论文标题:LLaMA: Open and Efficient Foundation Language Models
论文链接:https://arxiv.org/pdf/2302.13971.pdf
论文来源:Meta AI
1 概述
大型语言模型(Large Languages Models,LLMs)通过大规模文本数据的训练,展示了其根据文本指令或少量样本完成新任务的能力。这种少数示例的性质首次在规模足够大的模型中出现,导致了一系列聚焦于进一步扩大这些模型的工作。这些努力都是基于一个假设:模型参数越多,性能越好。然而,Hoffmann等人(2022)的近期研究显示,在给定的计算预算下,最佳的性能并非由最大的模型实现,而是由训练数据更多的较小模型实现。
Hoffmann等人(2022)的目标是确定如何最好地根据特定的训练计算预算来调整数据集和模型大小。然而,这个目标忽略了推理预算,这在大规模使用语言模型时变得至关重要。在这种背景下,目标性能水平下的首选模型并不是训练速度最快的,而是推理速度最快的,尽管训练大模型以达到一定的性能水平可能更加容易,但更长时间训练的小模型最终在推理时成本会更低。例如,尽管Hoffmann等人(2022)推荐在200B个token上训练一个10B的模型,我们发现7B模型的性能即使在1T个token之后仍在提高。
本文研究的主要目标是通过使用比通常更多的数据来训练一系列在各种推理预算下达到最佳可能性能的语言模型。这一系列模型称为LLaMA,参数范围从7B到65B,与现有最佳LLMs的性能相媲美。例如,LLaMA-13B在大多数基准测试中都优于GPT-3,尽管其大小只有GPT-3的十分之一。作者们认为这个模型将有助于民主化访问和研究LLMs,因为它可以在单个GPU上运行。对于最大规模的模型,LLaMA的65B参数模型也可以与最佳的LLMs(如Chinchilla或PaLM-540B)相媲美。
不同于Chinchilla、PaLM或GPT-3,LLaMA只使用公开可用的数据,使他们的工作与开源兼容,而大多数现有的模型依赖于非公开或未记录的数据(例如“Books – 2TB”或“Social media conversations”)。存在一些例外,如OPT、GPT-NeoX、BLOOM和GLM,但没有一个能与PaLM-62B或Chinchilla竞争。
2 方法
LLaMA使用完全开源的数据进行预训练,并且融合了已有LLMs的一些训练技巧,同时为了高效运算也对模型架构和运算过程做了一些改动。
2.1 预训练数据
LLaMA的预训练数据来自各个开源语料,数据组成如下:
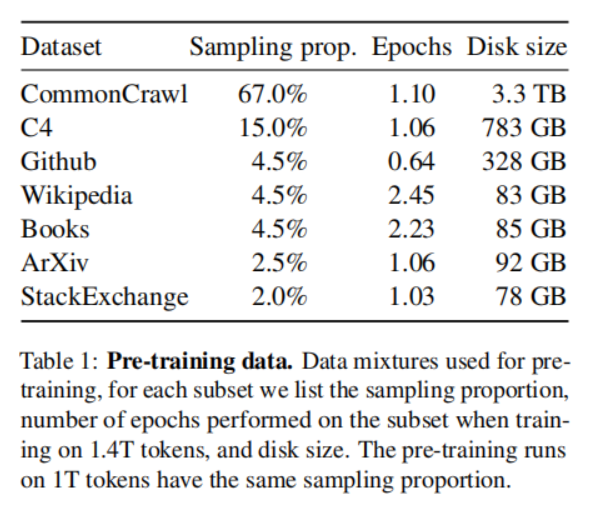
这些数据中既包括网络语料也包括一些代码、书籍等开源数据,这既使得模型能够具备一些多领域的知识和代码理解能力,也可能使得模型会生成一些偏见、毒性和错误信息等有害内容。
LLaMA使用BPE(byte-pair encoding)算法来对数据进行token化,并且将所有的数字分割成单独的数字,并在无法识别的UTF-8字符时回退到byte级别进行分解。这样的处理方式能够帮助模型更好地理解和处理各种类型的字符和数字。最终从这些数据中得到了1.4T个token,对于大多数数据,每个token在训练时只使用一次,除了Wikipedia和Books这两部分执行大约2个epoch。
2.2 架构
LLaMA整合了一些已有的研究来对Transformer架构进行改进,主要包括:
① 「Pre-normalization[GPT3]」 :为了提高训练稳定性,LLaMA归一化了每个Transformer子层的输入,而不是归一化输出。他们使用RMSNorm归一化函数。
② 「SwiGLU激活函数 [PaLM]」 :他们将ReLU非线性函数替换为SwiGLU激活函数。他们使用的维度是,而不是PaLM中的
。
③ 「Rotary Embeddings[GPTNeo] :他们移除了绝对位置嵌入,而是在网络的每一层添加Rotary Embeddings(RoPE)。
以上的改进均有助于提升模型的性能和训练稳定性。所有模型的超参数细节如下:

2.3 优化器
LLaMA使用的是AdamW优化器,设置的超参数为:。并且使用了余弦学习率调度,使得最终学习率等于最大学习率的10%。他们设置的权重衰减为0.1,梯度裁剪为1.0。同时使用2000步的warm-up,并根据模型的大小改变学习率和批处理大小(具体细节见上表)。
2.4 代码层面的高效实现
首先,LLaMA使用了一种高效的因果多头注意力运算符的实现(causal multi-head attention operator),这受到一些已有研究的启发。这种实现方式,可以在xformers库中找到,它降低了内存使用和计算量。这是通过不存储注意力权重和不计算因语言模型任务的因果性而被mask的key/query得分来实现的。
为了进一步提高训练效率,LLaMA通过检查点技术减少了在反向传播过程中需要重新计算的激活量。更具体地说,他们保存了那些计算成本较高的激活,例如线性层的输出。这是通过手动实现transformer层的反向函数来实现的,而不是依赖于PyTorch的自动梯度计算。为了充分利用这种优化,他们需要通过使用模型和序列并行化来减少模型的内存使用。此外,他们还尽可能地重叠了激活的计算和GPU之间网络的通信(使用all_reduce操作)。
在训练LLaMA的65B参数的模型时,本文的代码在拥有80GB RAM的2048个A100 GPU上,每秒每个GPU可以处理大约380个tokens。这意味着在他们包含1.4T tokens的数据集上训练需要大约21天。
3 实验
3.1 主要实验结果
本文在20个不同的benchmark数据集上进行了Zero-shot和Few-shot的实验来验证模型性能,主要结果如下:
- Common Sense Reasoning
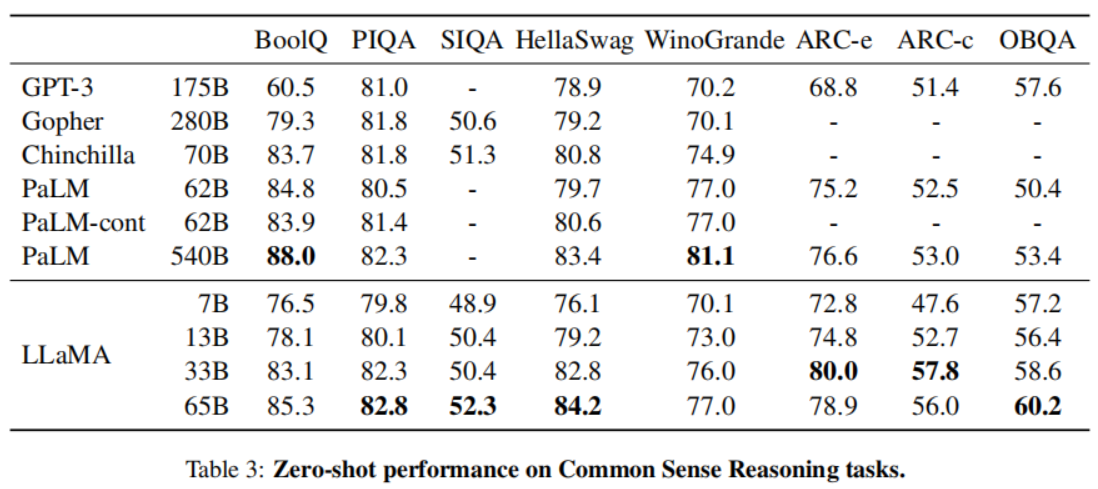
- Closed-book Question Answering


- Reading Comprehension

- Mathematical reasoning

- Code generation

- Massive Multitask Language Understanding
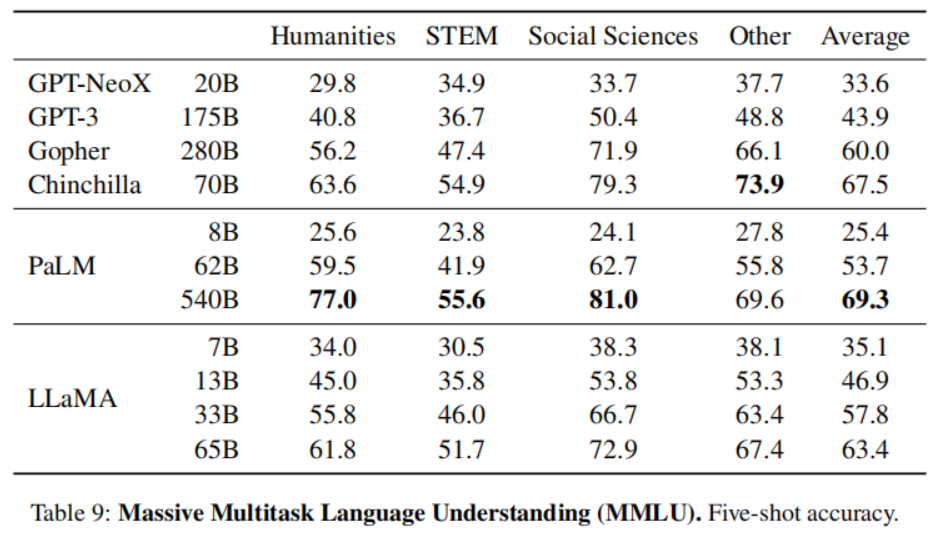
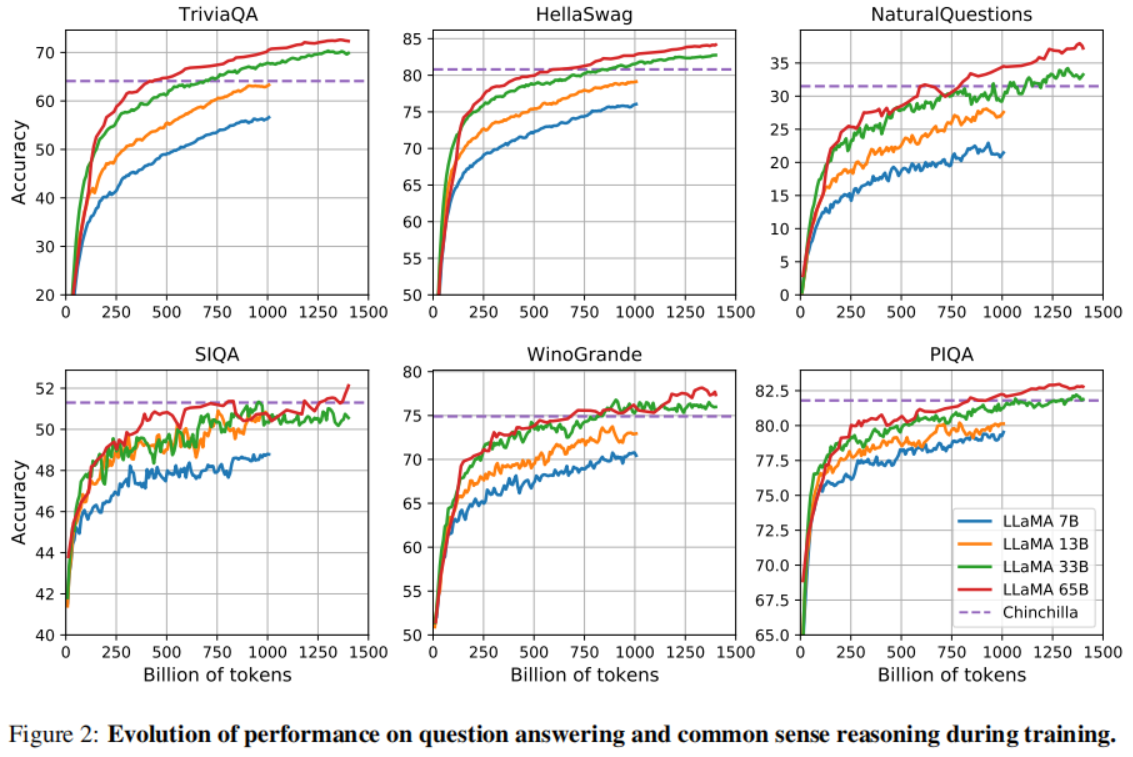
- Evolution of performance during training

3.2 指令微调

3.3 偏见、毒性和错误信息
- RealToxicityPrompts

- CrowS-Pairs
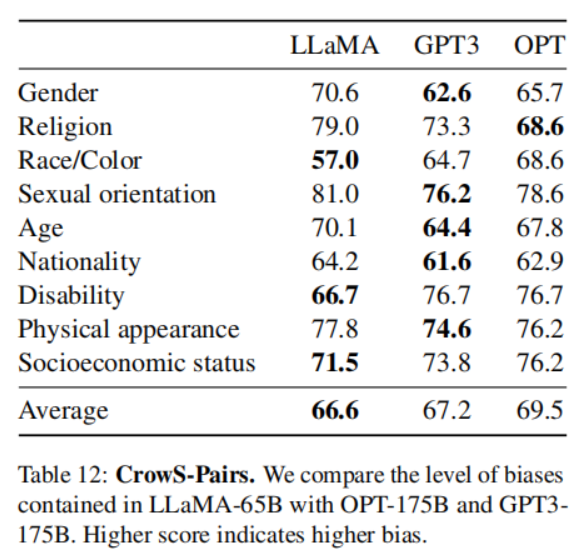
- WinoGender

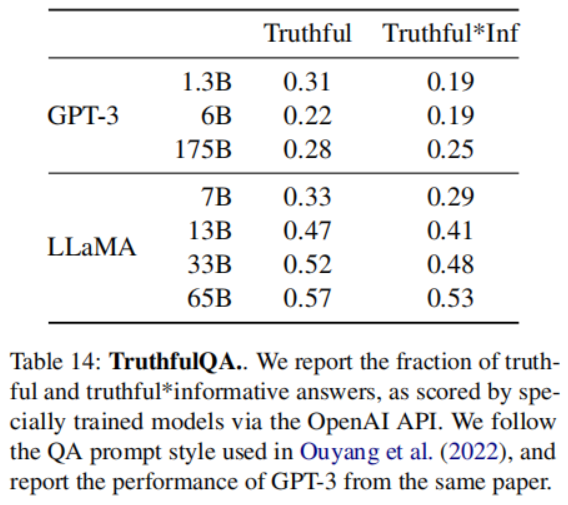
- TruthfulQA
4 基于 LLaMA finetune 的模型
以下这些项目都可以算是 Meta 发布的 LLaMA(驼马)模型的子子孙孙。
4.1 Alpaca
Alpaca是斯坦福在 LLaMA 上对 52000 条指令跟随演示进行了精细调优的模型,是后续很多中文 LLM 的基础。对应的中文版是Chinese-LLaMA-Alpaca。该项目在原版 LLaMA 的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,在中文LLaMA 的基础上,本项目使用了中文指令数据进行指令精调,显著提升了模型对指令的理解和执行能力。
值得注意的是,该项目开源的不是完整模型而是 LoRA 权重,理解为原 LLaMA 模型上的一个“补丁”,两者进行合并即可获得完整版权重。
提醒:仓库中的中文 LLaMA/Alpaca LoRA 模型无法单独使用,需要搭配原版 LLaMA 模型。可以参考本项目给出的合并模型步骤重构模型。
- repo: https://github.com/ymcui/Chinese-LLaMA-Alpaca/
4.2 Vicuna
Vicuna 是一款从 LLaMA 模型中对用户分享的对话进行了精细调优的聊天助手,根据的评估,这款聊天助手在 LLaMA 子孙模型中表现最佳,能达到 ChatGPT 90% 的效果。

4.3 Koala(考拉)
一款从 LLaMA 模型中对用户分享的对话和开源数据集进行了精细调优的聊天机器人,其表现与Vicuna 类似。
- blog: Koala: A Dialogue Model for Academic Research
- demo: FastChat
- repo: https://github.com/young-geng/EasyLM
4.4 Baize (白泽)
- 论文:https://arxiv.org/pdf/2304.01196.pdf
- demo: Baize Lora 7B - a Hugging Face Space by project-baize
- repo: https://github.com/project-baize/baize
4.5 Luotuo (骆驼,Chinese)
- repo: https://github.com/LC1332/Luotuo-Chinese-LLM
另外,中文 LLM 的有影响力的模型还有 ChatGLM,通常指 ChatGLM-6B, 一个由清华团队开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署 ChatGLM(INT4 量化级别下最低只需 6GB 显存)。
整体使用下来,其基本任务没问题,但是涌现能力还是有限的,且会有事实性/数学逻辑错误,另外,Close QA 问题也很一般。GLM 模型架构与 BERT、T5 等预训练模型模型架构不同,它采用了一种自回归的空白填充方法。