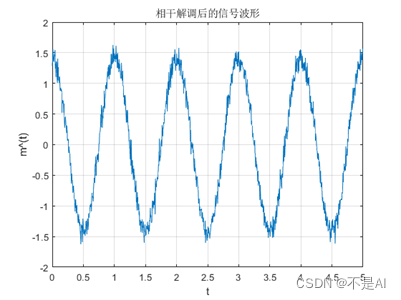
云计算历年题整理
第一大题纯计算
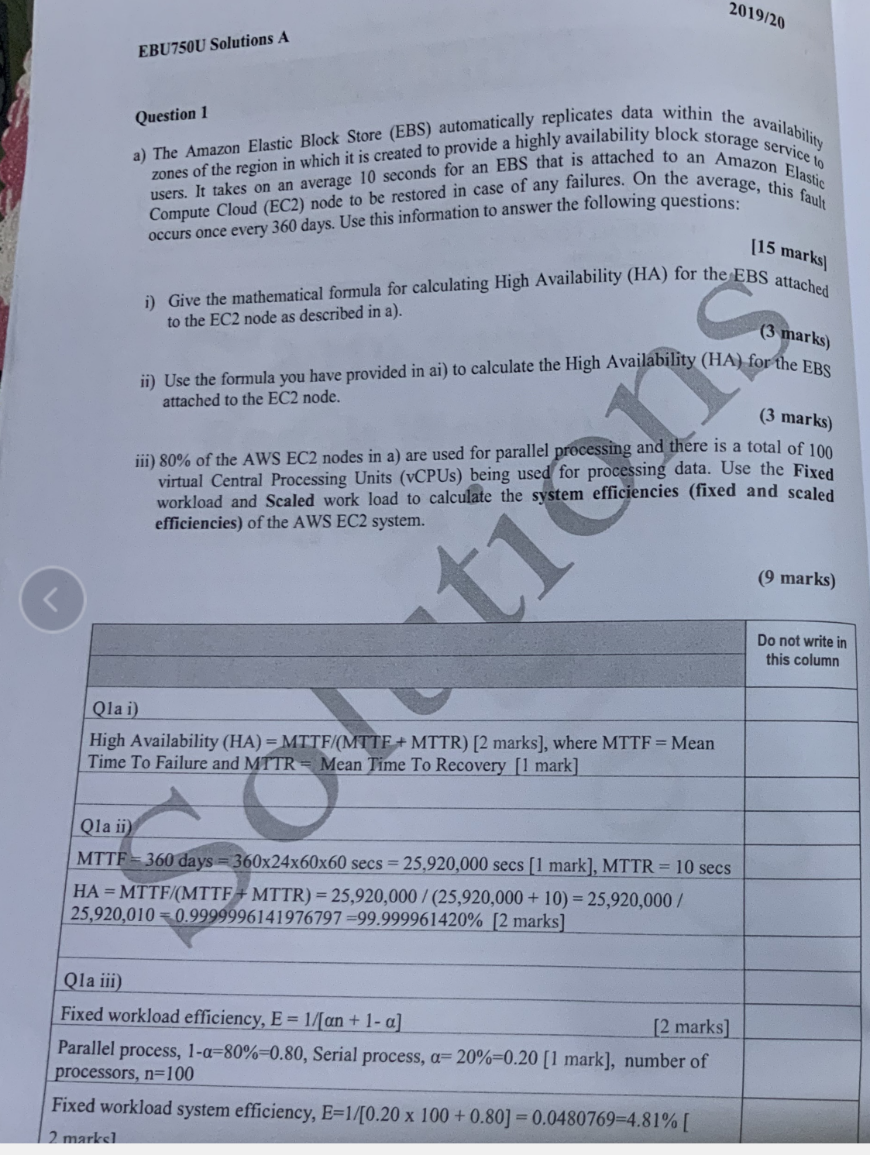



第一大题4或n个xx(只答若干个短语)







第一大题AWS描述名词






第二大题CUDA代码






第二大题描述名词(很多和第一大题一样与AWS有关但是比第一大题难)




第二大题计算
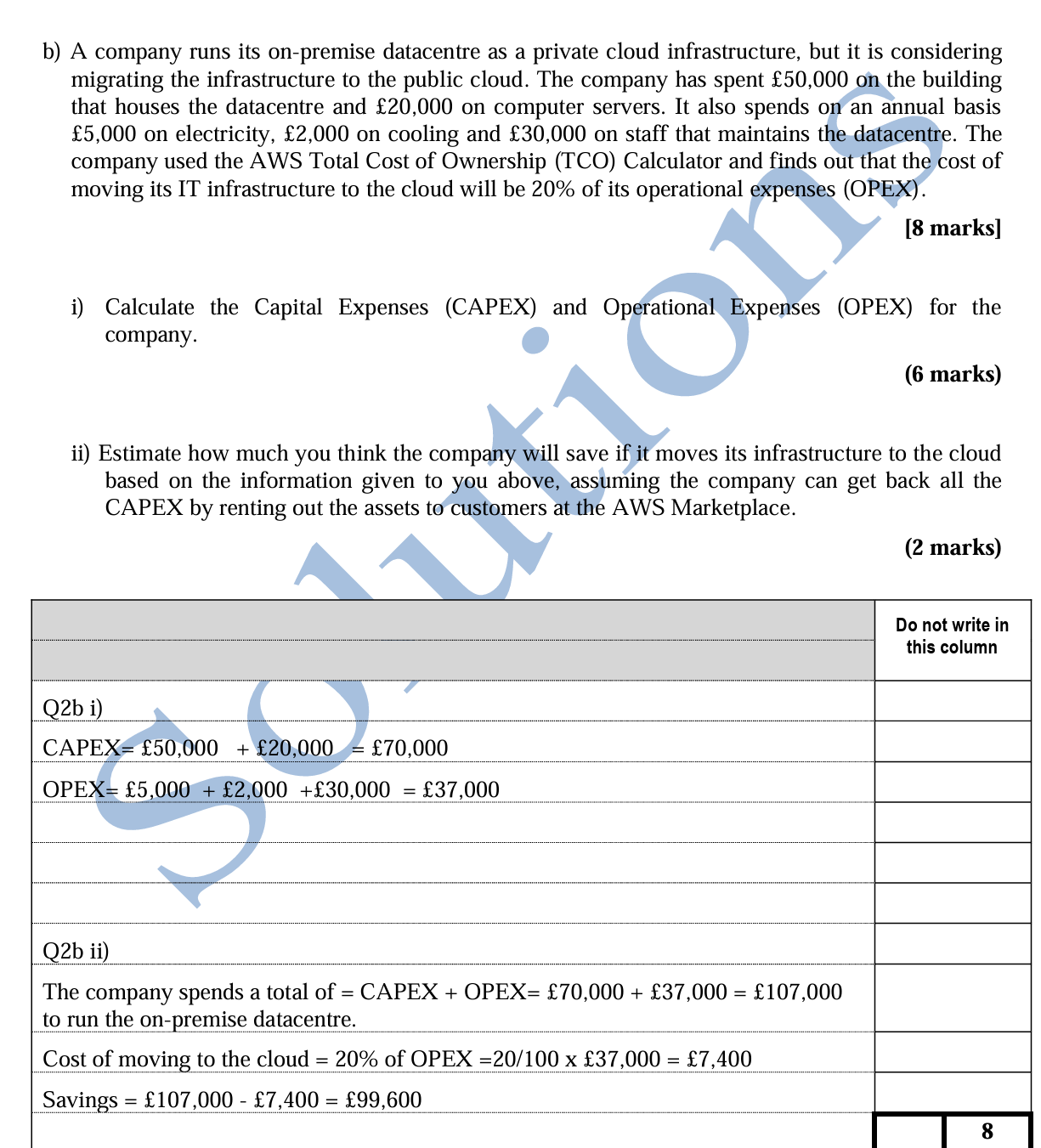

第三大题Map/Reduce项目涉及代码
下列Map/Reduce伪代码的结果是什么?解释它并举例说明映射器/还原器之间的信息交换

编写一个Map/Reduce Java程序来计算每个事件类别中最受欢迎的事件(即最常预订的古典音乐会,爵士音乐会,流行音乐会等)。包括注释来解释代码的作用。您还可以使用伪代码来编写规范,或者用图表来说明输入、映射、减少和输出块之间的数据流。

第三大题也与map有关但不是代码
关于Map/Reduce的性能:定义并行计算中的加速概念;使用Amdahl定律,计算用10个处理器运行此作业时可实现的最大加速,注意8%的计算作业必须顺序执行。

关于Map/Reduce的性能:描述阿姆达尔定律,以及顺序计算和并行计算之间的区别。说出Hadoop中必须按顺序执行的一个阶段;如果95%的计算作业必须顺序执行,那么在跨8个处理器运行该作业时可实现的最大加速是多少?同样,对于同一个作业,当跨1000个处理器运行该作业时,可实现的最大加速是多少?用阿姆达尔定律来回答


涉及到Map/Reduce的Combiner:什么是Combiner,用处?它和减速器有什么不同?使用组合器是可选的还是强制的;简要说明组合器必须遵守的两条规则。


在该场景中,Hadoop使用10个mapper和2个reducer来完成计算,每个Mapper发出多少中间键:值对?有多少唯一的键被馈送到每个Reducer?

关于Map-Reduce的数据过滤:Map-Reduce作业中数据过滤的目的是什么?给出一个数据过滤的例子;为什么数据过滤是“Mapper唯一的工作”?

第三大题HDFS
涉及Hadoop计算作业执行:用箭头(→)连接Hadoop计算任务对应负责的守护进程


关于Hadoop分布式文件系统的:NameNode在HDFS中的职责是什么;用合适的图表解释HDFS的写操作(例如,如何创建一个新文件并将数据写入HDFS);为什么HDFS默认为每个块存储三个单独的副本?为什么在大型集群中将三个副本分散到不同的物理机架上是有用的?


关于分布式处理系统的弹性:在分布式系统的背景下,什么是“五九可用性”?请解释这与“单点故障”的概念之间的关系,以及这可能对分布式系统产生的负面影响;HDFS (Hadoop Distributed File System)如何检测数据块损坏;如果Map任务中的一个失败,Map/Reduce作业是否会完成?应用程序主机和节点管理器如何检测Map任务的失败并对其作出反应?

第四大题DNS描述名词
关于Map/Reduce之外的大数据平台:什么是内存处理?讨论Hadoop Map/Reduce与现代内存处理系统(如Apache Spark)相比的的主要性能限制,用一个例子说明两者的区别;在Apache Spark的背景下,什么是弹性分布式数据集(RDD) ?解释两种类型的RDD操作,并为每种操作提供一个示例,例如,如何通过编程操作创建和修改RDD。

什么是内容交付网络中的DNS缓存?DNS缓存的两个好处。

与内容交付网络(cdn)有关:什么是内容分发网络(CDN)?解释内容交付网络是如何工作的;cdn中的DNS重定向是什么?简要解释不同的DNS重定向类型及其优缺点;点对点(P2P)网络是什么?解释P2P网络相对于客户机-服务器网络的三个好处。


第四大题Cloud Database描述
与云数据库有关:解释以下这些用于实现数据分区和复制的技术:内存缓存、读写分离、High可用性、集群和数据分片;SQL数据库以牺牲分区为代价提供了强一致性和可用性,而不同的NoSQL数据库采用不同的基于cap的权衡,那么亚马逊发电机系统做了哪些权衡?





第四大题其它描述



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/231104.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!