首先需要安装第三方包pyecharts
1 基础折线图
# 导包,导入Line功能构建折线图对象
from pyecharts.charts import Line # 折线图
from pyecharts.options import TitleOpts # 标题
from pyecharts.options import LegendOpts # 图例
from pyecharts.options import ToolboxOpts # 工具箱
from pyecharts.options import VisualMapOpts # 视觉映射# 得到折线图对象
line = Line()# 添加x轴数据
line.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])# 添加y轴数据
line.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])# 设置全局配置项
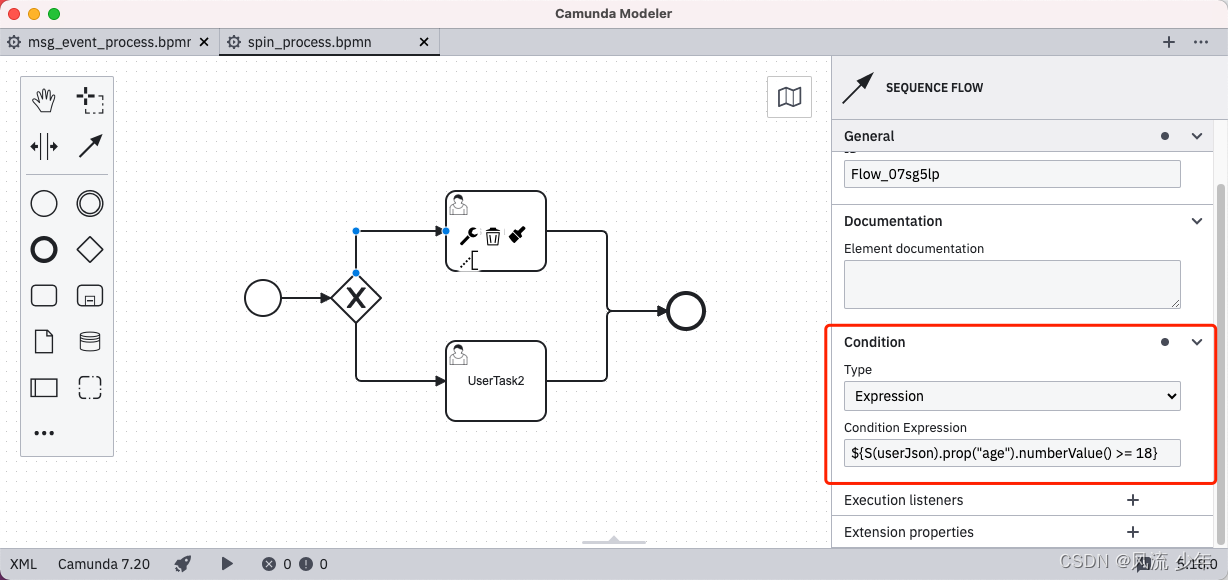
line.set_global_opts(title_opts = TitleOpts(title="商品展示", pos_left="center", pos_bottom="1%"), # 设置标题legend_opts = LegendOpts(is_show=True), # 图例toolbox_opts=ToolboxOpts(is_show=True), # 工具箱visualmap_opts=VisualMapOpts(is_show=True) # 视觉映射
)# 利用render()方法,生成图像
line.render("./modules/render.html")代码中的注释是非常清楚了,就不多解释了

2 折线图案例开发
给了3个国家的疫情信息,以json的格式(如下图),需要以折线图的形式展示


对数据进行处理,这里只需要对一个国家的数据进行处理就行了,另外两个复制粘贴就行了
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, TooltipOpts, VisualMapOpts,LabelOpts
# 读取文件数据并处理数据
fr_us = open("./text/美国.txt", "r", encoding='utf-8')
fr_jp = open("./text/日本.txt", "r", encoding='utf-8')
fr_ia = open("./text/印度.txt", "r", encoding='utf-8')us_data = fr_us.read()
jp_data = fr_jp.read()
ia_data = fr_ia.read()# 去掉文件中不符合json规范的内容
us_data = us_data.replace('jsonp_1629344292311_69436(', '')
us_data = us_data[:-2] # 切片,去掉末尾的
jp_data = jp_data.replace('jsonp_1629350871167_29498(', '')
jp_data = jp_data[:-2] # 切片,去掉末尾的
ia_data = ia_data.replace('jsonp_1629350745930_63180(', '')
ia_data = ia_data[:-2] # 切片,去掉末尾的# Json转为Python字典
us_dict = json.loads(us_data)
# print(us_dict)
# print(type(us_dict))
jp_dict = json.loads(jp_data)
ia_dict = json.loads(ia_data)us_trend_data = us_dict['data'][0]['trend']
# print(us_trend_data)
# print(type(us_trend_data))
jp_trend_data = jp_dict['data'][0]['trend']
ia_trend_data = ia_dict['data'][0]['trend']us_x_data = us_trend_data['updateDate'][:314] # 只要一年的日期数据
# print(us_x_data)
# print(type(us_x_data))
jp_x_data = jp_trend_data['updateDate'][:314]
ia_x_data = ia_trend_data['updateDate'][:314]us_y_data = us_trend_data['list'][0]['data'][:314]
# print(us_y_data)
# print(type(us_y_data))
jp_y_data = jp_trend_data['list'][0]['data'][:314]
ia_y_data = ia_trend_data['list'][0]['data'][:314]根据处理后的数据构建折线图
# 构建图表
line = Line()# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是公用的# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # label_opts=LabelOpts(is_show=False)可以设置图例
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数", ia_y_data, label_opts=LabelOpts(is_show=False))# 设置全局配置项
line.set_global_opts(# 设置标题title_opts=TitleOpts(title="世界疫情趋势图", pos_left="center", pos_bottom="1%")#
)# 调用render方法,将图表渲染成html文件
line.render("./modules/world_covid_trend.html")最后也别忘了关闭文件
fr_us.close()
fr_jp.close()
fr_ia.close()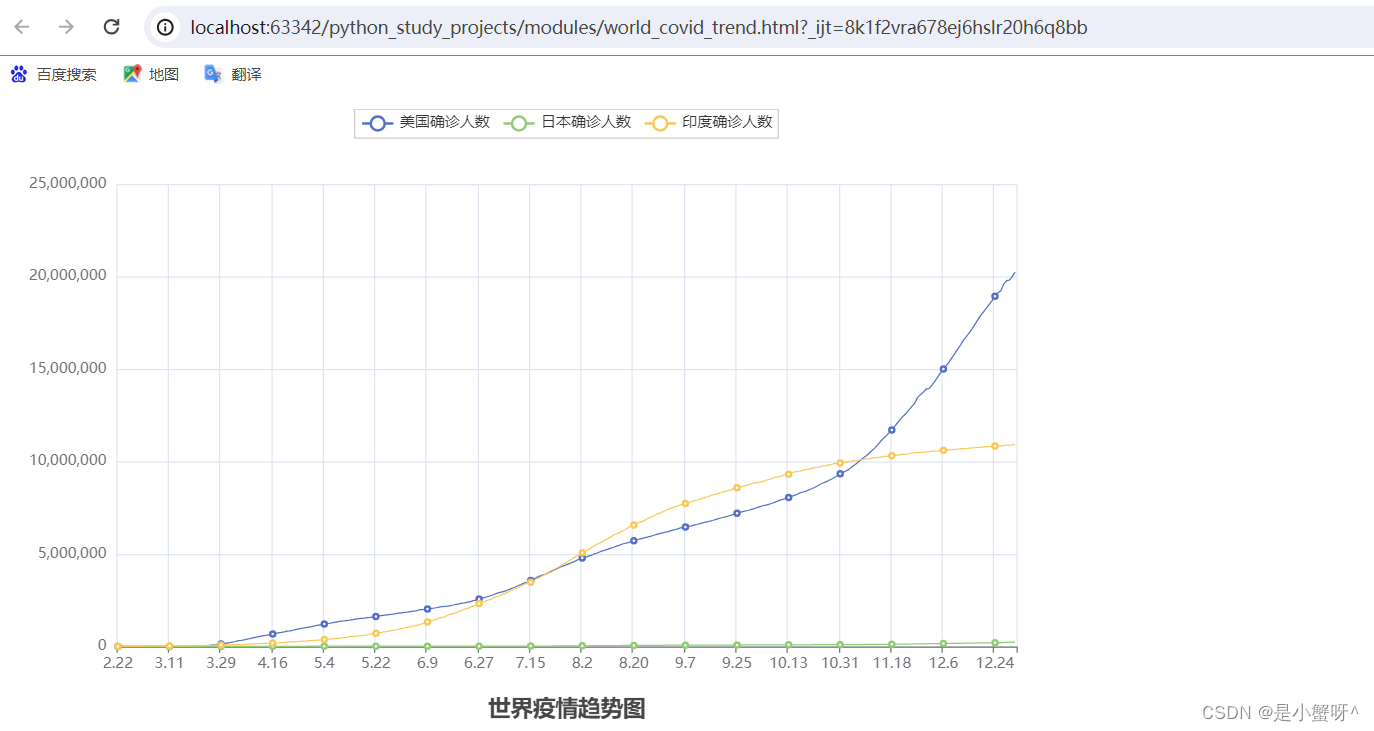



![[自动驾驶算法][从0开始轨迹预测]:一、坐标和坐标系变换](https://img-blog.csdnimg.cn/direct/7925a7eeda9743c39eea9656e0494a25.png#pic_center)




![thinkphp6报错Driver [Think] not supported.](https://img-blog.csdnimg.cn/direct/e30bb3b7b39242bc9b7145a112c6af48.png#pic_center)


![[开发语言][c++][python]:C++与Python中的赋值、浅拷贝与深拷贝](https://img-blog.csdnimg.cn/img_convert/b738c28f6b2531e40f980cef0742b6ee.png)