目录
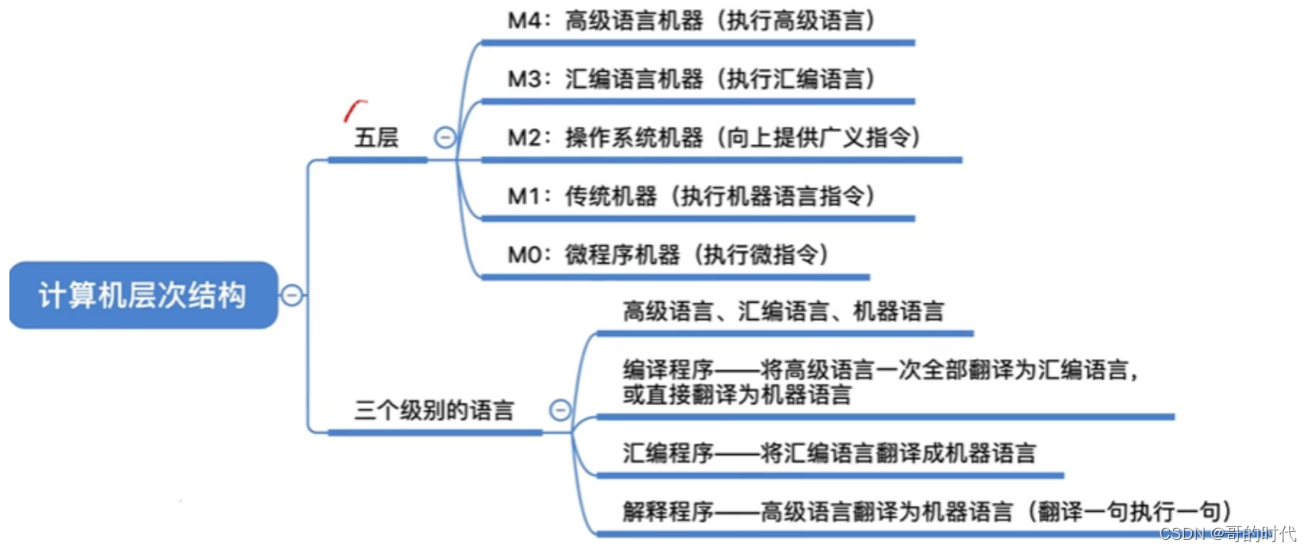
基本概念:
具体例子
1.我们先对图像进行抽象化:
2.我们将得到的六串数字进行扁平化处理:
3.解释即后续操作编辑
基本步骤:
总结
例题1:
例题2:
基本概念:
-
染色体(Chromosome):染色体是遗传算法中表示解决方案的数据结构。它是由一系列基因组成的,每个基因对应着解决方案的一个组成部分。
-
基因(Gene):基因是染色体中的一个元素,它对应着解决方案的一个特定部分。基因可以是二进制、整数或实数等不同的类型(这里的基因【解决方案的一小部分】取决于想将染色体【即解决方案】划分成由多少个相同小部分的组成),具体取决于问题的性质。
-
种群(Population):种群是由多个个体组成的集合,每个个体都表示解决方案的一个可能性。种群中的个体通过进化操作进行交叉和变异,以产生新的个体。
-
适应度函数(Fitness Function):适应度函数用于衡量个体的优劣程度(即我们给出的函数的适应程度好不好)。它将染色体映射到一个适应度值,该值指示了染色体对问题的解决程度。适应度函数的设计取决于具体的问题和优化目标。
-
选择操作(Selection):选择操作用于选择优良个体作为下一代的父代。选择操作通常根据个体的适应度值进行选择,使适应度较高的个体有更高的概率被选中(即在进行交叉和突变之后得到的种群,选择适应程度高的个体)。
-
交叉操作(Crossover):交叉操作是通过交换两个染色体的部分基因(即解决方案的一部分),产生新的个体。通过交叉操作,可以将两个个体的优良特征进行组合,产生更好的解决方案。
-
突变操作(Mutation):突变操作是在染色体中引入随机变化,以增加种群的多样性。突变操作有助于避免算法陷入局部最优解,并探索搜索空间中的新解。
-
进化(Evolution):进化是指种群中的个体通过选择、交叉和突变等操作逐代演化的过程。通过不断迭代优化,种群中的个体逐渐适应环境,并产生更好的解决方案。
-
最优解(Optimal Solution):在遗传算法中,最优解是指具有最佳适应度值的个体或染色体,它代表了问题的最优解决方案。
具体例子
为了进一步的理解这里给出具体的例子:
先举一个实际例子采用b站【数之道14】六分钟时间,带你走近遗传算法_哔哩哔哩_bilibili视频所给出的例子:

就比如说我们现在要找出最适应的解决方案,能够成功展示上面的图像。
1.我们先对图像进行抽象化:

将整个图形化成相同的6*6大小的小方格,其中对于白色格子我们用0表示,黑色格子我们用1来表示,那么我们就可以把问题最终的图形抽象为六串数字:
第一行:0 0 0 0 0 0
第二行:0 1 0 0 1 0
第三行:0 0 0 0 0 0
第四行:1 0 0 0 0 1
第五行:0 1 1 1 1 0
第六行:0 0 0 0 0 0
我们将该六串数字再重新表示一下并与原图进行比较,我们可以发现两者表示含义一样:

2.我们将得到的六串数字进行扁平化处理:
得到:0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 1 1 1 0 0 0 0 0 0 0
![]()
我们就将该得到的一串数字称为染色体,而基因则是对于其中的一个数字进行描述。
扁平化处理过程样例如下:

3.解释即后续操作
我们将扁平化后的一串数字称为原图染色体 。
基本步骤:
1.随机生成一个包含10个染色体的祖先群落:
2.随机选择两个染色体进行交叉操作,即截取染色体的一部分基因与另一个染色体进行交换,互换后得到两个新染色体(由两个原来的染色体,经过互换完成后形成的两个新染色体)
3.随机选取一个染色体进行突变操作,即在随机位置进行基因变异操作(例如让0变1,或者1变0),突变后得到一个新染色体。
4.将所有的染色体分别和原图染色体求基因差值的平方和(求得的即适合度值),对于适合值进行排序(现在有13个染色体),取最小的10个染色体作为新的群落。
重复上面的步骤,当我们每进行一次上面得到步骤,将得到的最小的染色体的逆扁平化,然后绘制成图片的时候,就可以得到染色体逐步进化的过程了。
总结
遗传算法是一个通过不断试错、交叉和突变的过程来更新种群并寻找最优解决方案的优化方法。我们可以观察到它是一个不断试错的过程。
交叉操作通过交换染色体的部分基因,促使优良特征在种群中传递和组合,从而产生更优的解决方案。这种信息交流可以帮助种群逐渐趋向最优解。
突变操作引入随机性,使得染色体产生变化。它有助于避免算法陷入局部最优解,通过引入新的个体,扩大搜索空间,有机会发现更好的解决方案。
虽然交叉和突变操作对于遗传算法的成功至关重要,但它们不是万能的。在某些情况下,交叉和突变可能无法有效地改进解决方案。在这种情况下,可能需要考虑其他策略,如改变选择操作、调整适应度函数或引入其他启发式方法。
例题1:
假设我们要使用遗传算法求解以下的多元多峰函数问题:
目标函数:f(x1, x2) = sin(x1) + cos(x2),其中 -10 ≤ x1 ≤ 10,-10 ≤ x2 ≤ 10。
我们可以使用遗传算法来寻找使目标函数取得最大值的解。
% 目标函数:f(x1, x2) = sin(x1) + cos(x2),其中 -10 ≤ x1 ≤ 10,-10 ≤ x2 ≤ 10。% 遗传算法参数设置
populationSize = 50; % 种群大小
chromosomeLength = 2; % 染色体长度
generationCount = 100; % 迭代次数
mutationRate = 0.01; % 变异率% 初始化种群
% 生成一个大小为 populationSize 行 chromosomeLength 列的随机矩阵
% 矩阵中的元素是从0到1之间均匀分布的随机小数。然后乘以 20
% 将随机数的范围扩大到0到20之间。最后减去 10,将随机数的范围调整到-10到10之间
population = rand(populationSize, chromosomeLength) * 20 - 10;% 迭代优化过程
for generation = 1:generationCount% 计算适应度fitness = calculateFitness(population);% 选择操作selectedPopulation = selection(population, fitness);% 交叉操作offspringPopulation = crossover(selectedPopulation);% 变异操作mutatedPopulation = mutation(offspringPopulation, mutationRate);% 更新种群population = mutatedPopulation;
end% 最优解
% 从种群中选择出第一个个体的所有基因
% 将这些基因赋值给 bestIndividual
% 即得到了种群中适应度最好的个体的染色体表示。
bestIndividual = population(1,:);
bestFitness = calculateFitness(bestIndividual);% 打印结果
disp(['最优解: ', num2str(bestIndividual)]);
disp(['最优适应度: ', num2str(bestFitness)]);% 计算适应度函数
function fitness = calculateFitness(population)% 计算每个个体的适应度值% 这里根据目标函数进行计算% fitness = sin(x1) + cos(x2);fitness = sin(population(:,1)) + cos(population(:,2));
end% 选择操作(使用轮盘赌选择)
function selectedPopulation = selection(population, fitness)% 根据适应度值进行选择操作% 这里使用轮盘赌选择方法% 计算适应度值的总和 fitnessSum,用于后续计算选中概率。fitnessSum = sum(fitness);% 计算每个个体被选中的概率 probabilities,即每个个体适应度值除以适应度值总和。probabilities = fitness / fitnessSum;% 计算累积概率 cumulativeProbabilities,通过对选中概率进行累加得到的向量。cumulativeProbabilities = cumsum(probabilities);% 创建一个与种群大小相同的空矩阵 selectedPopulation,用于存储选择后的个体。selectedPopulation = zeros(size(population));for i = 1:size(population, 1)r = rand();% 在累积概率向量 cumulativeProbabilities 中找到第一个大于等于 r 的索引值 selectedIdx。selectedIdx = find(cumulativeProbabilities >= r, 1);% 将种群中索引为 selectedIdx 的个体复制到 selectedPopulation 中的对应位置。selectedPopulation(i,:) = population(selectedIdx,:);end
end% 交叉操作(使用单点交叉)
function offspringPopulation = crossover(selectedPopulation)% 根据选择的个体进行交叉操作% 这里使用单点交叉方法% 创建一个与选择后种群大小相同的空矩阵 offspringPopulation,用于存储交叉后的后代个体。offspringPopulation = zeros(size(selectedPopulation));for i = 1:2:size(selectedPopulation, 1)% 获取第一个父母个体 parent1 和第二个父母个体 parent2。parent1 = selectedPopulation(i,:);parent2 = selectedPopulation(i+1,:);% 随机选择一个交叉点 crossoverPoint,位于染色体的基因位置上,用于划分交叉片段。crossoverPoint = randi([1 size(selectedPopulation, 2)]);% 通过将 parent1 的交叉点之前的基因与 parent2 的交叉点之后的基因连接,得到第一个后代个体 offspring1。offspring1 = [parent1(1:crossoverPoint) parent2(crossoverPoint+1:end)];% 通过将 parent2 的交叉点之前的基因与 parent1 的交叉点之后的基因连接,得到第二个后代个体 offspring2。offspring2 = [parent2(1:crossoverPoint) parent1(crossoverPoint+1:end)];% 将 offspring1 和 offspring2 分别存储到 offspringPopulation 中对应的位置。offspringPopulation(i,:) = offspring1;offspringPopulation(i+1,:) = offspring2;end
end% 变异操作(使用位变异)
function mutatedPopulation = mutation(offspringPopulation, mutationRate)% 对交叉后的个体进行变异操作% 这里使用位变异方法% 创建一个与交叉后个体集合大小相同的矩阵 mutatedPopulation,用于存储变异后的个体。mutatedPopulation = offspringPopulation;for i = 1:size(mutatedPopulation, 1)for j = 1:size(mutatedPopulation, 2)% 如果 rand() 小于变异率 mutationRate,则进行变异操作。 if rand() < mutationRatemutatedPopulation(i,j) = rand() * 20 - 10;endendend
end例题2:
假设我们要使用遗传算法求解以下的多元多峰函数问题:
目标函数:f(x1, x2) = -[(1 - x1)^2 + 100 * (x2 - x1^2)^2],其中 -2 ≤ x1 ≤ 2,-1 ≤ x2 ≤ 3。
该函数被称为Rosenbrock函数,是一个经典的多峰函数,具有一个全局最优解和多个局部最优解。
% 目标函数:f(x1, x2) = -[(1 - x1)^2 + 100 * (x2 - x1^2)^2],其中 -2 ≤ x1 ≤ 2,-1 ≤ x2 ≤ 3。
% 该函数被称为Rosenbrock函数,是一个经典的多峰函数,具有一个全局最优解和多个局部最优解。% 遗传算法参数设置
populationSize = 50; % 种群大小
chromosomeLength = 2; % 染色体长度
generationCount = 100; % 迭代次数
mutationRate = 0.01; % 变异率% 初始化种群
population = rand(populationSize, chromosomeLength) * 4 - 2;% 迭代优化过程
for generation = 1:generationCount% 计算适应度fitness = calculateFitness(population);% 选择操作selectedPopulation = selection(population, fitness);% 交叉操作offspringPopulation = crossover(selectedPopulation);% 变异操作mutatedPopulation = mutation(offspringPopulation, mutationRate);% 更新种群population = mutatedPopulation;
end% 最优解
bestIndividual = population(1,:);
bestFitness = calculateFitness(bestIndividual);% 打印结果
disp(['最优解: ', num2str(bestIndividual)]);
disp(['最优适应度: ', num2str(bestFitness)]);% 计算适应度函数
function fitness = calculateFitness(population)% 计算每个个体的适应度值% 这里根据目标函数进行计算x1 = population(:,1);x2 = population(:,2);fitness = -(1 - x1).^2 - 100 * (x2 - x1.^2).^2;
end% 选择操作(使用轮盘赌选择)
function selectedPopulation = selection(population, fitness)% 根据适应度值进行选择操作% 这里使用轮盘赌选择方法fitnessSum = sum(fitness);probabilities = fitness / fitnessSum;cumulativeProbabilities = cumsum(probabilities);selectedPopulation = zeros(size(population));for i = 1:size(population, 1)r = rand();selectedIdx = find(cumulativeProbabilities >= r, 1);selectedPopulation(i,:) = population(selectedIdx,:);end
end% 交叉操作(使用单点交叉)
function offspringPopulation = crossover(selectedPopulation)% 根据选择的个体进行交叉操作% 这里使用单点交叉方法offspringPopulation = zeros(size(selectedPopulation));for i = 1:2:size(selectedPopulation, 1)parent1 = selectedPopulation(i,:);parent2 = selectedPopulation(i+1,:);crossoverPoint = randi([1 size(selectedPopulation, 2)]);offspring1 = [parent1(1:crossoverPoint) parent2(crossoverPoint+1:end)];offspring2 = [parent2(1:crossoverPoint) parent1(crossoverPoint+1:end)];offspringPopulation(i,:) = offspring1;offspringPopulation(i+1,:) = offspring2;end
end% 变异操作(使用位变异)
function mutatedPopulation = mutation(offspringPopulation, mutationRate)% 对交叉后的个体进行变异操作% 这里使用位变异方法mutatedPopulation = offspringPopulation;for i = 1:size(mutatedPopulation, 1)for j = 1:size(mutatedPopulation, 2)if rand() < mutationRatemutatedPopulation(i,j) = rand() * 4 - 2;endendend
end