目录
1.1导入库
1.2读取excel文件
1.3读取excel,指定sheet2工作表
1.4指定行索引
1.5指定列索引
1.6指定导入列
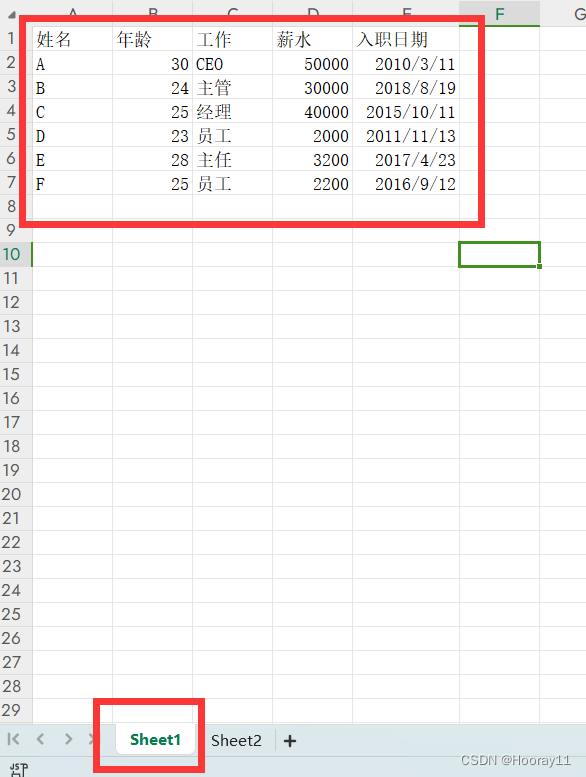
案例速览:
1.1导入库
import pandas as pd1.2读取excel文件
pd.read_excel('文件路径')
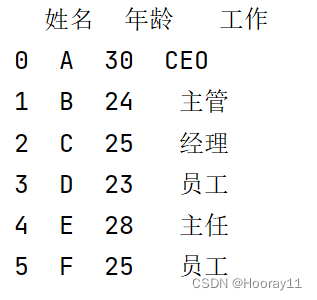
data = pd.read_excel('D:/desktop/TestExcel.xlsx')print(data)
1.3读取excel,指定sheet2工作表
pd.read_excel('文件路径',sheet_name='工作表名称')
注意:sheet_name也可以按照索引去访问工作表,比如等于0的时候表示第一个工作表
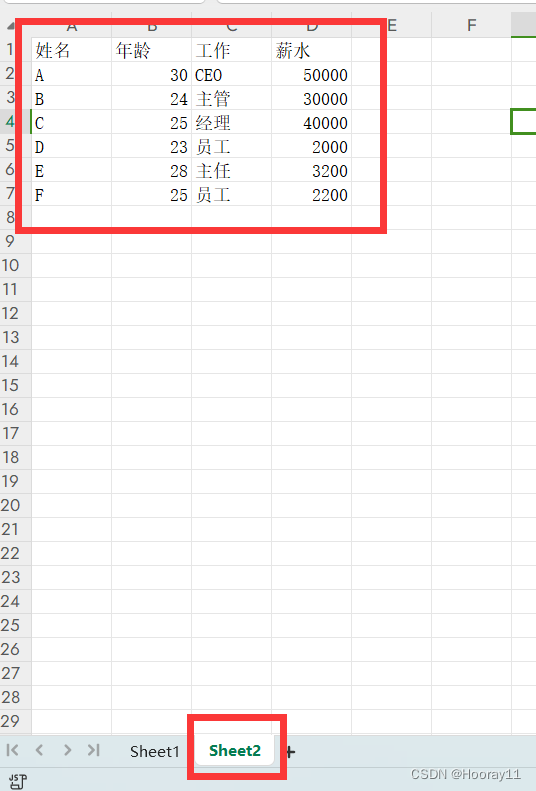
data = pd.read_excel('D:/desktop/TestExcel.xlsx',sheet_name='Sheet2')print(data)
1.4指定行索引
pd.read_excel('文件路径',index_col=0)
注意:index_col可以按照索引去访问列,比如等于0的时候表示第一列
data = pd.read_excel('D:/desktop/TestExcel.xlsx',index_col=0)print(data)
1.5指定列索引
pd.read_excel('文件路径',header=0)
注意:header可以按照索引去访问行,比如等于0的时候表示第一行
使用默认的列索引,可以直接将header=None
data = pd.read_excel('D:/desktop/TestExcel.xlsx',header=1)print(data)
1.6指定导入列
pd.read_excel('文件路径',usecols=2)
注意:usecols可以按照索引去访问列,比如等于2的时候表示访问前三列
按理来说是这么一回事,但是会报错
data = pd.read_excel('D:/desktop/TestExcel.xlsx',sheet_name='Sheet1',usecols=2)print(data)ValueError: Passing an integer for `usecols` is no longer supported. Please pass in a list of int from 0 to `usecols` inclusive instead.
大概意思是要传入一个整数列表,所以如果想要取出前三列,就要这么写
data = pd.read_excel('D:/desktop/TestExcel.xlsx',sheet_name='Sheet1',usecols=[0,1,2])print(data)