背景介绍
由于我们主要介绍撰写脚本的方法,所以用一个简单的文本例子进行分析
a[(19,18),(20,53)]
Although[(11,1),(16,1),(18,1)]
ambiguity[(14,16)]以上内容可以保存在一个txt文件中,任务是统计文件中每一个词(包括字母,数字以及下划线的组合)位置,建立一个映射表,主键是词的内容,值是包含对应词位置的列表数据,列表的每一个元素是词出现的位置对应的元组
一般方法
import re
match = re.compile(r'\w+')
match_dist_3 = {}
with open('./num.txt',encoding='utf-8') as w:for row_id,line in enumerate(w,1):for word_match in match.finditer(line):col_id = word_match.start()+1word = word_match.group()postion = (row_id,col_id)postion_list = match_dist_3.get(word,[])postion_list.append(postion)match_dist_3[word]=postion_list
print(match_dist_3)match = re.compile(r'\w+')是定义正则匹配的规则,获得连续出现的字母、数字或者下划线的分割,enumerate(w,1)是获取从1开始的计数,match.finditer(line)是按照正则分割的规则对文本文件中的每一行进行分割获得想要排上位置序号的文本内容,col_id = word_match.start()+1是获取匹配的序号,这里可以理解为在文本中的列号(我们的行和列都默认从1开始计数)
postion是储存文本数据位置的元组, postion_list = match_dist_3.get(word,[])是获取match_dist_3字典中以word为主键的值赋值给postion_list,如果没有则返回空表, postion_list.append(postion)接着对postion_list增加元素,最后再把更新后的postion_list赋值到对应的主键位置上,完成映射表的更新
从上面的代码可以看出,对于字典类型的映射表的更新,需要先获得值再进行更新后再赋值回去,来来回回需要三步,显得代码有些冗余,而setdefault的使用可以直接就地更新字典的值
setdefault方法
match_dist = {}
with open('./num.txt',encoding='utf-8') as w:for row_id,line in enumerate(w,1):for word_match in match.finditer(line):col_id = word_match.start()+1word = word_match.group()postion = (row_id,col_id)match_dist.setdefault(word,[]).append(postion)我们可以直接通过 match_dist.setdefault(word,[]).append(postion)这一行代码完成一般方法中的三行代码的功能,其含义是查找match_dist字典中的word主键对应的值,若不存在则返回空表,并在此基础上直接加上新获取的word对应的postion,使得代码简洁了需要
我们来打印输出一下
for word in sorted(match_dist,key=str.upper): # 直接显示的是主键print(word,match_dist[word])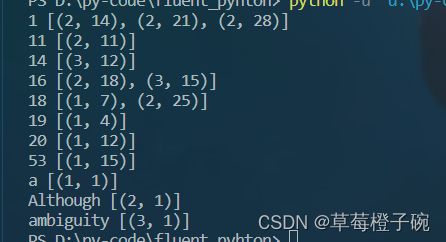
可以看到已经成功获得每个word对应的位置的映射表
欢迎大家讨论交流~