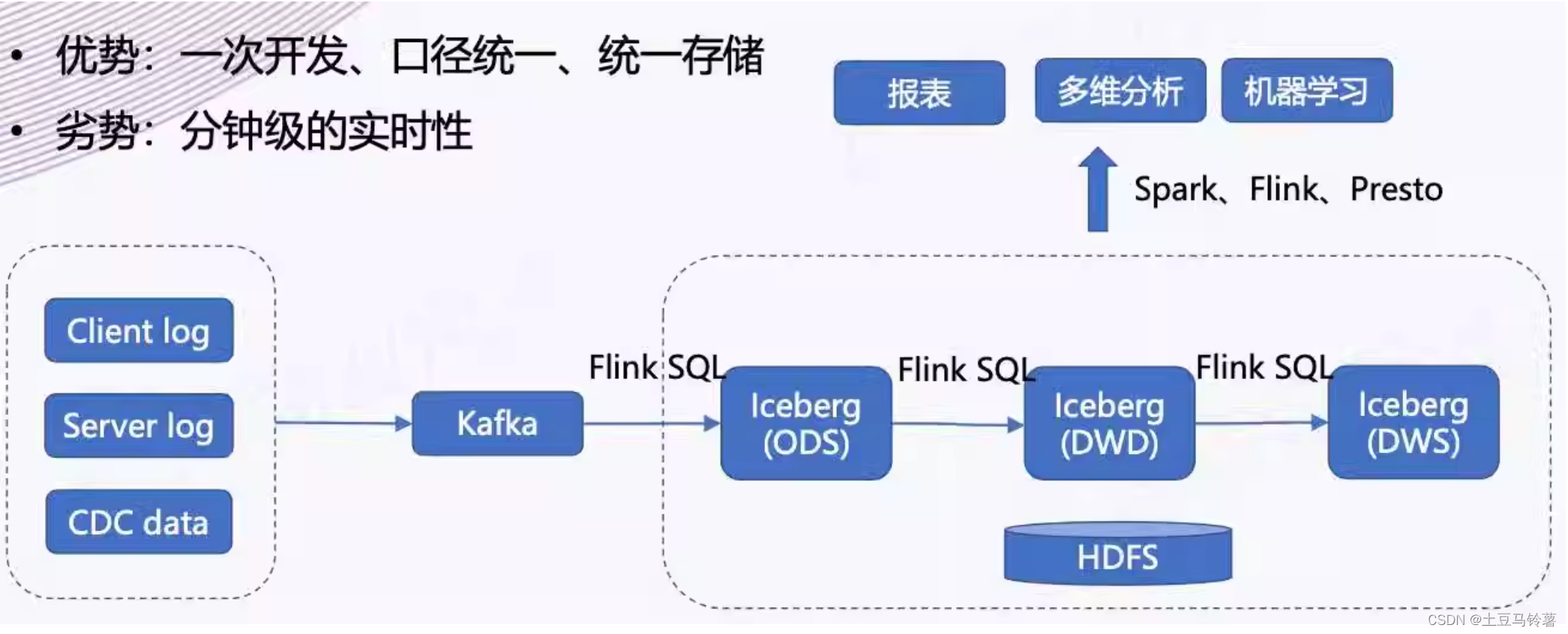
1 介绍
FineBI 是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品。
FineBI 是定位于自助大数据分析的 BI 工具,能够帮助企业的业务人员和数据分析师,开展以问题导向的探索式分析。
2 现阶段数据分析弊端
现阶段各行各业在使用数据进行查询分析基本都是通过前端业务人员与信息部 IT 人员沟通,向他们解释具体的业务流程,然后 IT 人员再根据业务流程来获取数据建立模板这样一个流程来完成的。
随着信息化的长期发展,这样一个使用流程的弊端越来越明显,具体表现在以下几个方面:
问题详细说明
- 数据结构混乱。 数据库经过多年建设,数据非常庞大复杂,IT 人员几乎不太可能弄清楚所有数据表的结构。
- 沟通成本大。 前端业务人员需要与信息部 IT 人员沟通,向他们解释具体的业务流程,然后IT人员再根据业务流程来获取数据建立模板,这中间的沟通会反复好几次才能达到前端业务人员想要的效果。
- 响应时间慢。 大部分的查询分析都需要IT人员建立,工作量大,前端人员等待的时间长,不能及时响应。
- 灵活性差。 查询需求多样化,每个查询分析模板均是固定不可变更,不能满足一个模板的重复使用。现阶段各行各业在使用数据进行查询分析基本都是通过前端业务人员与信息部 IT 人员沟通,向他们解释具体的业务流程,然后 IT 人员再根据业务流程来获取数据建立模板这样一个流程来完成的。
随着信息化的长期发展,这样一个使用流程的弊端越来越明显,具体表现在以下几个方面:
| 问题 | 详细说明 |
| 数据结构混乱。 | 数据库经过多年建设,数据非常庞大复杂,IT 人员几乎不太可能弄清楚所有数据表的结构。 |
| 沟通成本大。 | 前端业务人员需要与信息部 IT 人员沟通,向他们解释具体的业务流程,然后IT人员再根据业务流程来获取数据建立模板,这中间的沟通会反复好几次才能达到前端业务人员想要的效果。 |
| 响应时间慢。 | 大部分的查询分析都需要IT人员建立,工作量大,前端人员等待的时间长,不能及时响应。 |
| 灵活性差。 | 查询需求多样化,每个查询分析模板均是固定不可变更,不能满足一个模板的重复使用。 |
3 FineBI 优势
(1)FineBI 通过多人协同合作来解决上述弊端。

(2)FineBI 的定位是业务人员/数据分析师自主制作仪表板,进行探索分析。
因此在引擎部分将传统的关系型数据库非关系型化,这样用户在选择字段的时候才可以做到像在一张表里使用的效果。重点是自主分析、传统数据库非关系型化。
4 FineBI 功能简介
(1)FineBI 使用 Spider 引擎,可同时实现「实时数据」与「抽取数据」。可以根据数据量、实时性要求、使用频次等,自由选择。实时数据与抽取数据方式的无缝切换,将更加灵活高效支撑前端的高性能分析。
| 小数据量 | 数据以二进制文件形式存放在本地磁盘,随存随用,并行计算,轻量易用。 |
| 大数据量 | 基于 Apache SPARK 计算引擎,结合自研高性能算法,列式存储、并行内存计算、计算本地化加上高性能算法,解决大数据量分析问题与在 FineBI 中快速展示的问题。 |
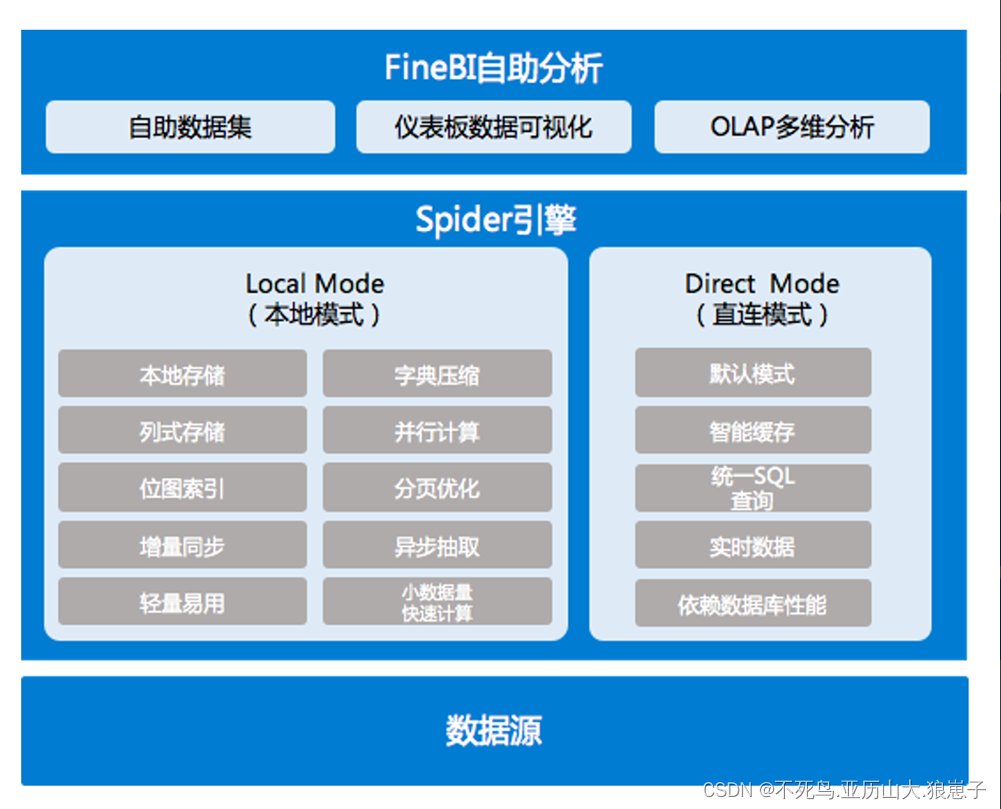
(2)角色匹配
使用 FineBI 的方式取决于用户在项目中的角色与所在的团队。
| IT人员 | 可以利用 FineBI 管理数据,做基础处理工作,提供给业务相关的团队同事。 |
| 数据分析师 | 使用 FineBI 加工数据、创建仪表板,并将这些仪表板分享出来,共享给公司的同事。使用服务的同事可以在 PC 端或者手机应用中查看监控数据,并深入挖掘潜在的数据内容。 |
| 开发人员 | 可以利用 FineBI 的开放 API 或云打包等服务将仪表板或报表集成到自定义应用程序中。 |
(3)功能模块
FineBI 功能模块根据业务分析流程可以分为数据准备、数据加工、可视化分析、仪表板驾驶舱、分享仪表板这些模块,帮助文档也按照这些模块进行介绍。

5 FineBI 软件环境
FineBI使用的软件环境如下:
| 操作系统 | Windows、Linux、Mac、Unix 、Aix、IRIX 等支持 1.8 版本 JDK 的操作系统,详细版本参见 系统要求 。 |
| 数据库 | Apache Kylin、Derby、HP Vertica、IBM DB2、Informix、Sql Server、MySQL、Oracle、Pivotal Greenplum Database、Postgresql、ADS、Amazon Redshift、Apache Impala、Apache Phoenix、Gbase 8A、Gbase8S、Gbase 8T、Hadoop Hive、Kingbase、Presto、SAP HANA、SAP Sybase、Spark、Transwarp Inceptor、HBase 等主流的一些关系型数据库及非关系数据库 MongoDB 等。详情参见:数据连接支持范围 。 |
| 应用服务器 | Tomcat、Jboss、Weblogic、Websphere 等 Web 应用服务器。 |
| 浏览器 | 单核心:谷歌、火狐、支持 IE9 及其以上(包括 Edge,IE8 仅支持查看)、Safari、opera。 从渲染引擎的匹配度上,建议使用:谷歌、火狐。 双核心:360 浏览器、搜狗浏览器、QQ 浏览器、UC 浏览器、猎豹浏览器、百度浏览器,只支持其极速模式,不支持兼容模式。 |
注1:IE10 及以下的版本不支持模板全屏查看,若需全屏查看模板,建议使用 IE10 以上的版本或其他浏览器。
注2:IE11 以下版本若开启 全局水印 可能会影响部分操作,如仪表板无法添加组件。若需开启 全局水印 ,建议使用 IE11 及以上版本的浏览器或更换其他浏览器。
6 FineBI 硬件环境
业务系统运行硬件配置预估与要求,以极限情况推算。
6.1 所有的数据都需要更新,即抽取数据保存到本地
(1)当最大单表数据量在亿级以下,可以直接使用 Web 服务器的本地磁盘作为数据存储介质。推荐配置如下表所示:
| 数据量 | CPU | 可用内存 | 可用磁盘空间 | 编辑用户并发 | 预览用户并发 |
| 0~500万 | 8核~16核,2.5GHz及以上 | 32G | 300G | 20 | 150 |
| 500万~1千万 | 16核~32核,2.5GHz及以上 | 32G | 1T | 30 | 300 |
| 1千万~1亿 | 16核~32核,2.5GHz及以上 | 64G | 2T | 40 | 300 |
(2)可用磁盘空间为推荐空间,最低空间为该推荐空间的三分之一即可。
(3)编辑用户并发指的是同时使用 FineBI 编辑仪表板、创建表、自助数据集的用户个数;预览用户并发指的是同时使用 FineBI 查看数据/仪表板的用户个数。
6.2 所有数据都是实时数据
(1)性能与计算全部依赖于数据库,即都使用实时数据,存在缓存机制以及部分场景内存计算,因此 Web 服务器配置可由结果集数据量来进行估算。(用户的数据库服务器的配置这里不做推荐)其中,结果集数据量表示的是查询数据返回的行*列数。
| 结果集数据量 | CPU | 可用内存 | 编辑用户并发 | 预览用户并发 |
| 0~500万 | 8核,2.5GHz及以上 | 12G | 20 | 150 |
| 500万~1千万 | 8核,2.5GHz及以上 | 32G | 30 | 200 |
| 500万~1千万 | 16核,2.5GHz及以上 | 32G | 40 | 300 |
| 1千万~5千万 | 16核,2.5GHz及以上 | 64G | 40 | 300 |
(2)大量计算是数据库完成,BI 内存消耗量主要和结果集大小、并发性能相关。
6.3 既有实时数据,又有抽取数据
对于既有实时数据,又有需抽取数据的混合情况下,以最高配置要求即可。
注1:服务器台数均以单台来计的,是否多台取决于并发量。若上述单台的并发量不满足要求,可选择扩充 Web 服务器的台数。
注2:FineBI 的 Web 服务器不应安装在同时运行资源密集型应用程序(例如数据库或应用程序服务器)的物理计算机或 VM 虚拟机上。上述CPU 的推荐中,需要保证 FineBI 实际可以占用的资源达到 80% 。