目录
- 什么是消息中间件
- 为什么使用消息中间件
- 流量削峰
- 应用解耦
- 异步处理
- 主流消息中间件及选型
- 选取原则
- RabbitMQ
- RocketMQ
- Kafka
- 如何选择
- 消息中间件应用场景
- 电商秒杀案例
- 拉勾B端C端数据同步案例
- 支付宝购买电影票
什么是消息中间件
维基百科对消息中间件的解释:面向消息的系统(消息中间件)是在分布式系统中完成消息的发送和接收的基础软件。
消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。
消息中间件就是在通信的上下游之间截断:break it,Broker,然后利用中间件解耦、异步的特性,构建弹性、可靠、稳定的系统。
为什么使用消息中间件
异步处理、流量削峰、限流、缓冲、排队、最终一致性、消息驱动等需求的场景都可以使用消息中间件。
流量削峰
如果订单系统每秒最多能处理一万次的订单,这个处理能力应付正常时段的下单是绰绰有余的,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果每秒有两万次的下单操作,系统是处理不了的,那么只能限制订单超过一万后的用户不能下单,这样很不人性化的(我可能等待,怎么能直接告诉我下不了单呢?)。此时如果使用 MQ 之后,那么就可以取消这个限制了,将一秒内下的订单分散成一段时间来处理,这时可能有些用户在下单十几秒之后才能收到下单成功的操作,但是也有比不能下单的体验要好。

应用解耦
以电商系统为例,应用中有订单系统、库存系统、物流系统、支付系统。用户在创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出现故障,都会造成下单操作异常。当使用了 MQ 之后,系统间调用的问题就会减少很多,如:物流系统因为发生故障,需要几分钟来修复,在这几分钟之内,物流系统要处理的消息会被缓存在 MQ 之后,不会影响到用户的正常下单操作的。当物流系统恢复之后,继续处理订单信息即可。在整个操作中间,下单的用户是感受不到物流系统出现故障,提高的系统的可用性。

异步处理
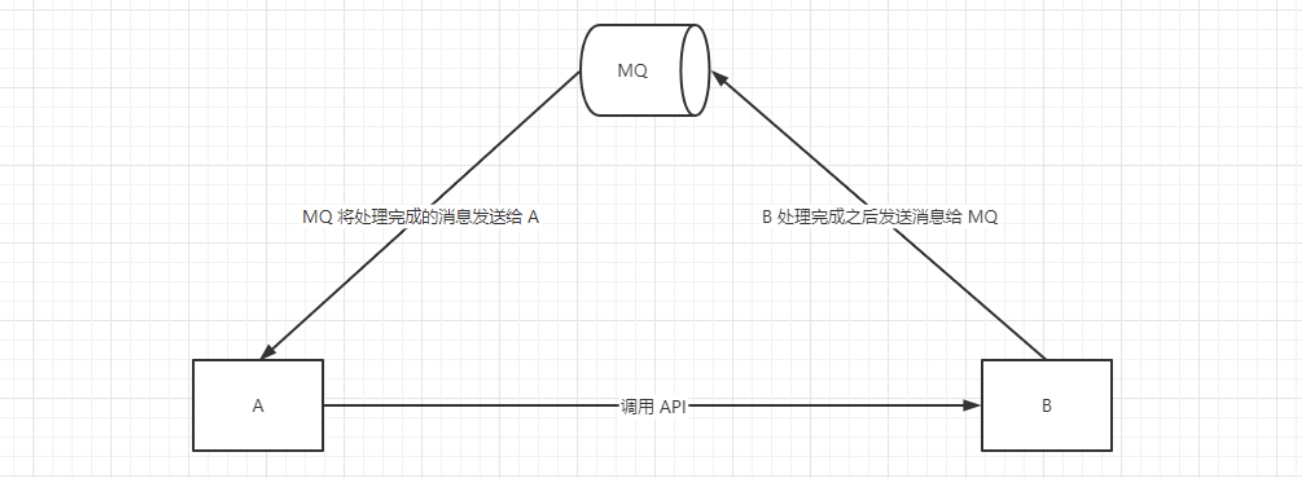
有些服务间调用是异步的,例如:A 调用 B ,B 需要花费很长时间去执行,但是 A 需要知道 B 什么时候可以执行完毕,以前有两种处理方式:1)A 每过一段时间就去轮询调用 B 提供的查询 API 。2) A 提供一个 callback 的 API ,B 执行完毕会后调用这个 API 告诉 A 执行完毕。这两种方式都不是很优雅,使用 MQ 可以方便的解决这个问题。A 调用 B 服务后,只需要监督 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ ,MQ 会将此消息转发给 A 服务,这样 A 服务既不用循环调用 B 的查询 API ,也不用提供 callback 的 API 。同样,B 也不需要做这些操作,A 服务还能及时得到异步处理成功的消息。
主流消息中间件及选型
当前业界比较流行的开源消息中间件包括:ActiveMQ、RabbitMQ、RocketMQ、Kafka、ZeroMQ等,其中应用最为广泛的要数RabbitMQ、RocketMQ、Kafka这三款。
Redis在某种程度上也可以是实现类似“Queue”和“Pub/Sub”的机制,严格意义上不算消息中间件。
选取原则
首先,产品应该是开源的。开源意味着如果队列使用中遇到bug,可以很快修改,而不用等待开发者的更新。
其次,产品必须是近几年比较流行的,要有一个活跃的社区。这样遇到问题很快就可以找到解决方法。同时流行也意味着bug较少。流行的产品一般跟周边系统兼容性比较好。
最后,作为消息队列,要具备以下几个特性:
1、消息传输的可靠性:保证消息不会丢失。
2、支持集群,包括横向扩展,单点故障都可以解决。
3、性能要好,要能够满足业务的性能需求。
RabbitMQ
RabbitMQ开始是用在电信业务的可靠通信的,也是少有的几款支持AMQP协议的产品之一。
优点
- 轻量级,快速,部署使用方便
- 支持灵活的路由配置。RabbitMQ中,在生产者和队列之间有一个交换器模块。根据配置的路由规则,生产者发送的消息可以发送到不同的队列中。路由规则很灵活,还可以自己实现。
- RabbitMQ的客户端支持大多数的编程语言。
缺点
- 如果有大量消息堆积在队列中,性能会急剧下降
- RabbitMQ的性能在Kafka和RocketMQ中是最差的,每秒处理几万到几十万的消息。如果应用要求高的性能,不要选择RabbitMQ。
- RabbitMQ是Erlang开发的,功能扩展和二次开发代价很高。
RocketMQ
RocketMQ是一个开源的消息队列,使用java实现。借鉴了Kafka的设计并做了很多改进。RocketMQ主要用于有序,事务,流计算,消息推送,日志流处理,binlog分发等场景。经过了历次的双11考验,性能,稳定性可可靠性没的说。
优点
- RocketMQ几乎具备了消息队列应该具备的所有特性和功能。
- java开发,阅读源代码、扩展、二次开发很方便。
- 对电商领域的响应延迟做了很多优化。在大多数情况下,响应在毫秒级。如果应用很关注响应时间,可以使用RocketMQ。
- 性能比RabbitMQ高一个数量级,每秒处理几十万的消息。
缺点
- 跟周边系统的整合和兼容不是很好。
Kafka
Kafka的可靠性,稳定性和功能特性基本满足大多数的应用场景。
跟周边系统的兼容性是数一数二的,尤其是大数据和流计算领域,几乎所有相关的开源软件都支持Kafka。
Kafka高效,可伸缩,消息持久化。支持分区、副本和容错。
Kafka是Scala和Java开发的,对批处理和异步处理做了大量的设计,因此Kafka可以得到非常高的性能。它的异步消息的发送和接收是三个中最好的,但是跟RocketMQ拉不开数量级,每秒处理几十万的消息。
如果是异步消息,并且开启了压缩,Kafka最终可以达到每秒处理2000w消息的级别。但是由于是异步的和批处理的,延迟也会高,不适合电商场景。
如何选择
特点如下

基于以上特点,选型可参考如下:
-
Kaka:Kafka 的主要特点是基于 pull 的模式来处理消息,追求吞吐量,一开始的目的就是用于日志收集和传输,适合产生了大量数据的互联网服务的数据收集业务。大型公司建议选用,如果有日志收集功能,首选 Kafka 。
-
RocketMQ:天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入的时候,后端可能无法及时处理的情况。RocketMQ 在稳定性上可能更值得信赖,因为这些场景在阿里的双 11 经历了多次考验。
-
RabbitMQ:结合 Erlang 语言本身的并发优势,性能好,时效性 us 级,社区活跃度高,管理界面用起来十分方便,中小型公司优先选择功能完备的 RabbitMQ 。
消息中间件应用场景
消息中间件的使用场景非常广泛,比如,12306购票的排队锁座,电商秒杀,大数据实时计算等。
电商秒杀案例
比如6.18,活动从0:00开始,仅限前 200 名,秒杀即将开始时,用户会疯狂刷新 APP或者浏览器来保证自己能够尽早的看到商品。
- 当秒杀开始前,用户在不断的刷新页面,系统应该如何应对高并发的读请求呢?
- 在秒杀开始时,大量并发用户瞬间向系统请求生成订单,扣减库存,系统应该如何应对高并发的写请求呢?
1. 系统应该如何应对高并发的读请求
- 使用缓存策略将请求挡在上层中的缓存中
- 能静态化的数据尽量做到静态化
- 加入限流(比如对短时间之内来自某一个用户,某一个IP、某个设备的重复请求做丢弃处理)
2. 系统应该如何应对高并发的写请求
生成订单,扣减库存,用户这些操作不经过缓存直达数据库。如果在 1s内,有 1 万个数据连接同时到达,系统的数据库会濒临崩溃。如何解决这个问题呢?我们可以使用 消息队列。
消息队列的作用:
- 削去秒杀场景下的峰值写流量——流量削峰
- 通过异步处理简化秒杀请求中的业务流程——异步处理
- 解耦,实现秒杀系统模块之间松耦合——解耦
上面三点分别如何做?
- 流量削峰
将秒杀请求暂存于消息队列,业务服务器响应用户“秒杀结果正在处理中。。。”,释放系统资源去处理其它用户的请求。
削峰填谷,削平短暂的流量高峰,消息堆积会造成请求延迟处理,但秒杀用户对于短暂延迟有一定容忍度。
秒杀商品有 1000 件,处理一次购买请求的时间是 500ms,那么总共就需要 500s 的时间。这时你部署 10 个队列处理程序,那么秒杀请求的处理时间就是 50s,也就是说用户需要等待 50s 才可以看到秒杀的结果,这是可以接受的。这时会并发 10 个请求到达数据库,并不会对数据库造成很大的压力。
- 异步处理
先处理主要的业务,异步处理次要的业务。如主要流程是生成订单、扣减库存;次要流程比如购买成功之后会给用户发优惠券,增加用户的积分。此时秒杀只要处理生成订单,扣减库存的耗时,发放优惠券、增加用户积分异步去处理了。
- 解耦
实现秒杀系统模块之间松耦合。
将秒杀数据同步给数据团队,有两种思路:
- 使用 HTTP 或者 RPC 同步调用,即提供一个接口,实时将数据推送给数据服务。系统的耦合度高,如果其中一个服务有问题,可能会导致另一个服务不可用。
- 使用消息队列将数据全部发送给消息队列,然后数据服务订阅这个消息队列,接收数据进行处理。
拉勾B端C端数据同步案例
拉勾网站分B端和C端,B端面向企业用户,C端面向求职者。
这两个模块业务处理逻辑不同,数据库表结构不同,实际上是处于解耦的状态。但是各自又需要对方的数据,需要共享>如:
- 当C端求职者在更新简历之后,B端企业用户如何尽早看到该简历更新?
- 当B端企业用户发布新的职位需求后,C端用户如何尽早看到该职位信息?
无论是B端还是C端,都有各自的搜索引擎和缓存,B端需要获取C端的更新以更新搜索引擎和缓存;C端需要获取B端的更新以更新C端的搜索引擎与缓存。
如何解决B端C端数据共享的问题?
- 同步方式:B端和C端通过RPC或WebService的方式发布服务,让对方来调用,以获取对方的信息。求职者每更新一次简历,就调用一次B端的服务,进行数据的同步;B端企业用户每更新职位需求,就调用C端的服务,进行数据的同步。
- 异步方式:使用消息队列,B端将更新的数据发布到消息队列,C端将更新的数据发布到消息队列,B端订阅C端的消息队列,C端订阅B端的消息队列。
使用同步方式,B端和C端耦合比较紧密,如果其中一个服务有问题,可能会导致另一个服务不可用。比如C端的RPC挂掉,企业用户有可能无法发布新的职位信息,因为发布了对方也看不到;B端的RPC挂掉,求职者可能无法更新简历,因为即使简历更新了,对方也看不到。
你可能会想,可以让B端或C端在对方RPC挂掉的时候,先将该通知消息缓存起来,等对方服务恢复之后再进行同步。
这正是引入异步方式,使用消息队列的目的。
使用消息队列的异步方式,对B端C端进行解耦,只要消息队列可用,双方都可以将需要同步的信息发送到消息队列,对方在收到消息队列推送来的消息的时候,各自更新自己的搜索引擎,更新自己的缓存数据。
支付宝购买电影票
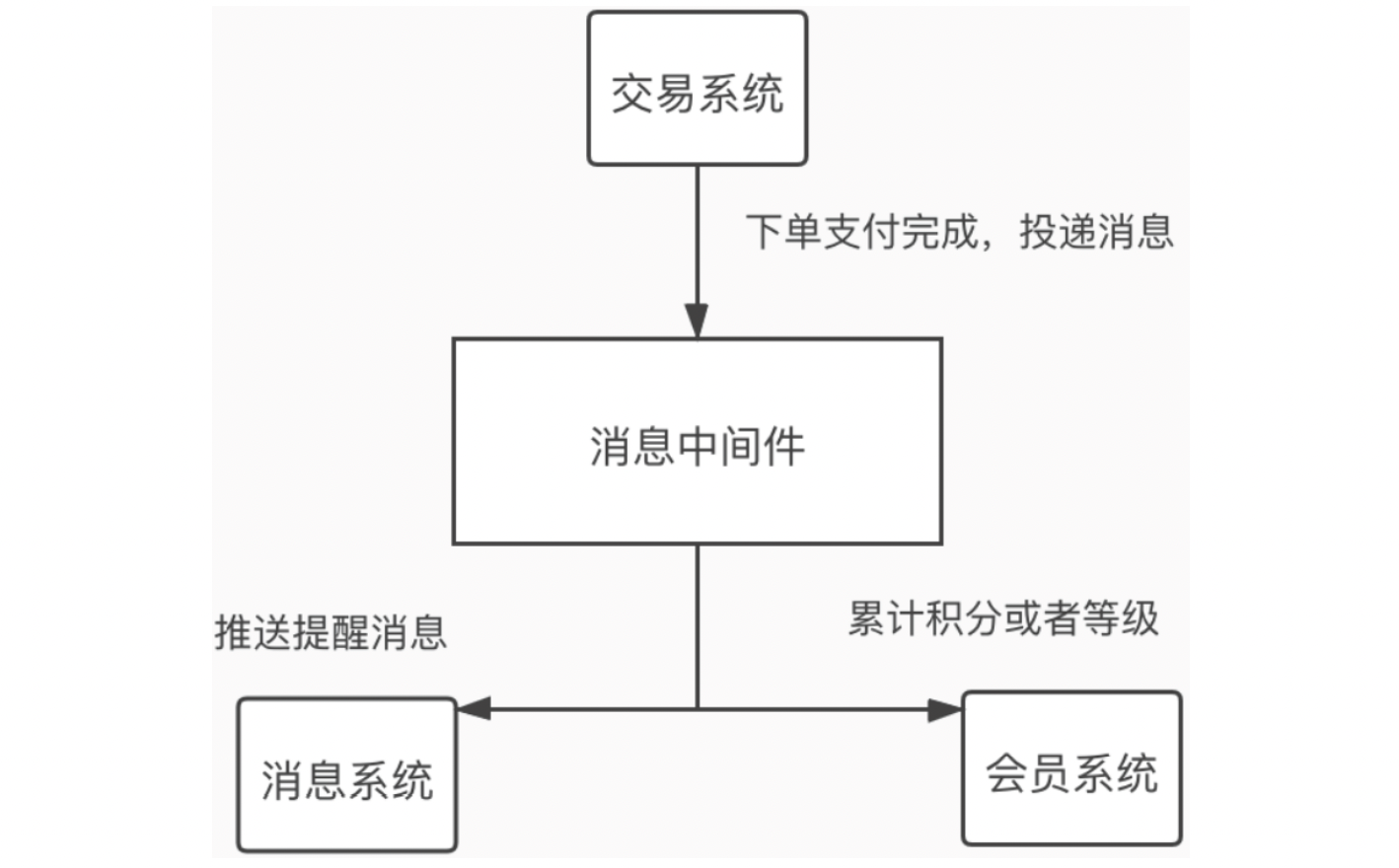
如上图,用户在支付宝购买了一张电影票后很快就收到消息推送和短信(电影院地址、几号厅、座位号、场次时间等),同时用户会积累一定的会员积分。
这里,交易系统并不需要一直等待消息送达等动作都完成后才返回成功,允许一定延迟和瞬时不一致(最终一致性),而且后面两个动作通常可以并发执行。
如果后期监控大盘想要获取实时交易数据,只需要新增个消费者程序并订阅该消息即可,交易系统对此并不感知,松耦合。