目录
一、SimpleCache SimObject
二、Implementing the SimpleCache
1、getSlavePort()
2、handleRequest()
3、AccessEvent()
4、accessTiming()
(1)缓存命中:sendResponse()
(2)缓存未命中:
三、Functional cache logic
1、insert()
四、Creating a config file for the cache
五、Adding statistics to the cache
六、测试
官网教程:gem5: Creating a simple cache object
本小节是基于上一教程创建的内存对象框架的基础上添加缓存逻辑。
一、SimpleCache SimObject
和前文中的SConscript文件一样,首先要修改SConscript文件
Import('*')SimObject('SimpleCache.py', sim_objects=['SimpleCache'])Source('simple_cache.cc')DebugFlag('SimpleCache', "For Learning gem5 Part 2.")创建(修改)了SConscript文件之后,可以创建SimpleCache SimObject的Python文件。把这个基于上述上个教程修改后的简单内存对象称为SimpleCache,并在src/learning_gem5/part2目录下创建SimpleCache SimObject的Python文件(类的定义和成员变量的初始化)。
文件名:SimpleCache.py
from m5.params import *
from m5.proxy import *
from MemObject import MemObjectclass SimpleCache(MemObject):type = 'SimpleCache'cxx_header = "learning_gem5/simple_cache/simple_cache.hh"cpu_side = VectorSlavePort("CPU side port, receives requests")mem_side = MasterPort("Memory side port, sends requests")latency = Param.Cycles(1, "Cycles taken on a hit or to resolve a miss")size = Param.MemorySize('16kB', "The size of the cache")system = Param.System(Parent.any, "The system this cache is part of")这个SimObject文件与上一章的SimpleMemobj.py文件有几个不同之处。
-
首先,SimpleCache对象中有一些额外的参数,即缓存访问的延迟和缓存的大小。parameters-chapter对这些SimObject参数进行了更详细的介绍。
-
接下来,我们包括一个
System参数,它是指向该缓存所连接的主系统的指针。这是为了在初始化缓存时从系统对象获取缓存块大小所必需的。为了引用与此缓存连接的系统对象,我们使用一个特殊的代理参数(proxy parameter)。在本例中,我们使用Parent.any。在Python配置文件中,当实例化一个
SimpleCache时,该代理参数会遍历SimpleCache实例的所有父级,以查找与System类型匹配的SimObject。由于我们通常将System用作根SimObject,因此您经常会看到使用此代理参数解析system参数。 -
SimpleCache与SimpleMemobj的第三个也是最后一个区别是,SimpleCache不是具有两个具名的CPU端口(inst_portanddata_port)),而是使用了另一个特殊的参数:VectorPorts。VectorPorts的行为与常规端口类似(例如,它们通过getMasterPort和getSlavePort进行解析),但它们允许该对象连接到多个对等方。然后,在解析函数中,我们之前忽略的参数(PortID idx)用于区分不同的端口。通过使用矢量端口,该缓存可以比SimpleMemobj更灵活地连接到系统中。
二、Implementing the SimpleCache
SimpleCache 的大部分代码与SimpleMemobj相同。在构造函数和关键的内存对象函数中有一些变化。
首先,在构造函数中,我们需要动态创建CPU端口,并根据SimObject参数初始化额外的成员函数。(就是类的.cc文件)
文件名:simple_cache.cc
SimpleCache::SimpleCache(SimpleCacheParams *params) :
//通过调用基类MemObject的构造函数来初始化基类部分.MemObject(params),
//将参数params中的latency赋值给成员变量latency,表示缓存访问的延迟.latency(params->latency),
//访问参数params中的system成员变量,并调用cacheLineSize()函数来获取缓存块大小,并将其赋值给成员变量blockSizeblockSize(params->system->cacheLineSize()),
//计算缓存的容量,将参数params中的size除以blockSize,并将结果赋值给成员变量capacitycapacity(params->size / blockSize),
//创建一个名为params->name + ".mem_side"的内存端口,并将其赋值给成员变量memPort,用于与内存子系统通信memPort(params->name + ".mem_side", this),
//将成员变量blocked、outstandingPacket和waitingPortId初始化为false、nullptr和-1,用于跟踪缓存的状态blocked(false), outstandingPacket(nullptr), waitingPortId(-1)
{for (int i = 0; i < params->port_cpu_side_connection_count; ++i) {cpuPorts.emplace_back(name() + csprintf(".cpu_side[%d]", i), i, this);}
}在这个函数中,使用系统参数中的cacheLineSize来设置缓存的blockSize。还根据blockSize和参数初始化了capacity,并初始化了其他下面需要使用的成员变量。最后,根据与该对象连接的数量创建了一定数量的CPUSidePort。由于在SimObject的Python文件中将cpu_side端口声明为VectorSlavePort,所以该参数自动具有变量port_cpu_side_connection_count。这是根据参数的Python名称确定的。对于每个连接,我们将在SimpleCache类中声明的cpuPorts向量中添加一个新的CPUSidePort。
我们还向CPUSidePort添加了一个额外的成员变量来保存其ID,并将其作为参数添加到了构造函数中。
接下来,需要实现getMasterPort和getSlavePort函数。getMasterPort与SimpleMemobj完全相同。对于getSlavePort,我们现在需要根据请求的ID返回相应的端口。
1、getSlavePort()
BaseSlavePort&
SimpleCache::getSlavePort(const std::string& if_name, PortID idx)
{if (if_name == "cpu_side" && idx < cpuPorts.size()) {return cpuPorts[idx];} else {return MemObject::getSlavePort(if_name, idx);}
}在SimpleCache中实现CPUSidePort和MemSidePort与SimpleMemobj几乎相同。唯一的区别是需要在handleRequest函数中添加一个额外的参数,即请求来源的端口id。如果没有这个id,就无法将响应正确地转发到相应的端口。SimpleMemobj根据原始请求是指令还是数据访问来确定要发送回复的端口。但SimpleCache使用的是端口的向量,而不是命名端口,无法直接根据指令或数据访问来确定响应应该发送到哪个端口。
2、handleRequest()
SimpleCache中新的handleRequest函数与SimpleMemobj中的handleRequest函数有两个不同之处。
- ① 首先,它存储了请求的端口ID。由于SimpleCache是阻塞的,并且一次只允许一个请求处于未完成状态,因此我们只需要保存一个端口ID。
- ② 其次,访问缓存需要一定的时间。因此,需要考虑访问缓存标签和缓存数据的延迟。我们为缓存对象添加了一个额外的参数,并且在
handleRequest函数中,使用一个事件来暂停请求所需的时间。我们在未来的latency周期中安排了一个新的事件。clockEdge函数返回未来第n个周期发生的时钟周期(the tick that the nth cycle in the future occurs on)。
bool
SimpleCache::handleRequest(PacketPtr pkt, int port_id)
{if (blocked) {return false;}DPRINTF(SimpleCache, "Got request for addr %#x\n", pkt->getAddr());blocked = true;waitingPortId = port_id;schedule(new AccessEvent(this, pkt), clockEdge(latency));return true;
}3、AccessEvent()
AccessEvent是比前几个教程(events-chapter)中使用的EventWrapper更复杂一些。在SimpleCache中,使用一个新的类代替EventWrapper。不使用EventWrapper的原因是,需要将数据包(pkt)从handleRequest传递给事件处理函数。下面的代码是AccessEvent类的实现。
我们只需要实现process函数,该函数调用我们想要用作事件处理程序的函数,本例中为accessTiming。还将AutoDelete标志传递给事件构造函数,这样就不需要担心释放动态创建对象的内存。在process函数执行完毕后,事件代码将自动删除该对象(即自动释放动态创建的对象内存)。
class AccessEvent : public Event
{private:SimpleCache *cache;PacketPtr pkt;public:AccessEvent(SimpleCache *cache, PacketPtr pkt) :Event(Default_Pri, AutoDelete), cache(cache), pkt(pkt){ }void process() override {cache->accessTiming(pkt);}
};4、accessTiming()
事件处理程序。
void
SimpleCache::accessTiming(PacketPtr pkt)
{bool hit = accessFunctional(pkt);if (hit) {pkt->makeResponse();sendResponse(pkt);} else {<miss handling>}
}(1)缓存命中:sendResponse()
这个函数首先对缓存进行功能性访问(functionally accesses)。这个函数accessFunctional(下面描述)执行缓存的功能访问,如果命中则进行读写操作,如果未命中则返回访问失败。
如果访问命中,只需要对数据包进行响应。为了响应,首先调用数据包的makeResponse函数。这将数据包从请求数据包转换为响应数据包。例如,如果数据包中的内存命令是ReadReq,则会转换为ReadResp。写操作类似。然后,可以将响应发送回给CPU。
sendResponse函数执行的操作与SimpleMemobj中的handleResponse函数类似,但它使用waitingPortId将数据包发送到正确的端口。在这个函数中,需要在调用sendPacket之前将SimpleCache标记为未阻塞状态,以防止CPU端的对等方立即调用sendTimingReq。然后,如果SimpleCache现在可以接收请求并且端口需要发送重试,尝试向CPU端口发送重试。
void SimpleCache::sendResponse(PacketPtr pkt)
{int port = waitingPortId;blocked = false;waitingPortId = -1;cpuPorts[port].sendPacket(pkt);for (auto& port : cpuPorts) {port.trySendRetry();}
}(2)缓存未命中:<miss handling>
回到accessTiming函数,现在需要处理缓存未命中的情况。
在未命中时,首先需要检查丢失的数据包是否是对整个缓存块的请求。
① 如果数据包对齐,并且请求的大小与缓存块的大小相同,那么我们可以将请求直接转发到内存,就像在SimpleMemobj中一样。
② 然而,如果数据包小于缓存块的大小,那么需要创建一个新的数据包,从内存中读取整个缓存块。在这种情况下,无论数据包是读请求还是写请求,都会向内存发送读请求,以将缓存块的数据加载到缓存中。在写操作的情况下,数据将在我们从内存加载数据后在缓存中进行写入。
然后,我们创建一个大小为blockSize的新数据包,并调用allocate函数为从内存中读取的数据在Packet对象中分配内存。请注意:这个内存将在释放数据包时被释放。我们在数据包中使用原始请求对象,以便内存端的对象知道原始请求者和原始请求类型,以便进行统计。
最后,将原始数据包指针(pkt)保存在成员变量outstandingPacket中,以便在SimpleCache接收到响应时可以恢复它。然后,我们通过内存端口发送新的数据包。
void
SimpleCache::accessTiming(PacketPtr pkt)
{bool hit = accessFunctional(pkt);if (hit) {pkt->makeResponse();sendResponse(pkt);} else {Addr addr = pkt->getAddr();Addr block_addr = pkt->getBlockAddr(blockSize);unsigned size = pkt->getSize();if (addr == block_addr && size == blockSize) {DPRINTF(SimpleCache, "forwarding packet\n");memPort.sendPacket(pkt);} else {DPRINTF(SimpleCache, "Upgrading packet to block size\n");panic_if(addr - block_addr + size > blockSize,"Cannot handle accesses that span multiple cache lines");assert(pkt->needsResponse());MemCmd cmd;if (pkt->isWrite() || pkt->isRead()) {cmd = MemCmd::ReadReq;} else {panic("Unknown packet type in upgrade size");}PacketPtr new_pkt = new Packet(pkt->req, cmd, blockSize);new_pkt->allocate();outstandingPacket = pkt;memPort.sendPacket(new_pkt);}}
}——————上述accessTiming(PacketPtr pkt)代码的个人解释,教程中没有——————
这段代码是SimpleCache中的accessTiming函数的实现。它的作用是处理访存请求,并根据访存结果进行相应的操作。
代码首先调用accessFunctional函数对缓存进行功能性访问,返回一个布尔值表示是否命中缓存。
如果访存命中(hit为true),则代码调用pkt->makeResponse()函数将请求数据包转换为响应数据包。然后,调用sendResponse(pkt)函数将响应数据包发送回CPU端口,完成对命中请求的响应。
如果访存未命中(hit为false),则代码执行以下操作:
- 获取访存请求的地址(addr)和块地址(block_addr),以及请求的大小(size)。
- 如果请求的地址与块地址相同且请求大小等于缓存块大小(blockSize),则表示请求跨越了一个完整的缓存块。在这种情况下,代码将数据包直接发送给下一级内存(memPort)。
- 如果请求不满足上述条件,则表示请求跨越了多个缓存行,需要进行大小升级。代码创建一个新的数据包(new_pkt),使用MemCmd::ReadReq命令,并将大小设置为缓存块大小(blockSize)。然后,将原始数据包(pkt)的请求信息复制到新数据包中,并分配新数据包所需的内存空间(allocate)。
- 最后,代码将outstandingPacket指针指向原始数据包(pkt),以便在新数据包被处理之前保留对原始数据包的引用。然后,代码将新数据包发送给下一级内存(memPort)。
——————上述accessTiming(PacketPtr pkt)代码的个人解释,教程中没有——————
在从内存收到响应时,是由于缓存未命中引起的。第一步是将响应数据包插入缓存。
然后,根据是否存在outstandingPacket来进行下一步操作。如果存在outstandingPacket,表示有一个待处理的原始请求数据包需要转发给原始请求者;如果不存在outstandingPacket,表示应将响应数据包直接转发给原始请求者。
如果接收到的响应数据包是一个由于原始请求较小而进行的大小升级数据包,则需要将新数据复制到outstandingPacket数据包中(如果是写操作,则写入缓存),这样是为了让缓存行中的数据保存一直,并将所需的数据返回给原始请求者。完成数据复制后,SimpleCache会删除在未命中处理逻辑中创建的新数据包。
大小升级数据包:由于原始请求的大小较小而进行的额外数据传输,目的是获取整个缓存块的数据,并将其复制到原始请求的数据包中。当缓存未命中时,如果原始请求的大小小于缓存块大小,SimpleCache会创建一个新的数据包(称为"大小升级数据包")来获取整个缓存块的数据。
bool
SimpleCache::handleResponse(PacketPtr pkt)
{assert(blocked);DPRINTF(SimpleCache, "Got response for addr %#x\n", pkt->getAddr());insert(pkt);if (outstandingPacket != nullptr) {accessFunctional(outstandingPacket);outstandingPacket->makeResponse();delete pkt;pkt = outstandingPacket;outstandingPacket = nullptr;} // else, pkt contains the data it needssendResponse(pkt);return true;
}三、Functional cache logic
这部分的修改和第二部分的一样,也是在.cc文件中进行修订。
文件名:simple_cache.cc
需要实现另外两个函数:accessFunctional和insert。这两个函数构成了缓存逻辑的关键部分。
首先,为了在功能上更新缓存,我们首先需要存储缓存内容。最简单的缓存存储方式是一个映射(哈希表),它将地址映射到数据。因此,需要在SimpleCache中添加以下成员变量。
std::unordered_map<Addr, uint8_t*> cacheStore;1、insert()
每当内存侧端口响应一个请求时,insert()函数将被调用。
首先,我们需要检查缓存是否已满。如果缓存的条目数(块数 blocks)超过了SimObject参数设置的缓存容量,那么我们需要进行替换(eviction)。下面的代码通过利用C++ unordered_map 的哈希表实现来随机替换一个条目。
在替换(eviction)时,我们需要将数据写回到后备内存中,以防数据已被更新。为此,我们创建一个新的请求-数据包对。数据包使用了一个新的内存命令:MemCmd::WritebackDirty。然后,我们通过内存侧端口(memPort)发送数据包,并从缓存存储映射中删除该条目。
然后,在可能替换(eviction)了一个块之后,我们将新的地址添加到缓存中。我们只需为该块分配空间,并在映射中添加一个条目。最后,我们将响应数据包中的数据写入新分配的块中。由于我们确保在缓存未命中逻辑中创建的新数据包的大小与缓存块的大小相同,所以这些数据的大小也是缓存块的大小。
void
SimpleCache::insert(PacketPtr pkt)
{if (cacheStore.size() >= capacity) {// Select random thing to evict. This is a little convoluted since we// are using a std::unordered_map. See http://bit.ly/2hrnLP2int bucket, bucket_size;do {bucket = random_mt.random(0, (int)cacheStore.bucket_count() - 1);} while ( (bucket_size = cacheStore.bucket_size(bucket)) == 0 );auto block = std::next(cacheStore.begin(bucket),random_mt.random(0, bucket_size - 1));RequestPtr req = new Request(block->first, blockSize, 0, 0);PacketPtr new_pkt = new Packet(req, MemCmd::WritebackDirty, blockSize);new_pkt->dataDynamic(block->second); // This will be deleted laterDPRINTF(SimpleCache, "Writing packet back %s\n", pkt->print());memPort.sendTimingReq(new_pkt);cacheStore.erase(block->first);}uint8_t *data = new uint8_t[blockSize];cacheStore[pkt->getAddr()] = data;pkt->writeDataToBlock(data, blockSize);
}——————上述insert(PacketPtr pkt)代码的个人解释,教程中没有——————
这段代码是一个简单缓存的插入函数,其作用是将一个数据包(Packet)插入到缓存中。使用随机替换策略来保持缓存大小不超过预定容量。
-
首先,函数检查缓存的大小是否已经达到了容量上限(capacity)。如果达到上限,则需要进行替换(evict)操作以腾出空间来插入新的数据包。
-
替换操作的实现比较复杂,因为这里使用了一个std::unordered_map(cacheStore)作为缓存的存储结构。在unordered_map中,元素是根据键(key)进行存储和检索的,而不是按照插入的顺序。
-
替换的策略是随机选择一个要替换的元素。首先,代码使用一个do-while循环来选择一个非空的桶(bucket)作为候选桶。这里使用了random_mt.random函数来生成一个随机的桶索引,范围是从0到(bucket_count - 1)。如果选择的桶为空,则继续选择直到找到非空的桶。
-
一旦选择了非空的桶,代码使用std::next函数和random_mt.random函数来选择桶中的一个元素。std::next函数用于获取桶的迭代器,random_mt.random函数用于生成一个随机的索引,范围是从0到(bucket_size - 1)。这样就得到了要替换的元素的迭代器(block)。
-
接下来,代码创建一个新的请求(Request)和数据包(Packet),用于将要替换的元素写回到内存中。这里使用了block的键(first)作为请求的地址,并指定了写回(WritebackDirty)的命令和块大小(blockSize)。数据包的数据部分被设置为要替换的元素的值(second)。
-
最后,通过调用cacheStore的erase函数来从缓存中移除要替换的元素。
-
如果缓存还有空间,代码继续执行,为新插入的数据包分配一个新的数据块,并将数据包的地址作为键,数据块的指针作为值,插入到cacheStore中。
-
注意,这里为数据块分配了内存(uint8_t *data = new uint8_t[blockSize]),但在这段代码中没有看到对其进行释放的部分。这可能是因为在其他地方进行了相应的释放操作,或者这部分内存的释放被延迟到了其他地方进行。
——————上述insert(PacketPtr pkt)代码的个人解释,教程中没有——————
四、Creating a config file for the cache
在configs/learning_gem5/part2/文件夹创建最后的运行文件。
文件名:simple_cache.py
实现的最后一步是创建一个使用新缓存类的Python配置脚本(也就是最后的运行文件)。以上一个教程为基础,希望设置该缓存的参数(例如,将缓存大小设置为1KB),并且不再使用命名的端口(data_port and inst_port),而是两次使用cpu_side端口。由于cpu_side是一个VectorPort,它会自动创建多个端口连接。
# import the m5 (gem5) library created when gem5 is built
import m5# import all of the SimObjects
from m5.objects import *# create the system we are going to simulate
system = System()# Set the clock frequency of the system (and all of its children)
system.clk_domain = SrcClockDomain()
system.clk_domain.clock = "1GHz"
system.clk_domain.voltage_domain = VoltageDomain()# Set up the system
system.mem_mode = "timing" # Use timing accesses
system.mem_ranges = [AddrRange("512MB")] # Create an address range# Create a simple CPU
system.cpu = X86TimingSimpleCPU()# Create a memory bus, a coherent crossbar, in this case
system.membus = SystemXBar()# Create a simple cache
system.cache = SimpleCache(size="1kB")# Connect the I and D cache ports of the CPU to the memobj.
# Since cpu_side is a vector port, each time one of these is connected, it will
# create a new instance of the CPUSidePort class
system.cpu.icache_port = system.cache.cpu_side
system.cpu.dcache_port = system.cache.cpu_side# Hook the cache up to the memory bus
system.cache.mem_side = system.membus.cpu_side_ports# create the interrupt controller for the CPU and connect to the membus
system.cpu.createInterruptController()
system.cpu.interrupts[0].pio = system.membus.mem_side_ports
system.cpu.interrupts[0].int_requestor = system.membus.cpu_side_ports
system.cpu.interrupts[0].int_responder = system.membus.mem_side_ports# Create a DDR3 memory controller and connect it to the membus
system.mem_ctrl = MemCtrl()
system.mem_ctrl.dram = DDR3_1600_8x8()
system.mem_ctrl.dram.range = system.mem_ranges[0]
system.mem_ctrl.port = system.membus.mem_side_ports# Connect the system up to the membus
system.system_port = system.membus.cpu_side_ports# Create a process for a simple "Hello World" application
process = Process()
# Set the command
# grab the specific path to the binary
thispath = os.path.dirname(os.path.realpath(__file__))
binpath = os.path.join(thispath, "../../../", "tests/test-progs/hello/bin/x86/linux/hello"
)
# cmd is a list which begins with the executable (like argv)
process.cmd = [binpath]
# Set the cpu to use the process as its workload and create thread contexts
system.cpu.workload = process
system.cpu.createThreads()system.workload = SEWorkload.init_compatible(binpath)# set up the root SimObject and start the simulation
root = Root(full_system=False, system=system)
# instantiate all of the objects we've created above
m5.instantiate()print("Beginning simulation!")
exit_event = m5.simulate()
print("Exiting @ tick %i because %s" % (m5.curTick(), exit_event.getCause()))
——————配置文件的个人解释,教程中没有——————
这段代码是使用gem5模拟器创建和配置一个简单的系统,并运行一个基本的"Hello World"应用程序。
-
首先,导入了gem5模拟器的相关库和SimObjects。
-
创建了一个System对象,这是我们要模拟的系统。
-
设置系统的时钟频率为1GHz,并指定电压域。
-
配置系统的内存模式为"timing",表示使用时序访问。
-
创建一个地址范围为512MB的内存。
-
创建一个简单的CPU(X86TimingSimpleCPU)。
-
创建一个内存总线(membus),这里使用了一个统一的交叉开关(SystemXBar)。
-
创建一个简单的缓存(SimpleCache)。
-
将CPU的指令缓存(icache)和数据缓存(dcache)端口连接到缓存的CPU端口(cpu_side)。
-
将缓存的内存端口(mem_side)连接到内存总线的CPU端口(cpu_side_ports)。
-
创建一个中断控制器,并将其连接到内存总线。
-
创建一个DDR3内存控制器,并将其连接到内存总线。
-
将系统的系统端口(system_port)连接到内存总线的CPU端口。
-
创建一个进程(Process)来运行一个简单的"Hello World"应用程序。
-
设置应用程序的可执行文件路径。
-
将CPU的工作负载(workload)设置为该进程,并创建线程上下文。
-
设置系统的工作负载(workload)为SEWorkload,并初始化为与应用程序兼容的方式。
-
创建一个Root对象,指定系统和全系统模拟为False。
-
实例化上述创建的所有对象。
-
开始模拟器的运行,执行模拟。
-
模拟结束后,打印退出的原因和模拟器运行的Tick数。
——————配置文件的个人解释,教程中没有——————
通过修改缓存大小,可以提高系统性能。
五、Adding statistics to the cache(可选)
如果希望通过其他统计信息(例如缓存的命中率和失效率)来了解系统的整体执行时间,需要向SimpleCache对象添加一些统计信息。
首先,在SimpleCache对象中声明这些统计信息。它们属于Stats命名空间。在这种情况下,创建四个统计信息。命中次数(hits)和失效次数(misses)是简单的标量计数(simple Scalar counts)。我们还将添加一个missLatency,它是一个表示满足缺失所需时间的直方图。最后,添加一个特殊的统计信息,称为Formula,用于计算命中率(hitRatio),它是其他统计信息(命中次数和失效次数)的组合。
class SimpleCache : public MemObject
{private:...Tick missTime; // To track the miss latencyStats::Scalar hits;Stats::Scalar misses;Stats::Histogram missLatency;Stats::Formula hitRatio;public:...void regStats() override;
};接下来,需要定义一个函数来重写regStats函数,以便将统计信息注册到gem5的统计基础设施中。在这里,对于每个统计信息,根据“父级”SimObject的名称和一个描述为其命名。对于直方图统计信息,还需要初始化它,指定直方图中的桶数。最后,对于公式统计信息,只需要在代码中编写公式即可。
void
SimpleCache::regStats()
{// If you don't do this you get errors about uninitialized stats.MemObject::regStats();hits.name(name() + ".hits").desc("Number of hits");misses.name(name() + ".misses").desc("Number of misses");missLatency.name(name() + ".missLatency").desc("Ticks for misses to the cache").init(16) // number of buckets;hitRatio.name(name() + ".hitRatio").desc("The ratio of hits to the total accesses to the cache");hitRatio = hits / (hits + misses);}最后,需要在代码中更新统计信息。在accessTiming类中,可以在命中和失效时分别增加hits和misses。此外,在发生失效时,保存当前时间以便测量延迟。
void
SimpleCache::accessTiming(PacketPtr pkt)
{bool hit = accessFunctional(pkt);if (hit) {hits++; // update statspkt->makeResponse();sendResponse(pkt);} else {misses++; // update statsmissTime = curTick();...接下来,当收到响应时,需要将测量到的延迟添加到直方图中。为此,使用sample函数。该函数将一个数据点添加到直方图中。直方图会自动调整桶的大小以适应接收到的数据。
bool
SimpleCache::handleResponse(PacketPtr pkt)
{insert(pkt);missLatency.sample(curTick() - missTime);...SimpleCache头文件的完整代码可以在此处下载(https://www.gem5.org/_pages/static/scripts/part2/simplecache/simple_cache.hh),而SimpleCache实现的完整代码可以在此处下载(https://www.gem5.org/_pages/static/scripts/part2/simplecache/simple_cache.cc)。
六、测试
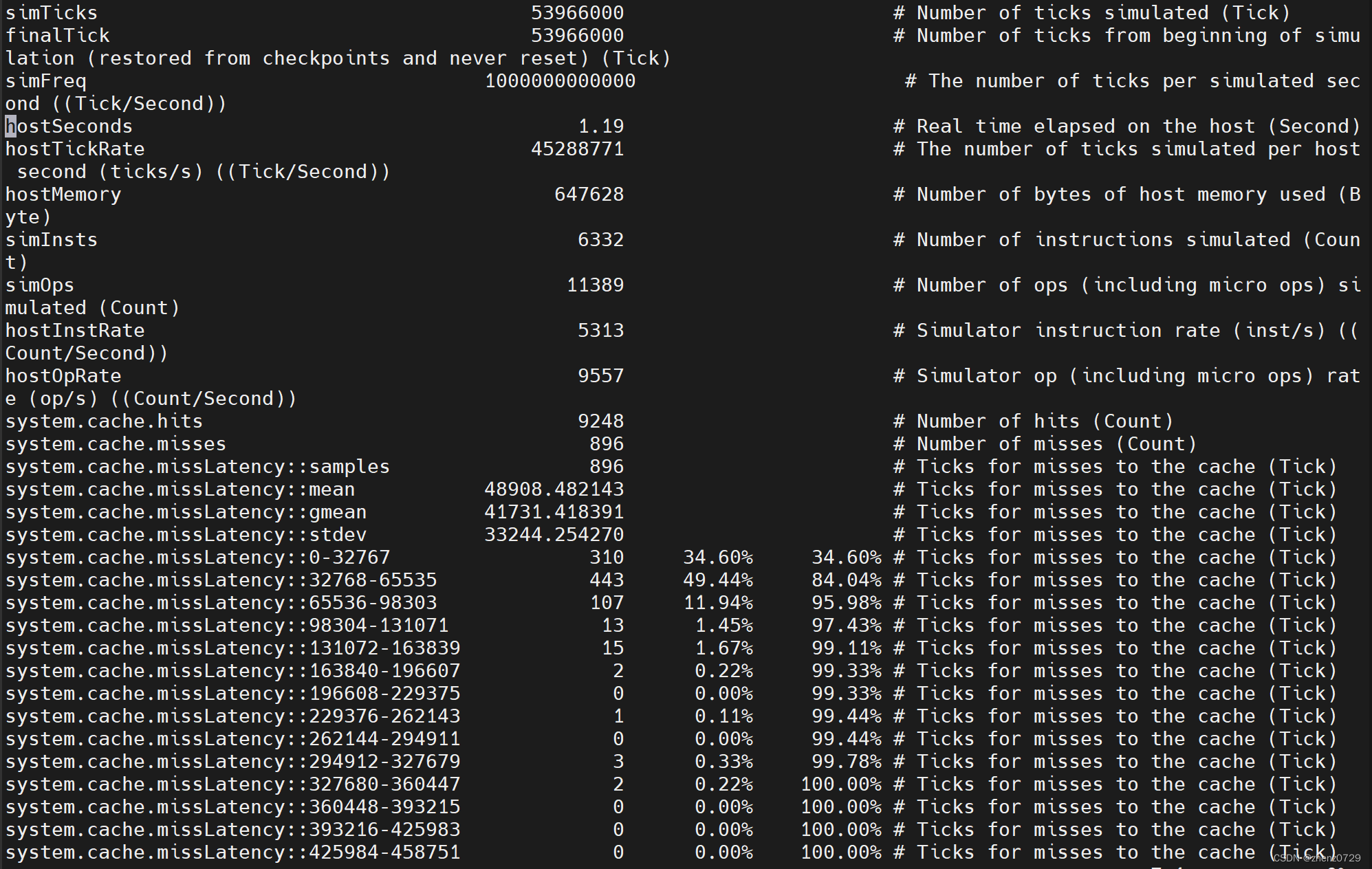
build/X86/gem5.debug --debug-flags=SimpleCache configs/learning_gem5/part2/simple_cache.py1、命令行输出


2、stats.txt