1. 为什么要使用kafka集群
单机服务下,Kafka已经具备了非常高的性能。TPS能够达到百万级别。但是,在实际工作中使用时,单机搭建的Kafka会有很大的局限性。
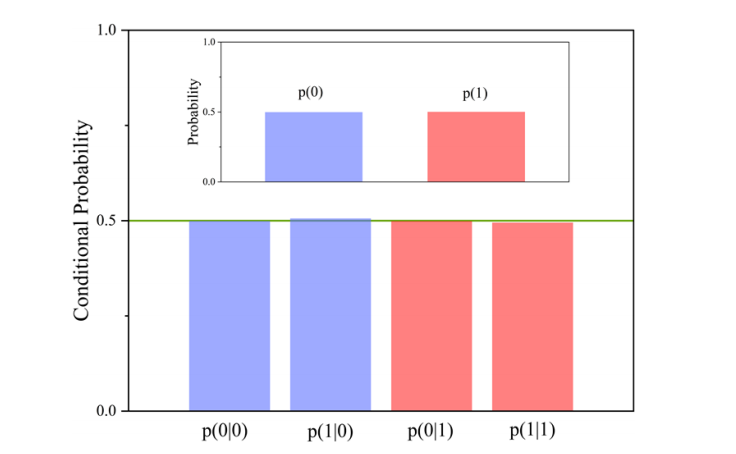
- 消息太多,需要分开保存。Kafka是面向海量消息设计的,一个Topic下的消息会非常多,单机服务很难存得下来。这些消息就需要分成不同的Partition,分布到多个不同的Broker上。这样每个Broker就只需要保存一部分数据。这些分区的个数就称为分区数。
- 服务不稳定,数据容易丢失。单机服务下,如果服务崩溃,数据就丢失了。为了保证数据安全,就需要给每个Partition配置一个或多个备份,保证数据不丢失。Kafka的集群模式下,每个Partition都有一个或多个备份。Kafka会通过一个统一的Zookeeper集群作为选举中心,给每个Partition选举出一个主节点Leader,其他节点就是从节点Follower。主节点负责响应客户端的具体业务请求,并保存消息。而从节点则负责同步主节点的数据。当主节点发生故障时,Kafka会选举出一个从节点成为新的主节点。
- Kafka集群中的这些Broker信息,包括Partition的选举信息,都会保存在额外部署的Zookeeper集群当中,这样,kafka集群就不会因为某一些Broker服务崩溃而中断。
2. kafka的集群架构
由章节1中对kafka集群特点的描述,我们可以大致画出kafka的集群架构图大致如下:

3. kafka集群搭建
接下来我们就动手部署一个Kafka集群,来体验一下Kafka是如何面向海量数据进行横向扩展的。
搭建环境:
1. 准备3台虚拟机
2. 安装jdk
jdk安装可参考Linux环境下安装JDK-CSDN博客
3. 关闭防火墙(实验版本关闭防火墙,生产环境开启对应端口即可)
firewall-cmd --state 查看防火墙状态 systemctl stop firewalld.service 关闭防火墙
第一步: zookeeper 集群搭建
kafka依赖于zookeeper,虽然kafka内部自带了一个zookeeper,为了保证服务之间的独立性,不建议使用其内部的zookeeper,所以我们先搭建一个独立的zookeeper集群。Zookeeper是一种多数同意的选举机制,允许集群中少数节点出现故障。因此,在搭建集群时,通常都是采用3,5,7这样的奇数节点,这样可以最大化集群的高可用特性。
zk集群搭建参考:zookeeper之集群搭建-CSDN博客
根据上述文章搭建完成之后,启动zookeeper集群
第二步: 部署kafka集群
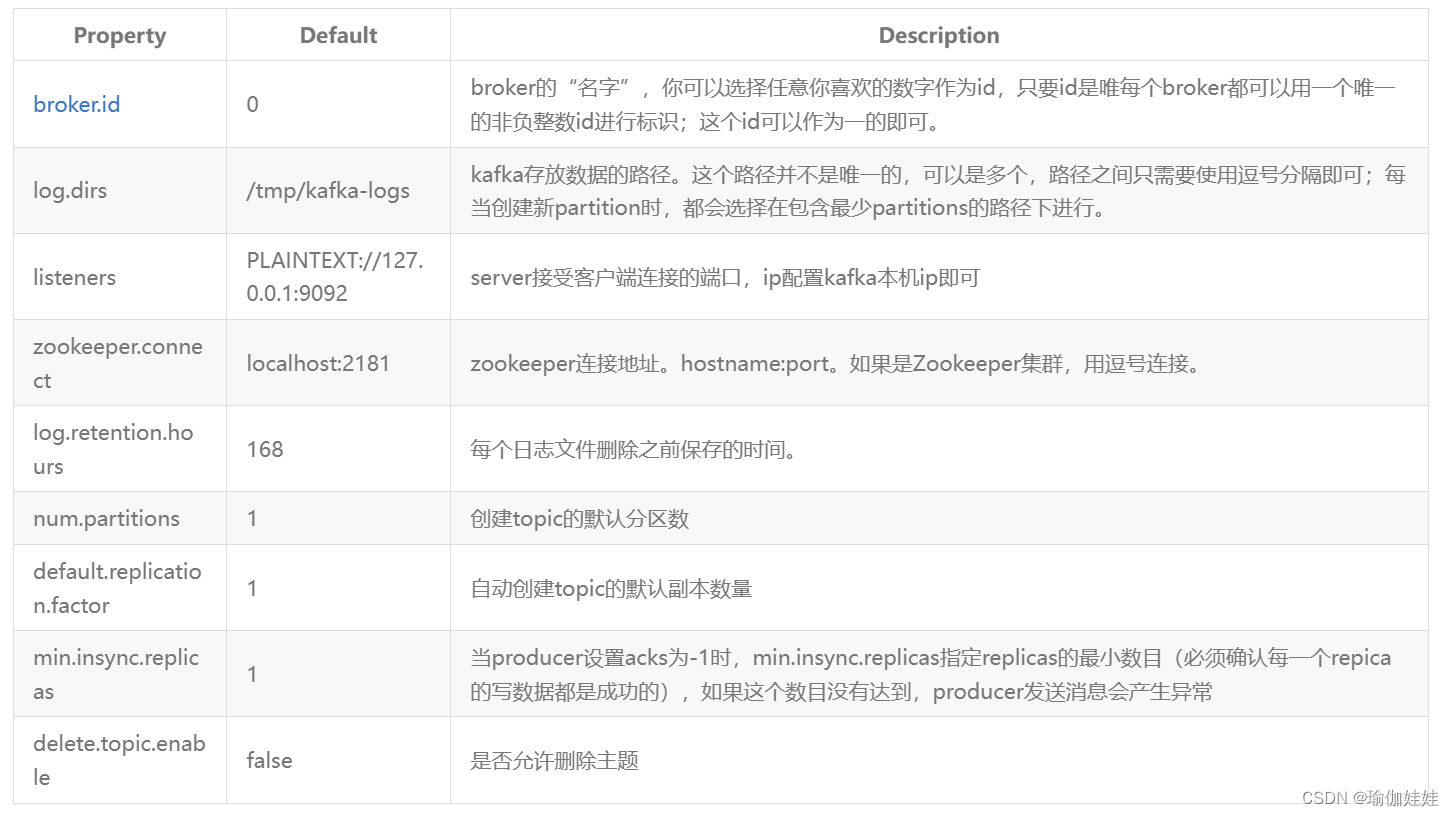
kafka服务并不需要进行选举,因此也没有奇数台服务的建议。首先,三台机器都根据 初识Kafka-CSDN博客 中的单机服务体验,上传、解压kafka到 解压到 /app/kafka 目录下。接下来,进入config目录,修改server.properties。这个配置文件里面的配置项非常多,下面列出几个要重点关注的配置#broker 的全局唯一编号,不能重复,只能是数字。 broker.id=0 #数据文件地址。同样默认是给的/tmp目录。 log.dirs=/app/kafka/logs #默认的每个Topic的分区数 num.partitions=1 #zookeeper的服务地址 zookeeper.connect=192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181broker.id需要每个服务器上不一样,分发到其他服务器上时,要注意修改一下,比如第一台是0,第二台就是1,第三台的配置就是2。
当多个Kafka服务注册到同一个zookeeper集群上的节点,会自动组成集群。
server.properties文件中比较重要的核心配置
第三步: 启动kafka集群
bin/kafka-server-start.sh -daemon config/server.properties-daemon表示后台启动kafka服务,这样就不会占用当前命令窗口。
jps看一下启动情况:



4. 理解Kafka集群当中核心的Topic、Partition、Broker
5.总结
内容完善中~