目录
- 一、Motivation
- 二、Solutions
- S1 - StreamReassembler的对外接口
- S2 - push_substring序列写入ByteStream
- 三、Result
- 四、My Code
- 五、Reference
一、Motivation
我们都知道 TCP 是基于字节流的传输方式,即 Receiver 收到的数据应该和 Sender 发送的数据是一样的。这里所说的 “一样” 指的是字节的顺序
比如,Sender 发送字符串 “abc”,在不出意外的情况下,Receiver 应该收到 “abc”,而不是 “acb” 或者 “cab” 之类的乱序字符串。事与愿违,网络环境通常是不太稳定的,经常会发生乱序的情况
我们无力稳定网络中的环境,即无法阻止数据乱序到达的情况;但是,我们可以将这些乱序到达的数据,按照每个字节的 index 将其有序排列,从而实现基于字节流传输的稳定方式。这就是 Lab1: StreamReassembler 的初衷,让我们自己设计一个字节排序器,理顺 Sender 发来的数据
下面我想补充的是一个关于 TCP/IP 架构的常识。为什么会发生乱序的情况呢?因为在 TCP/IP 架构中,数据都是按照分组报文的方式发送给 Receiver 的。还接着上述的例子,Sender 发出的字符串 “abc” 被切分成三个报文,报文 A 中包含了字符 a,报文 B 中包含了字符 b,报文 C 包含了字符 c。Sender 一口气将三个报文全部送上网络。之后,每个报文具体会走什么样的路线到达 Receiver,这完全取决于当时网络环境的拥堵情况和网络节点的路由算法
如果路线不同,那就不可能保证这三个报文按序到达 Receiver。可能出现的情况即是,报文 A(字符 a)先到,报文C(字符 c)其次,报文 B(字符 b)最后才到。Receiver 按照收到报文的顺序呈现出的字符串为 “acb”,这是彻头彻尾的错误(与 Sender 本意的字符串 “abc” 相悖)
二、Solutions
针对这种乱序的情况,我们来实现自己的字节流排序器,先来看一下讲义中的这张流向图,

乍一看是比较抽象的(教这门课的老师的独特审美),但是也能够理清我们 TCP 连接中字节流的几个重要节点
第一个,first unread 节点之前的数据是已经写入 ByteStream 中的,且被用户读取了;随后的 first unread 到 first unassembled 之间的数据是 Receiver 已收到且排好序写入到 ByteStream 中的内容;first unassembled 到 first unacceptable 区间的内容是 Recevier 断断续续收到的字节。可能不是连续的,比如,已经收到了字符串 “bc”,但还没有收到字符 ‘a’,此时构不成有序的 “abc”。只有在收到字符 ‘a’ 之后,才能将 “abc” 写入 ByteStream
ByteStream 讲究的是有序字节序列,即写入 ByteStream 的最后一个字节,它之前的字节都应该是接着前一个的 index 而来的,即字符 ‘c’ 之前就应该是字符 ‘b’,字符 ‘b’ 之前的就应该是字符 ‘a’,缺一个都是不连续的
S1 - StreamReassembler的对外接口
我们先来看看 Lab1: StreamReassembler 已经声明好的接口及注解,
//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,
//! possibly overlapping) into an in-order byte stream.
class StreamReassembler {private:// Your code here -- add private members as necessary.ByteStream _output; //!< The reassembled in-order byte streamsize_t _capacity; //!< The maximum number of bytes/* 自添加的变量 */std::map<size_t, char> buf_;bool eof_flag_;size_t eof_idx_;private:/* 自定义的关键节点 get 方法 */size_t first_unread() const { return _output.bytes_read(); }size_t first_unassembled() const { return _output.bytes_written(); }size_t first_unacceptable() const { return first_unread()+_capacity; }public://! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.//! \note This capacity limits both the bytes that have been reassembled,//! and those that have not yet been reassembled.StreamReassembler(const size_t capacity);//! \brief Receives a substring and writes any newly contiguous bytes into the stream.//!//! If accepting all the data would overflow the `capacity` of this//! `StreamReassembler`, then only the part of the data that fits will be//! accepted. If the substring is only partially accepted, then the `eof`//! will be disregarded.//!//! \param data the string being added//! \param index the index of the first byte in `data`//! \param eof whether or not this segment ends with the end of the streamvoid push_substring(const std::string &data, const uint64_t index, const bool eof);//! \name Access the reassembled byte stream//!@{const ByteStream &stream_out() const { return _output; }ByteStream &stream_out() { return _output; }//!@}//! The number of bytes in the substrings stored but not yet reassembled//!//! \note If the byte at a particular index has been submitted twice, it//! should only be counted once for the purpose of this function.size_t unassembled_bytes() const;//! \brief Is the internal state empty (other than the output stream)?//! \returns `true` if no substrings are waiting to be assembledbool empty() const;
};
不难理解,类的初始化方法是设定 StreamReassember’s ByteStream 容量的,即 _output 的大小,其定义如下,
StreamReassembler::StreamReassembler(const size_t capacity) : _output(capacity), _capacity(capacity), buf_({}), eof_flag_(false), eof_idx_(0) {}
其中的 ByteStream 在 Lab0: networking warmup 中有定义,详情请移步。至于 eof_flag 和 eof_idx_ 会在之后的 push_substring() 中用到
接下来,第一个也是最重要的对外接口是 push_substring(data, index, eof),它会在 Receiver 收到新的字节时被调用。大致的功能是理顺刚收到的(可能会乱序)字节序列,并将其写入到 _output 中,以供上层读取。关于实现这个接口的具体细节我将在之后展开
之后便是上层获取 StreamReassember’s ByteStream 的方法 stream_out()。再强调一次!ByteStream 里面存放的是已有序的字节序列。未被排序的字节是没有资格写入其中的,这个是由 push_substring() 控制的
对外提供的最后两个关于容量的接口就较为简单了,unassembled_bytes() 返回的是已被接收但还未被排序的字节数,定义如下,
size_t StreamReassembler::unassembled_bytes() const { return buf_.size()-_output.bytes_written(); }
empty() 判断 StreamReassember 接收的字节序列是否已全部写入其 ByteStream 中,定义如下,
bool StreamReassembler::empty() const { return buf_.size()==_output.bytes_written(); }
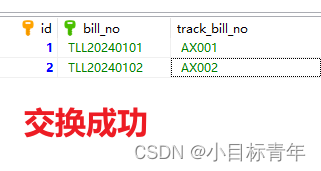
其中,我们自定义的缓冲区 buf_ 的类型是 std::map<size_t, char>,作用是缓存 StreamReassember 接收的字节。利用 std::map 自带排序且去重的特性,根据每个字节的 index 对其进行排序。举个例子来说明,StreamReassember 现接收了三个字节,分别是 < 2, ‘b’ >,< 3, ‘c’ > 和 < 4, ‘d’ >,缓存进 buf_ 后应该是这样的,

假设 buf_ 的容量无穷大,目前已经收到了 3 个字符,我们根据字符的 index 将其归位,最直观的效果如上图左半边所示,和右半边我在程序中采用了 std::map 来实现缓冲排序的功能是一样的效果
我们可以看到目前字符 “bcd” 是连续的,但依然不可以写入 ByteStream;因为在此之前还缺少 index 1 的字符 ‘a’,只有等其到来,才能将字符串 “abcd” 写入 ByteStream
从这个例子中就可以理清 unassembled_bytes() 和 empty() 的逻辑了。前者等于已收到的字节数为 3(已写入 buf_ 的字节) - 0(已写入 ByteStream 的字节数) = 3;后者判断缓冲区是否为空,就看 buf_ 中的字节是否已全部写入 ByteStream 中。很明显,例子中并未全部写入
S2 - push_substring序列写入ByteStream
理清 StreamReassember 的缓冲区 buf_ 的结构之后,我们再来考虑接收到新的字节应该如何处理?无非是先暂存新字节序列并对其进行排序,然后再将有序的部分写入到 ByteStream 中。且看定义,
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {// DUMMY_CODE(data, index, eof);/* 检查若为 eof,则记录下结尾的位置 */if(eof) {eof_flag_ = true;eof_idx_ = index+data.length();}/* 暂存 up2date 的字符串 */for(size_t i=0; i<data.length(); i++) {/* 已写入 ByteStream 的字符不需要进 buf */if(index+i >= first_unassembled()) buf_.emplace(index+i, data[i]);}/* 将已 in-order 的字符串写入 Bytestream 中 */size_t idx = first_unassembled();string res = "";for(auto ite=buf_.begin(); ite!=buf_.end(); ite++) {/* 找到下标 index 的字符 */if(ite->first < idx) continue;/* 已不连续的情况下,无需继续往下寻找可以连接的字符 */if(ite->first>idx || idx>=first_unacceptable())break;if(ite->first==idx && idx<first_unacceptable()) {res.push_back(ite->second);idx++;}}/* 在 ByteStream 容量范围之内,将已 in-order 的字符串写入其中 */if(!res.empty()) _output.write(res); /* 得知已 eof 且所有已 in-order 的字符已写入 ByteStream 中,则关闭之 */if(eof_flag_ && first_unassembled()==eof_idx_) _output.end_input();
}
当然,在流程的开始环节就需要判断 Receiver 这次接收到的字节是否是 Sender 发来的最后一个报文(有 eof 标志)
如果是最后一个报文,则需要提前做好结束标记。为什么要提前做好结束标记呢?是因为 TCP/IP 网络采用分组报文的方式发送数据,也就是说传输过程中并不能保证到达的先后顺序,Sender 发送的包含 eof 的结束报文可能因为路由选择反而第一个到达 Receiver,真正有数据的报文在之后才送达。这种情况在 TCP/IP 网络中应该是很常见的
在判断过 eof 之后,我们先一股脑地将收到的字节缓存到 buf_ 中,这里我做了一个小优化,即加上 if 判断,无视那些已经写入 ByteStream 中的字节,不将其写入 buf_ 中
下面就进入核心环节,即检出 buf_ 中已有序的字节序列。请注意,我这里说的已有序还有一个附加条件,即是从 buf_ 中的第一个字节开始就已经有序!!!
如果遍历到一个字符,它与前一个不成连续关系(index 是否加 1),那么我们就能够认定此时已经不连续了。可以跳出检出环节,将有序序列写入 ByteStream 中
最后,需要判断一下含有 eof 的字符是否已经被写入 ByteStream。如果 eof 字符都已经写入 ByteStream 了,那么就意味着在它之前的所有字符也都已经写入 ByteStream。此时,我们就可以关闭 ByteStream 了,告诉它 Sender 不会再发来数据了
三、Result
CS144 Lab 是一环套一环的结构,也就是说 Lab1: StreamReassembler 是基于 Lab0 networking warmup code 的,所以,我们在开始之前还需要透过 git fetch 和 git merge 拉取合并最新的代码,
$ git fetch
$ git merge origin/lab1-startercode
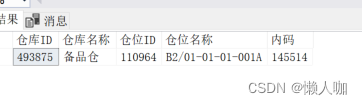
以上命令在 Lab1: StreamReassembler 的根目录中下发即可。编写好 code 之后,进入 bulid 目录先透过 make 命令进行编译,随后再下发 make check_lab1 检查是否通过了每个测试点,
$ make check_lab1
[100%] Testing the stream reassembler...
Test project /home/jeffrey/Documents/lab1-stitching-substrings-into-a-byte-stream/buildStart 15: t_strm_reassem_single1/16 Test #15: t_strm_reassem_single ............ Passed 0.01 secStart 16: t_strm_reassem_seq2/16 Test #16: t_strm_reassem_seq ............... Passed 0.01 secStart 17: t_strm_reassem_dup3/16 Test #17: t_strm_reassem_dup ............... Passed 0.01 secStart 18: t_strm_reassem_holes4/16 Test #18: t_strm_reassem_holes ............. Passed 0.00 secStart 19: t_strm_reassem_many5/16 Test #19: t_strm_reassem_many .............. Passed 1.77 secStart 20: t_strm_reassem_overlapping6/16 Test #20: t_strm_reassem_overlapping ....... Passed 0.00 secStart 21: t_strm_reassem_win7/16 Test #21: t_strm_reassem_win ............... Passed 2.13 secStart 22: t_byte_stream_construction8/16 Test #22: t_byte_stream_construction ....... Passed 0.01 secStart 23: t_byte_stream_one_write9/16 Test #23: t_byte_stream_one_write .......... Passed 0.01 secStart 24: t_byte_stream_two_writes
10/16 Test #24: t_byte_stream_two_writes ......... Passed 0.00 secStart 25: t_byte_stream_capacity
11/16 Test #25: t_byte_stream_capacity ........... Passed 0.00 secStart 26: t_byte_stream_many_writes
12/16 Test #26: t_byte_stream_many_writes ........ Passed 0.01 secStart 27: t_webget
13/16 Test #27: t_webget ......................... Passed 0.46 secStart 47: t_address_dt
14/16 Test #47: t_address_dt ..................... Passed 0.01 secStart 48: t_parser_dt
15/16 Test #48: t_parser_dt ...................... Passed 0.00 secStart 49: t_socket_dt
16/16 Test #49: t_socket_dt ...................... Passed 0.01 sec100% tests passed, 0 tests failed out of 16Total Test time (real) = 4.46 sec
[100%] Built target check_lab1
四、My Code
-
CS144 Labs code 总入口
-
CS144 Lab1 入口
五、Reference
- CSDN - CS144 lab1