,最好编写可轻松地模拟各种情形的代码。前面的代码让我们能够模拟掷任何两个骰子 的情形,而不管这些骰子有多少面。
创建图表时,我们修改了标题、x轴标签和数据系列(见4)。(如果列表x_labels比这里所示 的长得多,那么编写一个循环来自动生成它将更合适。)
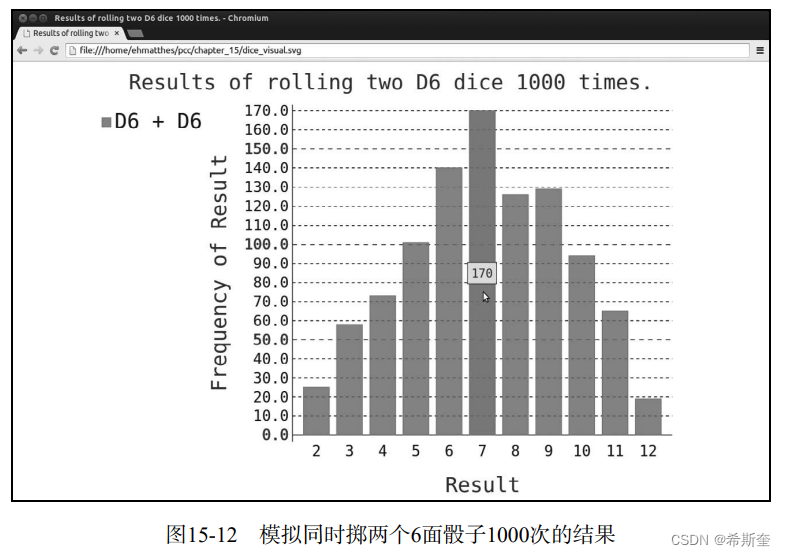
运行这些代码后,在浏览器中刷新显示图表的标签页,你将看到如图15-12所示的图表。
这个图表显示了掷两个D6骰子时得到的大致结果。正如你看到的,总点数为2或12的可能性 最小,而总点数为7的可能性最大,这是因为在6种情况下得到的总点数都为7。这6种情况如下: 1和6、2和5、3和4、4和3、5和2、6和1。
15.4.8 同时掷两个面数不同的骰子
下面来创建一个6面骰子和一个10面骰子,看看同时掷这两个骰子50 000次的结果如何:
different_dice.py
from die import Die
import pygal
# 创建一个D6和一个D10
die_1 = Die()
1 die_2 = Die(10)
# 掷骰子多次,并将结果存储在一个列表中
results = []
for roll_num in range(50000):result = die_1.roll() + die_2.roll()results.append(result)
# 分析结果
--snip--
# 可视化结果
hist = pygal.Bar()
2 hist.title = "Results of rolling a D6 and a D10 50,000 times."
hist.x_labels = ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12','13', '14', '15', '16']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add('D6 + D10', frequencies)
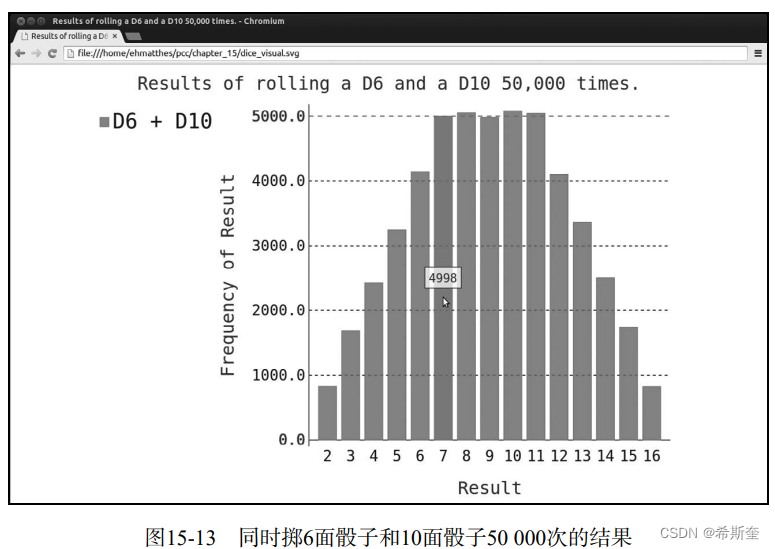
hist.render_to_file('dice_visual.svg')为创建D10骰子,我们在创建第二个Die实例时传递了实参10(见1)。我们还修改了第一个 循环,以模拟掷骰子50 000次而不是1000次。可能出现的最小总点数依然是2,但现在可能出现 的最大总点数为16,因此我们相应地调整了标题、x轴标签和数据系列标签(见2)。 图15-13显示了最终的图表。可能性最大的点数不是一个,而是5个,这是因为导致出现最小 点数和最大点数的组合都只有一种(1和1以及6和10),但面数较小的骰子限制了得到中间点数的 组合数:得到总点数7、8、9、10和11的组合数都是6种。因此,这些总点数是最常见的结果,它 们出现的可能性相同。
通过使用Pygal来模拟掷骰子的结果,能够非常自由地探索这种现象。只需几分钟,就可以 掷各种骰子很多次。
15.5 小结
在本章中,你学习了:如何生成数据集以及如何对其进行可视化;如何使用matplotlib创建简 单的图表,以及如何使用散点图来探索随机漫步过程;如何使用Pygal来创建直方图,以及如何 使用直方图来探索同时掷两个面数不同的骰子的结果。 使用代码生成数据集是一种有趣而强大的方式,可用于模拟和探索现实世界的各种情形。完 成后面的数据可视化项目时,请注意可使用代码模拟哪些情形。请研究新闻媒体中的可视化,看 看其中是否有图表是以你在这些项目中学到的类似方式生成的。 在第16章中,我们将从网上下载数据,并继续使用matplotlib和Pygal来探索这些数据。
第 16 章
下载数据
16.1 CSV 文件格式
要在文本文件中存储数据,最简单的方式是将数据作为一系列以逗号分隔的值(CSV)写入 文件。这样的文件称为CSV文件。例如,下面是一行CSV格式的天气数据:
2014-1-5,61,44,26,18,7,-1,56,30,9,30.34,30.27,30.15,,,,10,4,,0.00,0,,195这是阿拉斯加锡特卡2014年1月5日的天气数据,其中包含当天的最高气温和最低气温,还有 众多其他数据。CSV文件对人来说阅读起来比较麻烦,但程序可轻松地提取并处理其中的值,这 有助于加快数据分析过程。
注意 这个项目使用的天气数据是从http://www.wunderground.com/history/下载而来的。
16.1.1 分析 CSV 文件头
csv模块包含在Python标准库中,可用于分析CSV文件中的数据行,让我们能够快速提取感兴 趣的值。下面先来查看这个文件的第一行,其中包含一系列有关数据的描述:
highs_lows.py
import csv
filename = 'sitka_weather_07-2014.csv'
1 with open(filename) as f:
2 reader = csv.reader(f)
3 header_row = next(reader)
print(header_row)导入模块csv后,我们将要使用的文件的名称存储在filename中。接下来,我们打开这个文 件,并将结果文件对象存储在f中(见1)。然后,我们调用csv.reader(),并将前面存储的文件 对象作为实参传递给它,从而创建一个与该文件相关联的阅读器(reader)对象(见2)。我们 将这个阅读器对象存储在reader中。
模块csv包含函数next(),调用它并将阅读器对象传递给它时,它将返回文件中的下一行。 在前面的代码中,我们只调用了next()一次,因此得到的是文件的第一行,其中包含文件头(见 3)。我们将返回的数据存储在header_row中。正如你看到的,header_row包含与天气相关的文件 头,指出了每行都包含哪些数据:
['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min TemperatureF',
'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max Humidity',
' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn',
' Mean Sea Level PressureIn', ' Min Sea Level PressureIn',
' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min VisibilityMiles',
' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH',
'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']reader处理文件中以逗号分隔的第一行数据,并将每项数据都作为一个元素存储在列表中。 文件头AKDT表示阿拉斯加时间(Alaska Daylight Time),其位置表明每行的第一个值都是日期或 时间。文件头Max TemperatureF指出每行的第二个值都是当天的最高华氏温度。可通过阅读其他 的文件头来确定文件包含的信息类型。
注意
文件头的格式并非总是一致的,空格和单位可能出现在奇怪的地方。这在原始数据文件 中很常见,但不会带来任何问题。
16.1.2 打印文件头及其位置
为让文件头数据更容易理解,将列表中的每个文件头及其位置打印出来:
highs_lows.py
--snip--
with open(filename) as f:reader = csv.reader(f)header_row = next(reader)
1 for index, column_header in enumerate(header_row):print(index, column_header) 我们对列表调用了enumerate()(见1)来获取每个元素的索引及其值。(请注意,我们删除 了代码行print(header_row),转而显示这个更详细的版本。) 输出如下,其中指出了每个文件头的索引:
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
3 Min TemperatureF
--snip--
20 CloudCover
21 Events
22 WindDirDegrees从中可知,日期和最高气温分别存储在第0列和第1列。为研究这些数据,我们将处理 sitka_weather_07-2014.csv中的每行数据,并提取其中索引为0和1的值。
关于“Python”的核心知识点整理大全37-CSDN博客
关于“Python”的核心知识点整理大全25-CSDN博客
关于“Python”的核心知识点整理大全12-CSDN博客