文章目录
- mybatis
- 是什么
- 架构设计
- 首先建立起Mapper的代理工程和代理
- 映射器的注册和使用
- XML文件解析
- 数据源解析、创建和使用
- SQL执行器(Executor)的定义与实现
- SQL解析
- 参数处理器:策略模式实现
- 封装处理结果
- 注解
mybatis
是什么
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
——来自官方文档
架构设计

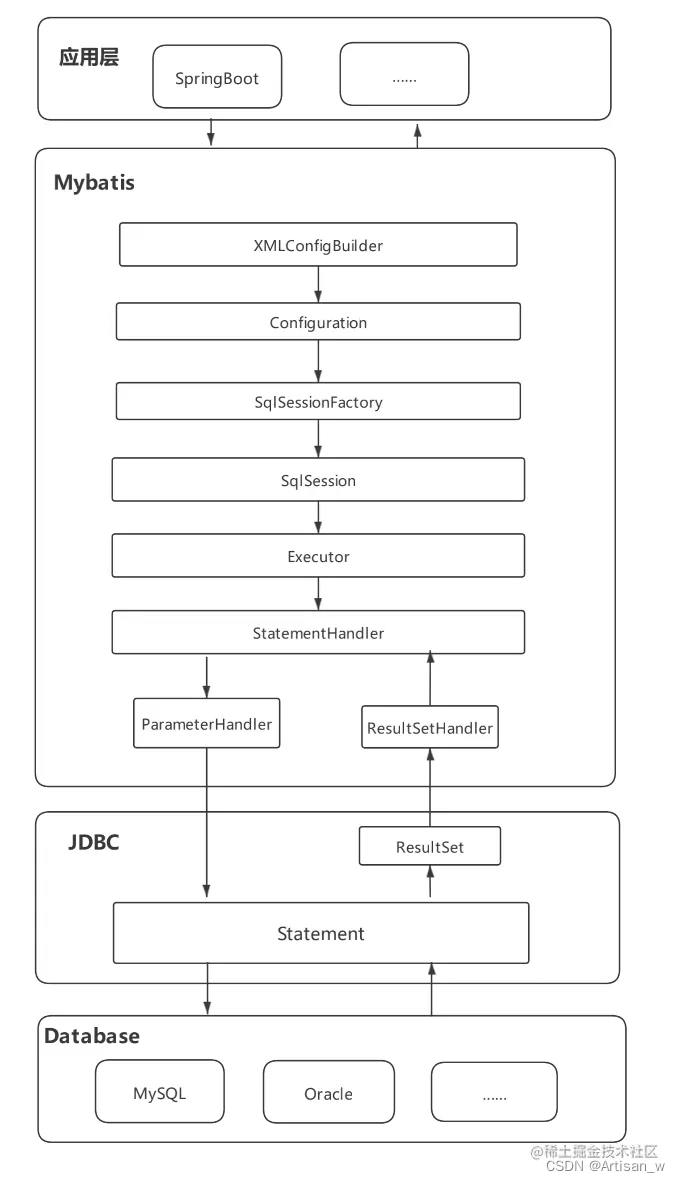
通过XMLConfigBuilder解析xml文件放到Configuration对象中
首先建立起Mapper的代理工程和代理
代理类
package cn.mybatis.binding;import java.io.Serializable;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.util.Map;public class MapperProxy<T> implements InvocationHandler, Serializable {private static final long serialVersionUID = -6424540398559729838L;private Map<String, String> sqlSession;private final Class<T> mapperInterface;public MapperProxy(Map<String, String> sqlSession, Class<T> mapperInterface) {this.sqlSession = sqlSession;this.mapperInterface = mapperInterface;}@Overridepublic Object invoke(Object o, Method method, Object[] objects) throws Throwable {if(Object.class.equals(method.getDeclaringClass())){return method.invoke(this, objects);}else {System.out.println("你被代理了");return sqlSession.get(mapperInterface.getName() + "." + method.getName());}}
}代理工厂
package cn.mybatis.binding;import java.lang.reflect.Proxy;
import java.util.Map;public class MapperProxyFactory<T> {private final Class<T> mapperInterface;public MapperProxyFactory(Class<T> mapperInterface) {this.mapperInterface = mapperInterface;}public T newInstance(Map<String, String> sqlSession){final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession,mapperInterface);return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[]{mapperInterface}, mapperProxy);}
}
被代理的接口
package cn.mybatis.dao;public interface IUserDao {public String queryUserName(String Id);}测试类
@Testpublic void test_MapperProxyFactory() {MapperProxyFactory<IUserDao> factory = new MapperProxyFactory<>(IUserDao.class);Map<String, String> sqlSession = new HashMap<>();sqlSession.put("cn.mybatis.dao.IUserDao.queryUserName", "模拟执行 Mapper.xml 中 SQL 语句的操作:查询用户姓名");IUserDao userDao = factory.newInstance(sqlSession);String res = userDao.queryUserName("10001");System.out.println(res);}
上面代码中sqlSession有所需要执行的sql
映射器的注册和使用
定义一个MapperRegistry,内部定义了一个Map
Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
Class<?>代表着执行sql的接口 MapperProxyFactory<?>是相应的代理工厂
它会扫描所有的接口类,放到这个map中,并且最终会被Configuration调用
SqlSession、DefaultSqlSession 用于定义执行 SQL 标准、获取映射器以及将来管理事务等方面的操作。基本我们平常使用 Mybatis 的 API 接口也都是从这个接口类定义的方法进行使用的。
SqlSessionFactory 是一个简单工厂模式,用于提供 SqlSession 服务,屏蔽创建细节,延迟创建过程。
XML文件解析
需要定义 SqlSessionFactoryBuilder 工厂建造者模式类,通过入口 IO 的方式对 XML 文件进行解析。
文件解析以后会存放到 Configuration 配置类中,接下来你会看到这个配置类会被串联到整个 Mybatis 流程中,所有内容存放和读取都离不开这个类
通过 Configuration 配置类进行存放,包括:添加解析 SQL、注册Mapper映射器。
比较重要的一个是上面提到的MapperRegistry
还定义了一个重要的 protected final Map<String, MappedStatement> mappedStatements = new HashMap<>();
是本章节新添加的 SQL 信息记录对象,包括记录:SQL类型、SQL语句、入参类型、出参类型等
TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry(); 类型别名注册机
这个Configuration最终会放到 DefaultSqlSession里
数据源解析、创建和使用
以事务接口 Transaction 和事务工厂 TransactionFactory 的实现,包装数据源 DruidDataSourceFactory 的功能。
当所有的数据源相关功能准备好后,就是在 XMLConfigBuilder 解析 XML 配置操作中,对数据源的配置进行解析以及创建出相应的服务,存放到 Configuration 的环境配置中。
最后在 DefaultSqlSession#selectOne 方法中完成 SQL 的执行和结果封装,最终就把整个 Mybatis 核心脉络串联出来了。
一次数据库的操作应该具有事务管理能力,而不是通过 JDBC 获取链接后直接执行即可。还应该把控链接、提交、回滚和关闭的操作处理。所以这里我们结合 JDBC 的能力封装事务管理。
通过环境构建 Environment.Builder 存放到 Configuration 配置项中,也就可以通过 Configuration 存在的地方都可以获取到数据源了。
SQL执行器(Executor)的定义与实现
回顾一下流程:
DefaultSqlSessionFactor开启operSession,并随着构造参数传递给DefaultSqlSession,并执行DefaultSqlSession#selectOne方法就会调用执行器执行
来看下执行器的操作:
1、定义一个Executor接口,这个接口定义了执行方法、事务获取和相应提交、回滚、关闭
2、在定义BaseExecutor一个抽象工厂进行模板方法的初步定义
3、SimpleExecutor会实现抽像接口进行具体执行,执行实际上是调用StatementHandler接口的具体实现来执行sql的
上面的执行器就完成了
再说下语句处理器:StatementHandler
语句处理器的核心包括了;准备语句、参数化传递参数、执行查询的操作,这里对应的 Mybatis 源码中还包括了 update、批处理、获取参数处理器等。
1、StatementHandler接口定义了具体执行sql的代码基本方法,包括准备语句、参数化传递参数、执行查询的操作
2、BaseStatementHandler 抽象基类实现了StatementHandler,并且增加定义了一系列的抽象方法交给其子类来处理
3、PreparedStatementHandler 预处理语句处理器继承BaseStatementHandler,进行具体的处理,包括 instantiateStatement 预处理 SQL、parameterize 设置参数,以及 query 查询的执行的操作。
SQL解析
解析、绑定、映射、事务、执行、数据源
SQL解析实际是解析XML或者注解中的SQL,并且将绑定的方法中的参数映射到SQL的过程
以XML为例解析:
XMLMapperBuilder、XMLStatementBuilder 分别处理映射构建器和语句构建器
1、映射构建器XMLMapperBuilder:
parse()方法中会间接调用configuration.addMapper 绑定映射器主要是把 namespace(全路径的接口类) 绑定到 Mapper 上。也就是注册到映射器注册机里。
具体实现是:
mapperRegistry.addMapper(type);//核如下knownMappers.put(type, new MapperProxyFactory<>(type)); type是具体的全路径接口类
2、映射构建器:XMLStatementBuilder
XMLStatementBuilder 语句构建器主要解析 XML 中 select|insert|update|delete 中的语句
parseStatementNode方法会解析各个参数
包括了语句的ID、参数类型、结果类型、命令(select|insert|update|delete),以及使用语言驱动器处理和封装SQL信息,当解析完成后写入到 Configuration 配置文件中的 Map<String, MappedStatement> 映射语句存放中。
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,resultSetTypeEnum, flushCache, useCache, resultOrdered,keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
3、XML脚本构建器解析:XMLScriptBuilder
XMLScriptBuilder#parseScriptNode 解析SQL节点的处理其实没有太多复杂的内容,主要是对 RawSqlSource 的包装处理。
4、SQL源码构建器:SqlSourceBuilder
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);String sql;//获取sqlif (configuration.isShrinkWhitespacesInSql()) {sql = parser.parse(removeExtraWhitespaces(originalSql));} else {sql = parser.parse(originalSql);}return new StaticSqlSource(configuration, sql, handler.getParameterMappings());}
参数处理器:策略模式实现
上面实现了解析 XML 中的所需要处理的 Mapper 信息,包括;SQL、入参、出参、类型,并对这些信息进行记录到 ParameterMapping 参数映射处理类中
这里将会使用一个接口实现ps.setXxx(i, parameter);对于所有的类型的支持
关于参数的处理,因为有很多的类型(Long\String\Object…),所以这里最重要的体现则是策略模式的使用
核心处理主要分为三块:类型处理、参数设置、参数使用;
1、以定义 TypeHandler 类型处理器策略接口,实现不同的处理策略,包括;Long、String、Integer 等
定义接口:
public interface TypeHandler<T> {/*** 设置参数*/void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;}
定义模板
public abstract class BaseTypeHandler<T> implements TypeHandler<T> {
f (parameter == null) {ps.setNull(i, jdbcType.TYPE_CODE);} else {setNonNullParameter(ps, i, parameter, jdbcType);}protected abstract void setNonNullParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;}
这里把一些异常处理都给去掉了,保留基本的逻辑。
当传入的参数不为空的时候,可以直接 ps.setNull(i, jdbcType.TYPE_CODE);,当为空的时候就交给具体的子类来处理
子类实现:
public class StringTypeHandler extends BaseTypeHandler<String> {@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType)throws SQLException {ps.setString(i, parameter);}@Overridepublic String getNullableResult(CallableStatement cs, int columnIndex)throws SQLException {return cs.getString(columnIndex);}
}Mybatis 源码中还有很多其他类型
2、类型策略处理器实现完成后,需要注册到处理器注册机(TypeHandlerRegistry )中,其他模块参数的设置还是使用都是从 Configuration 中获取到 TypeHandlerRegistry 进行使用。
public final class TypeHandlerRegistry {private final Map<JdbcType, TypeHandler<?>> JDBC_TYPE_HANDLER_MAP = new EnumMap<>(JdbcType.class);private final Map<Type, Map<JdbcType, TypeHandler<?>>> TYPE_HANDLER_MAP = new HashMap<>();private final Map<Class<?>, TypeHandler<?>> ALL_TYPE_HANDLERS_MAP = new HashMap<>();public TypeHandlerRegistry() {register(Long.class, new LongTypeHandler());register(long.class, new LongTypeHandler());register(String.class, new StringTypeHandler());register(String.class, JdbcType.CHAR, new StringTypeHandler());register(String.class, JdbcType.VARCHAR, new StringTypeHandler());}//...
}
这里在构造函数中,新增加了 LongTypeHandler、StringTypeHandler 两种类型的注册器。
3、了这样的策略处理器以后,在进行操作解析 SQL 的时候,就可以按照不同的类型把对应的策略处理器设置到 BoundSql#parameterMappings 参数里
这里主要通过反射的方式获取参数类型,然后 if 判断对应的参数类型是否在 TypeHandlerRegistry 注册器中,如果不在则拆解对象,按属性进行获取 propertyType 的操作。
4、参数使用
那么这里的链路关系;Executor#query - > SimpleExecutor#doQuery -> StatementHandler#parameterize -> PreparedStatementHandler#parameterize -> ParameterHandler#setParameters 到了 ParameterHandler#setParameters 就可以看到了根据参数的不同处理器循环设置参数。
每一个循环的参数设置,都是从 BoundSql 中获取 ParameterMapping 集合进行循环操作
设置参数时根据参数的 parameterObject 入参的信息,判断是否基本类型,如果不是则从对象中进行拆解获取(也就是一个对象A中包括属性b),处理完成后就可以准确拿到对应的入参值了。
基本信息获取完成后,则根据参数类型获取到对应的 TypeHandler 类型处理器,也就是找到 LongTypeHandler、StringTypeHandler 等,确定找到以后,则可以进行对应的参数设置了 typeHandler.setParameter(ps, i + 1, value, jdbcType) 通过这样的方式把我们之前硬编码的操作进行解耦。
封装处理结果
主要是针对JDBC查出来结果映射到标签resultType中去。
我们拿到了 Mapper XML 中所配置的返回类型,解析后把从数据库查询到的结果,反射到类型实例化的对象上。
MapperBuilderAssistant 映射器的助手类,方便我们对参数的统一包装处理,按照职责归属的方式进行细分解耦。
在执行完成sql后得到一个结果会在 DefaultResultSetHandler 进行信息封装
1、对象创建
调用链路:handleResultSet->handleRowValuesForSimpleResultMap->getRowValue->createResultObject
关键代码
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix) throws SQLException {final Class<?> resultType = resultMap.getType();final MetaClass metaType = MetaClass.forClass(resultType);if (resultType.isInterface() || metaType.hasDefaultConstructor()) {// 普通的Bean对象类型return objectFactory.create(resultType);}throw new RuntimeException("Do not know how to create an instance of " + resultType);
}
2、属性填充
对象实例化完成后,就是根据 ResultSet 获取出对应的值填充到对象的属性中,但这里需要注意,这个结果的获取来自于 TypeHandler#getResult 接口新增的方法,由不同的类型处理器实现,通过这样的策略模式设计方式就可以巧妙的避免 if···else 的判断处理。
columnName 是属性名称,根据属性名称,按照反射工具类从对象中获取对应的 properyType 属性类型,之后再根据类型获取到 TypeHandler 类型处理器。有了具体的类型处理器,在获取每一个类型处理器下的结果内容就更加方便了。
获取属性值后,再使用 MetaObject 反射工具类设置属性值,一次循环设置完成以后,这样一个完整的结果信息 Bean 对象就可以返回了。返回后写入到 DefaultResultContext#nextResultObject 上下文中
注解
MapperAnnotationBuilder中处理注解,这个类在构造函数中配置需要解析的注解,并提供解析方法处理语句的解析。
整个类基本基于Method来获取参数类型、返回类型和注解类型,并完成整个解析过程。