埃弗顿·戈梅德(Everton Gomede)
一、说明
语义分割是计算机视觉领域的一项关键任务,涉及将图像中的每个像素分类为预定义的类。这项任务在从自动驾驶汽车到医学成像的各种应用中都具有深远的影响。深度学习的出现显著提高了语义分割模型的功能和准确性。本文深入探讨了深度学习在语义分割中的作用,讨论了其演变、方法、当前趋势和未来前景。

在我们信任的像素中,每个像素都讲述了一个故事:通过语义分割中的深度学习来辨别细节的艺术。
二、深度学习在语义分割中的演进
深度学习在语义分割中的旅程始于卷积神经网络 (CNN) 的发展。在 CNN 出现之前,分割任务在很大程度上依赖于手工制作的特征和经典的机器学习技术,这些技术在处理真实世界图像的复杂性和可变性方面的能力有限。
CNN的引入,特别是通过AlexNet等模型的引入,标志着范式的转变。这些网络可以直接从数据中学习分层特征表示,从而显著提高性能。随后的进步,例如开发更深层次的架构,如VGG和ResNet,进一步增强了这种能力。
三、深度学习的语义分割方法
- 全卷积网络 (FCN):FCN是最早专门为语义分割量身定制的深度学习模型之一。与包含用于分类的全连接层的标准 CNN 不同,FCN 将这些层转换为卷积层,使它们能够输出空间地图而不是分类分数。
- 编码器-解码器结构:编码器-解码器架构,如 U-Net、SegNet 和 DeepLab,在语义分割方面已经变得很流行。编码器在捕获高级语义信息的同时逐步减少空间维度。然后,解码器会逐渐恢复对象细节和空间维度。
- 扩张卷积:DeepLab 等模型中使用的膨胀卷积扩展了滤波器的感受野,使网络能够在不损失分辨率的情况下集成更广泛的上下文。
- 注意力机制:注意力机制(例如 Transformer 模型中的注意力机制)越来越多地被纳入分割网络,以更好地关注相关特征。
四、当前趋势和应用
- 数据效率:目前的研究重点是使语义分割模型更具数据效率,因为获取大型注释数据集具有挑战性。
- 实时处理:在自动驾驶和视频分析等应用中,对实时分割的需求越来越大。
- 多模态学习:集成来自各种传感器或模式的信息,例如将视觉数据与自动驾驶汽车中的LiDAR相结合,是一个不断增长的趋势。
- 迁移学习和领域适应:这些技术对于将在一个数据集上训练的模型应用于另一个领域至关重要,例如将城市场景上训练的模型适应农村环境。
五、挑战与未来方向
- 细粒度分割:在更详细的层面上进行细分,例如区分不同类型的道路使用者,仍然具有挑战性。
- 鲁棒性和泛化性:确保模型对不同的照明条件、天气和遮挡具有鲁棒性对于实际应用至关重要。
- 可解释性和公平性:由于这些模型用于关键应用程序,因此确保其决策可解释且没有偏见变得越来越重要。
- 效率和可扩展性:开发可在不影响性能的情况下部署在边缘设备上的轻量级模型是一个关键研究领域。
六、代码
使用合成数据集创建用于语义分割的完整深度学习管道涉及多个步骤,包括数据集创建、模型设计、训练和结果可视化。下面,我将提供包含这些元素的 Python 代码大纲。请注意,由于复杂性和资源要求,此处运行整个管道不可行,但我将为每个步骤提供详细说明和示例代码。
1. 数据集创建
为简单起见,让我们创建一个具有简单形状的合成数据集。任务是分割图像中的这些形状。
from skimage.draw import random_shapesdef generate_synthetic_dataset(image_size, max_shapes, num_images):images = []masks = []for _ in range(num_images):# For colored images (multichannel), use a tuple of tuplesimage, _ = random_shapes(image_size, max_shapes=max_shapes, channel_axis=2, intensity_range=((0, 255), (0, 255), (0, 255)))# For masks (single-channel grayscale), use a single tuplemask, _ = random_shapes(image_size, max_shapes=max_shapes, channel_axis=None, intensity_range=(0, 1))images.append(image)masks.append(mask)return np.array(images), np.array(masks)# Generate dataset
image_size = (128, 128)
max_shapes = 5
num_images = 100
images, masks = generate_synthetic_dataset(image_size, max_shapes, num Images)2. 模型设计
我们将使用一个简单的全卷积网络 (FCN) 进行分段。
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenate
from tensorflow.keras.models import Modeldef unet(input_size=(128, 128, 3)):inputs = Input(input_size)# Down-samplingconv1 = Conv2D(32, 3, activation='relu', padding='same')(inputs)pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)# ... (add more layers as needed) ...# Up-samplingup1 = UpSampling2D(size=(2, 2))(pool1)conv2 = Conv2D(32, 2, activation='relu', padding='same')(up1)merged = concatenate([conv1, conv2], axis=3)conv3 = Conv2D(1, 3, activation='sigmoid', padding='same')(merged)model = Model(inputs=inputs, outputs=conv3)return model# Create model
model = unet()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])3. 培训
在合成数据集上训练模型。
# Normalize the image data
images = images.astype('float32') / 255
masks = masks.astype('float32') / 255# Train the model
model.fit(images, masks, batch_size=16, epochs=10, validation_split=0.1)Epoch 1/10
6/6 [==============================] - 8s 1s/step - loss: 0.7967 - accuracy: 0.1632 - val_loss: 0.6109 - val_accuracy: 0.9496
Epoch 2/10
6/6 [==============================] - 5s 919ms/step - loss: 0.5419 - accuracy: 0.8869 - val_loss: 0.3572 - val_accuracy: 0.9496
Epoch 3/10
6/6 [==============================] - 5s 764ms/step - loss: 0.3818 - accuracy: 0.8870 - val_loss: 0.2160 - val_accuracy: 0.9496
Epoch 4/10
6/6 [==============================] - 5s 763ms/step - loss: 0.3759 - accuracy: 0.8870 - val_loss: 0.2077 - val_accuracy: 0.9496
Epoch 5/10
6/6 [==============================] - 5s 813ms/step - loss: 0.3750 - accuracy: 0.8870 - val_loss: 0.2157 - val_accuracy: 0.9496
Epoch 6/10
6/6 [==============================] - 4s 731ms/step - loss: 0.3612 - accuracy: 0.8870 - val_loss: 0.2365 - val_accuracy: 0.9496
Epoch 7/10
6/6 [==============================] - 5s 812ms/step - loss: 0.3586 - accuracy: 0.8870 - val_loss: 0.2349 - val_accuracy: 0.9496
Epoch 8/10
6/6 [==============================] - 5s 740ms/step - loss: 0.3581 - accuracy: 0.8870 - val_loss: 0.2267 - val_accuracy: 0.9496
Epoch 9/10
6/6 [==============================] - 4s 729ms/step - loss: 0.3589 - accuracy: 0.8870 - val_loss: 0.2252 - val_accuracy: 0.9496
Epoch 10/10
6/6 [==============================] - 6s 1s/step - loss: 0.3558 - accuracy: 0.8870 - val_loss: 0.2378 - val_accuracy: 0.9496
<keras.src.callbacks.History at 0x7f9c6acc6e60>4. 结果可视化
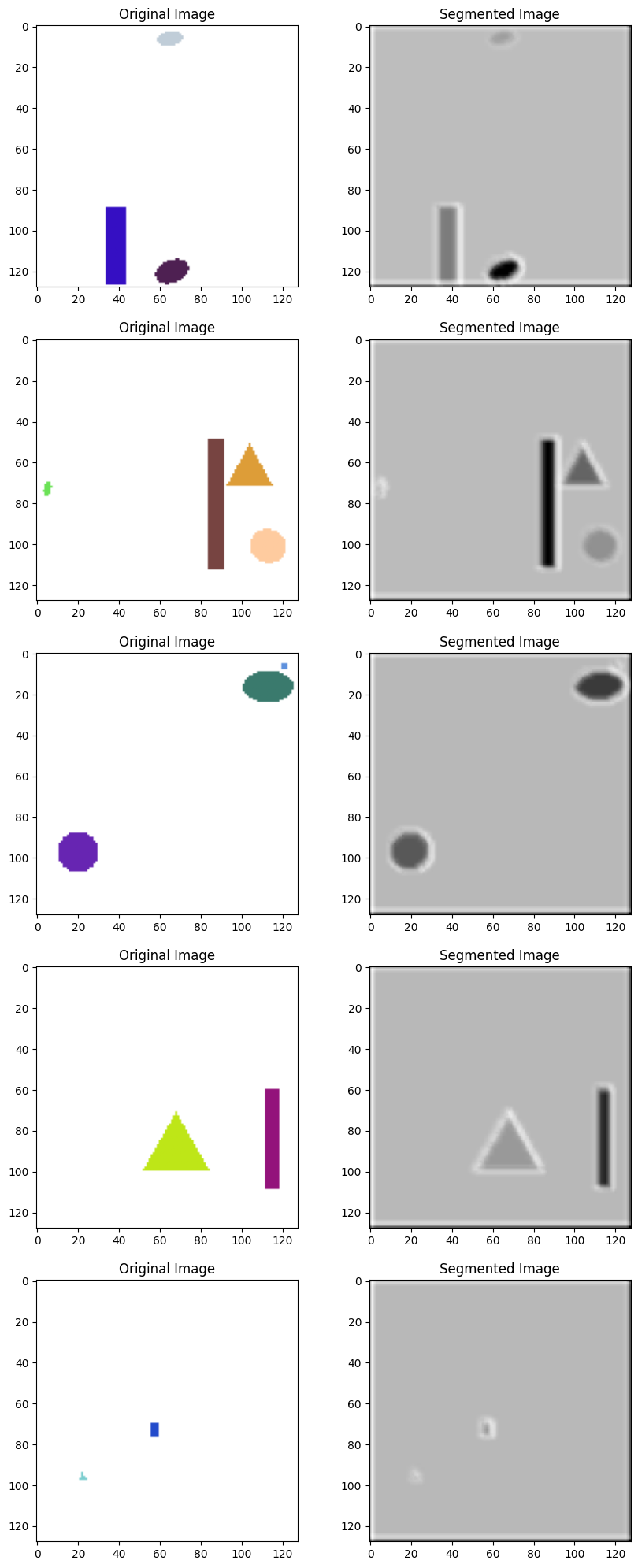
可视化分割结果。
def plot_results(images, true_masks, model, num_images=5):preds = model.predict(images[:num_images])fig, axs = plt.subplots(num_images, 3, figsize=(15, 5 * num_images))for i in range(num_images):axs[i, 0].imshow(images[i])axs[i, 0].set_title("Original Image")axs[i, 1].imshow(true_masks[i], cmap='gray')axs[i, 1].set_title("True Mask")axs[i, 2].imshow(np.argmax(preds[i], axis=-1), cmap='gray')axs[i, 2].set_title("Predicted Mask")plt.show()# Example usage
plot_results(images, masks, model)请记住,对于实际应用程序,您需要更复杂的数据集,并且可能需要更复杂的模型。此代码为了解如何使用 Python 中的深度学习构建和可视化语义分割管道提供了一个起点。
七、结论
总之,深度学习彻底改变了语义分割,提供了前所未有的准确性和效率。随着该领域的不断发展,它有望解锁更复杂、更可靠的应用程序,改变机器感知和与周围世界互动的方式。