【深度学习:Domain Adversarial Neural Networks】领域对抗神经网络简介
- 前言
- 领域对抗神经网络
- DANN 模型架构
- DANN 训练流程
- DANN示例
- GPT示例
前言
领域适应(DA)指的是当不同数据集的输入分布发生变化(这种变化通常被称为共变量变化或数据变化)时,加强模型训练的一种过程。图 1 展示了一些简单的例子:(a) 显示了一个变量的均值发生了较大偏移;(b) 显示了一个变量的均值发生了较小偏移;© 显示了一个变量的均值发生了较小偏移,而方差发生了较大偏移。

发展议程有两个相互竞争的目标:
- 判别能力 --在特定领域内对来自不同类别的数据进行判别的能力
- 领域不变性 - 衡量跨领域数据类别之间相似性的能力
例如,在一个分类模型中,我们期望模型能够区分不同类别之间的差异——因此需要保持其判别能力。与此同时,如果数据发生变化,我们希望提高分类器的领域不变性,使其在接受来自不同领域的输入时表现良好。(关于严谨的理论处理,我们推荐 Ben-David 等人撰写的 “A theory of learning from different domains”)。
领域自适应的一个使用案例涉及 MNIST 数据集,该数据集由手写数字图像组成。该数据集在文献中无处不在,经常被用作测试模型的基准。还有一个名为 MNIST-M 的数据集,其中添加了不同的背景和数字颜色,如图 2 所示。

虽然这两个数据集有明显的相似性,但MNIST-M数据集的变化使得输入特征的分布与原始MNIST数据集不同。在这种情况下,即使没有来自 MNIST-M 的标签,也可以使用 DA 来帮助模型在 MNIST 和 MNIST-M 上都表现良好。Ganin 和 Lempitsky 的 "反向传播的无监督领域适应 "一文中描述了这种用例。
另一个有用的 DA 例子是处理生物信号(尤其是神经信号)如何随时间或对象而变化的问题。假设我们想开发一款脑机接口应用,需要对人类受试者移动特定手臂或腿部以控制外部假肢装置的想法进行分类。利用源受试者的脑电信号(图 3),我们通常会开发出一个分类器。但是,将该分类器应用于我们的 "目标对象 "可能会导致性能不佳。领域适配可以让我们在目标受试者身上获得更高的性能,而无需从每个受试者身上收集数据。

实现 DA 最常见的方法之一称为样本重新加权。使用这种方法时,我们通过以下步骤开发域分类器:
- 将所有源域样本标记为“0”,将所有目标域样本标记为“1”。 训练一个可以返回预测概率
- pi(例如逻辑回归或随机森林)的二元分类器,以区分源数据和目标数据。
- 当在源域上进行模型拟合时,使用所得概率来获取源域样本的样本权重,使用:

这会导致看起来最像目标样本的源样本获得更高的权重。虽然我们普遍认为这种方法是积极的,但它也有一些缺点。挑战之一是确定驱动域分类器的准确度。如果太准确,则没有用,因为目标区域和域区域之间不会重叠。
领域对抗神经网络
如果我们有办法同时使用 DA 和学习标签分类怎么办?具有此功能的一种方法是域对抗神经网络(DANN)。它使用具有类标签的源数据和未标记的目标数据。目标是在对抗性训练过程中使用源数据和目标数据来预测目标数据。
在传统的机器学习中,我们通常假设训练数据和测试数据具有相同的分布。但在实际应用中,这种假设往往不成立。例如,一个在晴天条件下训练的图像识别模型,在雨天条件下可能表现不佳。DANN 正是为了解决这种源域和目标域数据分布不一致的问题。
DANN 的核心思想是通过引入一个额外的域分类器(Domain Classifier),使得模型在学习特征表示时同时减少源域和目标域间的分布差异。这个过程可以看作是一种对抗性训练:主网络试图学习对任务有用且域不可分的特征,而域分类器则试图区分这些特征来自哪个域。
DANN 模型架构
DANN 通常包含三个主要部分:
- 标签预测器(蓝色)(Feature Extractor): 从输入数据中提取有用的特征。
- 域分类器(粉色)(Task Classifier): 基于特征提取器提取的特征,进行主任务(如图像分类、语音识别等)的学习。
- 特征提取器(绿色)(Domain Classifier): 尝试区分特征是来自源域还是目标域。征提取器的目标是学习对两个域都有用的特征,而域分类器则努力区分这些特征的来源。这种设置创建了一种对抗关系,促使特征提取器生成越来越难以区分域的特征。

DANN 训练流程
DANN训练流程如图4所示:
- 来自源或目标的输入特征被馈送到特征提取器。
- 生成的特征被馈送到:
- 如果输入来自源域,则标记预测器或域分类器(因为只有该数据具有标签)。
- 域分类器,如果输入来自目标域(因为该数据上没有标签)。
- 标签预测器和域分类器经过优化,可使用类熵等损失函数来最小化与其各自分类问题相关的误差。
- 针对特定于 DANN 的特征提取器执行“特殊”优化(如下所述)。
优化特征提取器可以被看作是在生成对域分类不敏感的特征与对标签预测有用的特征之间寻找最佳平衡点。特征提取器的参数经过优化,以最小化标签预测器的损失并最大化域分类器的损失(涉及梯度反转层的使用)。
在生产中,我们将来自目标域的输入提供给特征提取器,特征提取器创建输入到标签预测器的特征以进行标签预测。没有使用域分类器,因此我们在部署模型时可以忽略图4中的粉色部分。
在训练过程中,DANN 采用了一种类似于 GAN(生成对抗网络)的策略。特征提取器和任务分类器被训练以最大化主任务的性能,而域分类器则被训练以区分不同域的特征。通过这种方式,模型能够学习到既对任务有用又对域具有泛化能力的特征。
DANN示例
让我们看几个例子。第一个示例如图 5 所示,其中包含由 scikit-learn Python 包中的 make_blobs 函数生成的合成数据。左边的数据是源数据,右边的数据是目标数据。 0 级为红色,1 级为绿色。
观察数据如何在源域和目标域之间转移。在每个域内,类可以线性分离,但这种转变使该模型的泛化变得非常复杂。

请注意,我们仅使用源域中的标签进行训练,并且仅使用目标域中的标签来计算性能指标。由于训练过程中未使用目标域标签,因此它们在图 6 中呈灰色显示。

传统的神经网络在源域上进行训练,然后在目标域上进行测试,其准确率达到 55%。但是,如果我们包含域分类器并使用 DANN 训练过程,则最终的目标域准确率将高达 95%,这证明了 DANN 过程的价值。
一个更真实的例子来自研究生院的自然语言处理 (NLP) 课程项目。其目标是确定来自 Android 论坛的问题对是否相似。不过,带有标记对的训练数据均来自 AskUbuntu 论坛。这个问题非常适合 DANN 架构和训练过程。
当不使用 DANN 训练过程时(即仅使用 AskUbuntu 论坛数据进行训练,然后在 Android 数据上测试模型),曲线下面积 (AUC) 为 0.61。当使用DANN框架及其训练过程时(训练中使用AskUbuntu数据输入和标签以及Android数据输入;不使用Android标签),AUC增加到0.69。当 Android 论坛数据中的少量标签被添加到 DANN 训练过程中时,AUC 增加到 0.76,这是一个很大的改进。
在现实世界中,我们可能没有用于计算指标的目标域的标签。由于我们不想在不计算样本外性能指标的情况下将模型投入生产,因此可以手动标记目标域中的少量数据以用于评估。
我们相信这样的方法可以集成到 ImageNet 或 ULMFiT 等训练模型中,这些模型经常用作预训练模型。使用DANN训练过程可能会生成更多具有领域不变性的模型,从而更好地适应特定的应用程序。
最近,DANN 架构的改进已经发布,我们建议感兴趣的读者探索生成对抗网络 (GAN) 的新发展。尽管如此,即使在最新的工作中,这里描述的对抗性训练过程仍然是 DA 的关键组成部分。
GPT示例
假设我们有一个图像识别任务,源域是室内照片,目标域是室外照片。在这种情况下,DANN 会试图学习在这两个域都有效的特征表示,同时减少由于场景差异(如光照、背景等)引起的性能下降。
为了更好地理解这个概念,我们可以生成一张示意图,展示 DANN 在处理室内和室外图像时的特征提取和分类过程。
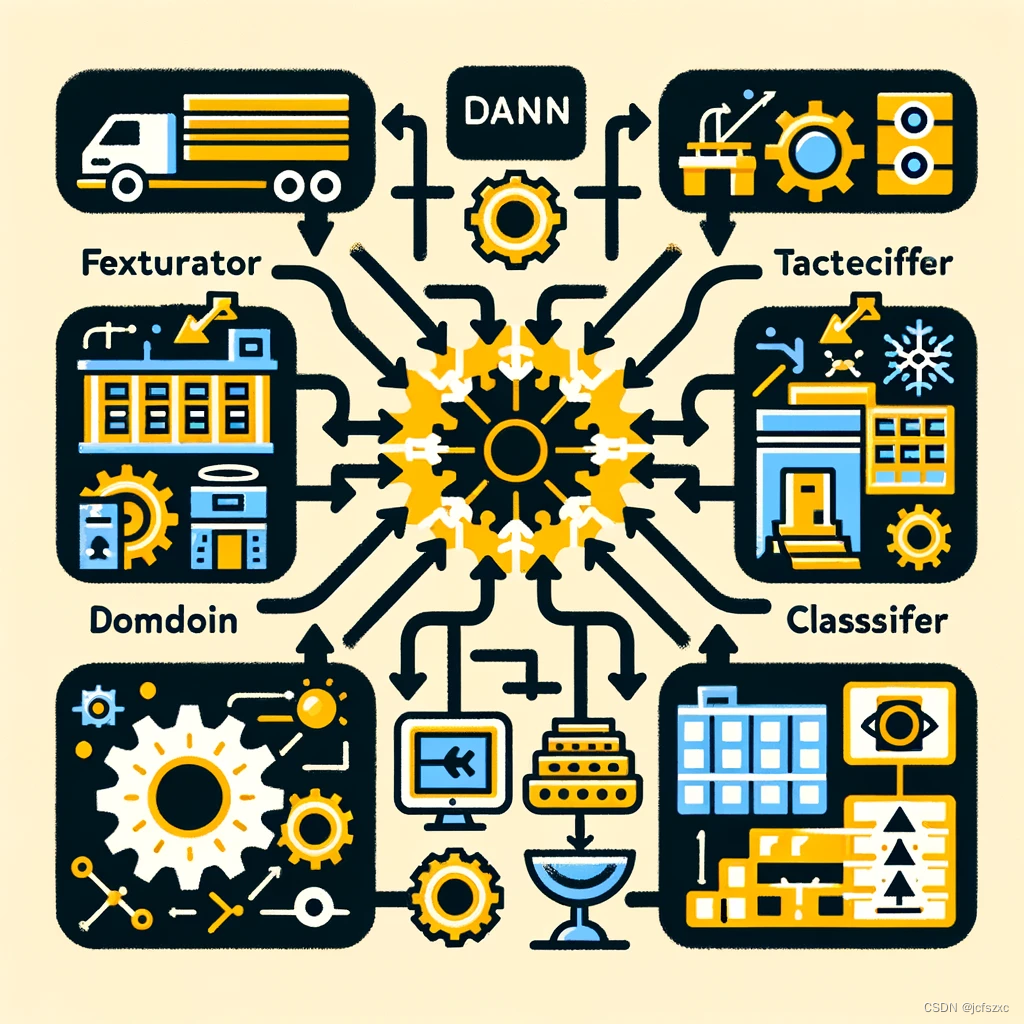
这张图展示了Domain Adversarial Neural Network(DANN)在图像识别任务中的工作原理。您可以看到,图中描绘了两种不同的域:室内和室外场景。特征提取器位于中心,从室内和室外图像中提取特征。这些特征随后被分为两个不同的分类器:任务分类器和域分类器。任务分类器专注于识别图像中的对象,而域分类器则试图区分图像是属于室内还是室外场景。这种结构有助于模型在不同的环境中都能有效地识别和分类图像。


![[C#]使用纯opencvsharp部署yolov8-onnx图像分类模型](https://img-blog.csdnimg.cn/direct/59cc41476aee453b8193aad6247e2fc7.jpeg)



![[Flutter]WebPlatform上运行遇到的问题总结](https://img-blog.csdnimg.cn/direct/16c604b5d4d34f0aa6d1e0fc3cab99fe.png)




