版本控制背景知识
本文是关于 Git 系列文章的导读,我们先介绍一下版本控制的背景知识。
什么是版本控制
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。它将什么时候、什么人更改了文件的什么内容等信息如实记录下来。
除了记录版本变更外,版本控制的另一个重要功能是并行开发。软件开发往往是多人协同作业,版本控制可以有效地解决版本的同步以及不同开发者之间的开发通信问题,提高协同开发的效率。并行开发中最常见的不同版本软件的错误(Bug)修正问题也可以通过版本控制中分支与合并的方法有效地解决。
版本控制的好处
- 备份和恢复:版本控制系统会自动保存每次提交的快照,因此我们可以随时回到之前的版本。
- 协作:版本控制系统可以帮助多个开发人员协同工作,解决代码冲突。
- 追踪更改:版本控制系统可以帮助我们查看每个版本之间的差异,了解谁更改了什么。
- 测试和调试:使用版本控制系统,我们可以轻松地切换到不同的版本,以便测试和调试。
版本控制类型
本地版本控制系统
许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。 这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。

其中最流行的一种叫做 RCS,现今许多计算机系统上都还看得到它的踪影。 RCS 的工作原理是在硬盘上保存补丁集(补丁是指文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
集中化的版本控制系统
接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作? 于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。 这类系统,诸如 CVS、Subversion 以及 Perforce 等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。 多年以来,这已成为版本控制系统的标准做法。

这种做法带来了许多好处,特别是相较于老式的本地 VCS 来说。 现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。
事分两面,有好有坏。 这么做最显而易见的缺点是中央服务器的单点故障。 如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。 如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问我们将丢失所有数据——包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。 本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
分布式版本控制系统
于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。 在这类系统中,像 Git、Mercurial 以及 Darcs 等,客户端并不只提取最新版本的文件快照, 而是把代码仓库完整地镜像下来,包括完整的历史记录。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
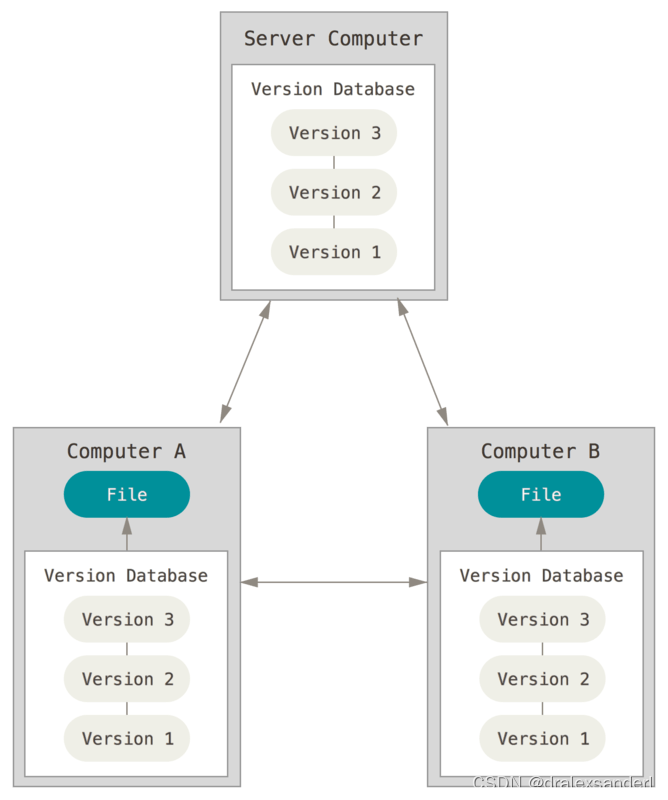
更进一步,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,我们就可以在同一个项目中,分别和不同工作小组的人相互协作。 我们可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
Git 版本控制
Git 是属于「分布式版本控制」系统。
Git 包含了以下几个重要的设计:
- 强力支持非线性开发模式
-
- Git 拥有快速的分支与合并机制,还包括图形化的工具显示版本变更的历史记录。
-
- Git 非常强调分支与合并,所以版本控制的过程中,我们会不断的在执行分支与合并动作。
-
- Git 的分支机制非常轻量,每一次的分支只是某个 commit 的索引而已。
- 分散式开发模型
-
- 参与 Git 开发的每个人,都将拥有完整的开发历史记录。
-
- 当开发人员第一次将 Git 版本库复制 (clone) 下来后,完全等同于这份 Git 版本库的「完整备份」。
-
- 整个版本库中所有变更过的文件与历史记录,都会储存在本地仓库中。
- 开发大型项目时更有效率
-
- 由于完整的版本库会复制 (clone) 一份在本地,该版本库包含完整的文件与版本变更记录,所以针对版本控制中的各种文件操作速度,将会比直接从远端存取来的快上百倍之多。
-
- 这也代表着 Git 版本控制不会因为项目越来越大、文件越来越多,而导致速度变慢。
- 历史记录保护
-
- Git 版本控制的过程中,每次 commit 都会产生一组 hash id 编号,而且每个版本在变化的过程都会参考到这个 hash id,只要 hash id 无法比对的上,Git 就会无法运作,所以当项目越来越大,版本库复制 (clone) 的越来越多份,我们几乎无法窜改文件的内容或版本记录。
-
- 每个人都有一份完整的版本库,我们改了原始的那份,所有人的版本库就无法再合并回原本的版本库了,所以我们几乎不可能任意窜改版本记录。
- 弹性的合并策略
-
- Git 拥有良好的设计「不完整合并 机制,以及多种可以完成合并的演算法,并在最后告知使用者为何无法自动完成合并,或通知我们需要手动进行合并动作。
- 被动的垃圾回收机制
-
- 在使用 Git 的时候,若想要中断目前的操作或回复上一个操作,都是可以的,我们完全可以不必担心可能有其中一个指令下错,或指令执行到一半宕机等问题。
-
- Git 的垃圾回收机制,其实就是那些残留在文件系统中的无用文件,这个垃圾回收机制只会在这些无用的对象累积一段时间后自动执行,或我们也可以自行下达指令清空它。例如: git gc --prune
- 定期的封装对象
-
- 我们在 Git 中提到的 “对象” 其实就是代表版本库中的一个文件。而在版本变动的过程中,项目中的代码或其他文件会被更新,每次更新时,只要文件内容不一样,就会建立一个新的 “对象”,这些不同内容的文件全部都会保留下来。
-
- 我们可以想像,当一个项目越来越大、版本越来越多时,这个对象会越来越多,虽然每个文件都可以各自压缩让文件变小,不过过多的文件还是会文件存取变得越来越没效率。因此 Git 的设计有个机制可以将一群老旧的 “对象” 自动封装进一个封装档 (packfile) 中,以改善文件存取效率。
-
- 那些新增的文件还是会以单一文件的方式存在着,也代表一个 Git 版本库中的 “文件” 就是一个 Git “对象”,但每隔一段时间就会需要重新封装 (repacking)。
-
- 照理说 Git 会自动执行重新封装等动作,但我们依然可以自行下达指令执行。例如: git gc
-
- 如果我们要检查 Git 维护的文件系统是否完整,可以执行以下指令: git fsck
参考文章
- 1.1 Getting Started - About Version Control