科学突破很少发生在真空中。相反,它们往往是建立在积累的人类知识之上的阶梯的倒数第二步。要了解 ChatGPT 和 Google Bart 等大型语言模型 (LLM) 的成功,我们需要回到过去并谈论 BERT。
BERT 由 Google 研究人员于 2018 年开发,是首批 LLM 之一。凭借其惊人的结果,它迅速成为NLP任务中无处不在的基线,包括一般语言理解,问答和命名实体识别。
可以说,BERT为我们如今目睹的生成式AI革命铺平了道路。尽管 BERT 是最早的 LLM 之一,但它仍然被广泛使用,有数千个开源、免费和预训练的 BERT 模型可用于特定用例,例如情感分析、临床笔记分析和有害评论检测。
对 BERT 感到好奇吗?继续阅读本文,我们将探讨 Ber 的架构、该技术的内部工作原理、它的一些实际应用及其局限性。
什么是 BERT?
BERT(代表 Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年开发的开源模型。这是一项雄心勃勃的实验,旨在测试所谓的 Transformers(一种创新的神经架构,由谷歌研究人员在 2017 年的著名论文《注意力是你所需要的一切》中提出)在自然语言 (NLP) 任务上的性能。
BERT成功的关键在于其变压器架构。在 Transformer 出现之前,对自然语言进行建模是一项非常具有挑战性的任务。尽管复杂的神经网络(即递归神经网络或卷积神经网络)兴起,但结果仅部分成功。
主要的挑战在于神经网络用于预测句子中缺失单词的机制。当时,最先进的神经网络依赖于编码器-解码器架构,这是一种功能强大但耗时耗资源的机制,不适合并行计算。
考虑到这些挑战,谷歌研究人员开发了转换器,这是一种基于注意力机制的创新神经架构,如下一节所述。
BERT是如何工作的
让我们来看看 BERT 是如何工作的,包括模型背后的技术、它是如何训练的以及它如何处理数据。
核心体系结构和功能
递归神经网络和卷积神经网络使用顺序计算来生成预测。也就是说,一旦在大型数据集上进行训练,他们可以预测哪个单词将遵循给定的单词序列。从这个意义上说,它们被认为是单向或上下文无关的算法。
相比之下,像BERT这样同样基于编码器-解码器架构的转换器驱动的模型是双向的,因为它们根据前一个单词和后面的单词来预测单词。这是通过自注意力机制实现的,自注意力机制是编码器和解码器中都包含的一层。注意力层的目标是捕获输入句子中不同单词之间存在的上下文关系。
如今,预训练的BERT有很多版本,但在最初的论文中,Google 用不同的神经架构训练了两个版本的 BERT: BERTbase 和 BERTlarge。本质上,BERTbase 有12个变压器层,12个关注层,1.1亿个参数,而 BERTlarge 有 24 个变压器层,16个关注层,3.4 亿个参数。正如预期的那样,BERTlarge 在准确性测试中的表现优于它的小兄弟。
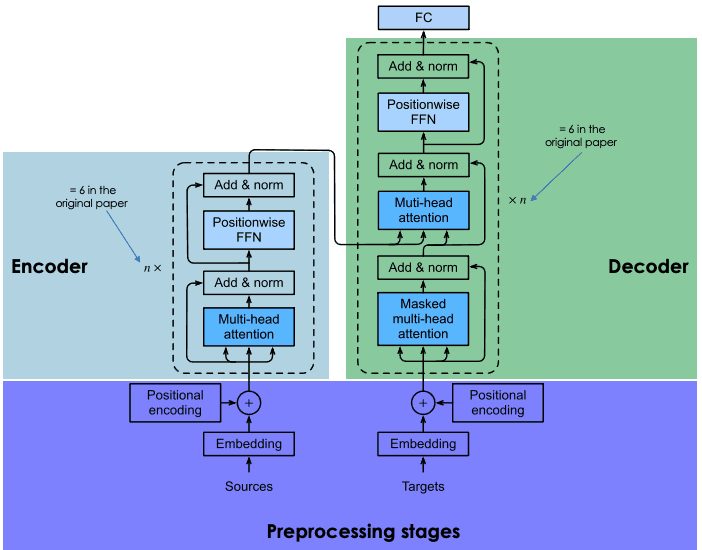
预训练和微调
Transformer 在庞大的数据语料库上从头开始训练,遵循一个耗时且昂贵的过程(只有包括 Google 在内的少数公司才能负担得起)。
就 BERT 而言,它在维基百科(~2.5B 字)和 Google 的 BooksCorpus(~800M 字)上进行了为期四天的预训练。这使得该模型不仅可以获得英语知识,还可以获得来自世界各地的许多其他语言的知识。
为了优化训练过程,谷歌开发了新的硬件,即所谓的TPU(张量处理单元),专为机器学习任务而设计。
为了避免训练过程中不必要且成本高昂的交互,谷歌研究人员使用迁移学习技术将(预)训练阶段与微调阶段分开。这允许开发人员选择预训练模型,细化目标任务的输入输出对数据,并使用特定于领域的数据重新训练预训练模型的头部。这个特性使像 BERT 这样的 LLM 成为建立在它们之上的无穷无尽的应用程序的基础模型,
掩码语言建模在BERT处理中的作用
在BERT(以及每个基于transformers的LLM)中实现双向学习的关键因素是注意力机制。此机制基于掩码语言建模 (MLM)。通过屏蔽句子中的单词,此技术迫使模型在句子中两个方向上分析剩余的单词,以增加预测被屏蔽单词的机会。MLM基于在计算机视觉领域已经尝试过的技术,非常适合需要对整个序列有良好上下文理解的任务。
BERT是第一个应用这种技术的法学硕士。特别是,随机 15% 的标记化单词在训练期间被屏蔽。结果表明,BERT能够较准确地预测隐藏词。
BERT是做什么用的?BERT对NLP的影响
在转换器的支持下,BERT能够在多个NLP任务中实现最先进的结果。以下是 BERT 擅长的一些测试:
- 问答:BERT是最早由变压器驱动的聊天机器人之一,取得了令人印象深刻的成果。
- 情绪分析:例如,BERT已经成功地预测了电影评论的正面或负面标点符号。
- 文本生成:作为下一代聊天机器人的前身,BERT已经能够通过简单的提示创建长文本。
- 总结文本:同样,BERT能够阅读和总结来自复杂领域的文本,包括法律和医疗保健。
- 语言翻译:BERT已经接受过多种语言编写的数据训练。这使它成为一个多语言模型,这意味着它非常适合语言翻译。
- 自动完成任务:BERT 可用于自动完成任务,例如,在电子邮件或消息传递服务中。
BERT的实际应用
许多LLM已经在实验集中进行了尝试,但尚未将许多LLM纳入成熟的应用程序中。BERT的情况并非如此,它每天都有数百万人使用(尽管我们可能没有意识到这一点)。
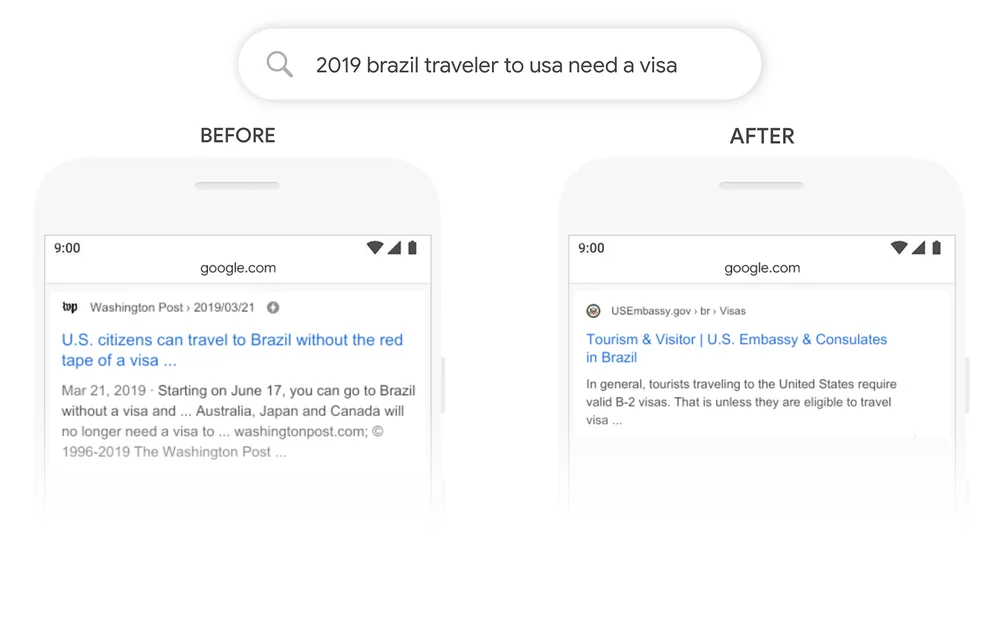
一个很好的例子是谷歌搜索。2020 年,谷歌宣布已通过 70 多种语言的 Google 搜索采用 BERT。这意味着谷歌使用BERT对内容进行排名并显示精选片段。借助注意力机制,Google 现在可以使用问题的上下文来提供有用的信息,如以下示例所示。
BERT的变体和改编
但这只是故事的一部分。BERT的成功很大程度上归功于其开源性质,它允许开发人员访问原始BERT的源代码并创建新功能和改进。
这导致了大量的 BERT 变体。下面,您可以找到一些最著名的变体:
- RoBERTa : RoBERTa 是“Robustly Optimized BERT Approach”的缩写,是 Meta 与华盛顿大学合作创建的 BERT 变体。RoBERTa 被认为是比原始 BERT 更强大的版本,它使用比用于训练 BERT 的数据集大 10 倍的数据集进行训练。至于它的架构,最显着的区别是使用动态掩码学习而不是静态掩码学习。这种技术涉及复制训练数据并对其进行 10 次屏蔽,每次都使用不同的掩码策略,使 RoBERTa 能够学习更强大和可推广的单词表示。
- DistilBERT:自 2010 年代后期推出第一批 LLM 以来,一直存在着构建更大、更重的 LLM 的综合趋势。这是有道理的,因为模型大小和模型精度之间似乎存在直接关系。然而,模型越大,运行所需的资源就越多,因此,使用它的人就越少。DistilBERT 旨在通过提供更小、更快、更便宜和更轻的变体来使 BERT 更易于访问。基于原始 BERT 的架构,DistilBERT 在预训练期间使用知识提炼技术,将大小减少 40%,同时保留其 97% 的语言理解能力,速度提高 60%。
- ALBERT:ALBERT 代表 A Lite BERT,专门设计用于在预训练期间提高 BERTlarge 的效率。由于训练更大的模型通常会导致内存限制、更长的训练时间和意外的模型退化,因此 ALBERT 的创建者开发了两种参数缩减技术来减少内存咨询并提高训练期间的速度。
如果您想了解更多关于开源 LLM 运动的信息,我们强烈建议您阅读我们关于 2023 年顶级开源 LLM 的帖子
针对特定任务微调 BERT
BERT 和一般的 LLM 最伟大的事情之一是预训练过程与微调过程是分开的。这意味着开发人员可以采用预先训练的 BERT 版本,并针对他们的特定用例对其进行自定义。
就 BERT 而言,有数百个针对各种 NLP 任务开发的 BERT 微调版本。下面,您可以找到一个非常非常有限的 BERT 微调版本列表:
- BERT-base-chinese:一个针对中文 NLP 任务训练的 BERTbase 版本
- BERT-base-NER: 为命名实体识别定制的 BERTbase 版本
- Symps_disease_bert_v3_c41。自然语言聊天机器人的症状到疾病分类模型。
- BERT专利:是谷歌在全球100M+专利上训练的模型。它基于 BERTlarge。
了解 BERT 的局限性
BERT 具有与 LLM 相关的传统限制和问题。BERT的预测始终基于用于训练它的数据的数量和质量。如果训练数据有限、贫乏且有偏见,BERT 可能会抛出不准确、有害的结果,甚至是所谓的LLM幻觉 。
在原始 BERT 的情况下,这种情况更有可能发生,因为该模型是在没有从人类反馈中强化学习 (RLHF) 的情况下训练的,RLHF 是 ChatGPT、LLaMA 2 和 Google Bard 等更高级模型使用的标准技术,用于增强 AI 安全性。RLHF 涉及在培训期间使用人类反馈来监控和指导 LLM 的学习过程,从而确保有效、安全和可信的系统。
此外,尽管与其他最先进的 LLM (如 ChatGPT)相比,它可以被认为是一个小模型,但它仍然需要相当大的计算能力来运行它,更不用说从头开始训练它了。因此,资源有限的开发人员可能无法使用它。
BERT和NLP的未来
BERT是最早的现代LLM之一。但远非老式,BERT仍然是最成功和最广泛使用的LLM之一。 由于其开源性质,今天,有多种变体和数百个预训练版本的BERT专为特定的NLP任务而设计。