在本节中,你将了解另一种机器学习搜索方法,该方法利用 Elastic Learned Sparse EncodeR 模型或 ELSER,这是一种由 Elastic 训练来执行语义搜索的自然语言处理模型。这是继之前的文章 “Elasticsearch:Search tutorial - 使用 Python 进行搜索 (三)” 的续篇。
ELSER 模型
在上一章中,您了解了如何使用由机器学习模型生成的嵌入填充的 dend_vector 字段来扩展 Elasticsearch 索引。 该模型安装在你的计算机本地,嵌入是从 Python 代码生成的,并在插入索引之前添加到文档中。
在本章中,你将了解另一种向量类型,sparse_vector,它旨在存储来自 Elastic Learned Sparse EncodeR 模型 (ELSER) 的推论。 该模型返回的嵌入是标签的集合(更恰当地称为特征),每个标签都具有指定的权重。
在本章中,你还将使用不同的方法来处理机器学习模型,其中 Elasticsearch 服务本身运行模型并通过管道将生成的嵌入添加到索引中。
稀疏向量字段
与上一章中使用的密集向量字段类型一样,稀疏向量类型可以存储机器学习模型返回的推论。 密集向量保存描述源文本的固定长度的数字数组,而稀疏向量则存储特征到权重的映射。
让我们向索引添加一个稀疏向量字段。 这是需要在索引映射中显式定义的类型。 下面你可以看到 create_index() 方法的更新版本,其中包含一个名为 elser_embedding 的此类型的新字段。
search.py
class Search:# ...def create_index(self):self.es.indices.delete(index='my_documents', ignore_unavailable=True)self.es.indices.create(index='my_documents', mappings={'properties': {'embedding': {'type': 'dense_vector',},'elser_embedding': {'type': 'sparse_vector',},}})# ...
部署 ELSER 模型
如上所述,在此示例中,Elasticsearch 将获得模型的所有权并在插入文档和搜索时自动执行它以生成嵌入。
Elasticsearch 客户端公开一组 API 端点来管理机器学习模型及其管道。 search.py 中的以下 deploy_elser() 方法遵循几个步骤来下载和安装 ELSER v2 模型,并创建一个使用它来填充上面定义的 elser_embedding 字段的管道。
search.py
class Search:# ...def deploy_elser(self):# download ELSER v2self.es.ml.put_trained_model(model_id='.elser_model_2',input={'field_names': ['text_field']})# wait until readywhile True:status = self.es.ml.get_trained_models(model_id='.elser_model_2',include='definition_status')if status['trained_model_configs'][0]['fully_defined']:# model is readybreaktime.sleep(1)# deploy the modelself.es.ml.start_trained_model_deployment(model_id='.elser_model_2')# define a pipelineself.es.ingest.put_pipeline(id='elser-ingest-pipeline',processors=[{'inference': {'model_id': '.elser_model_2','input_output': [{'input_field': 'summary','output_field': 'elser_embedding',}]}}])
为我们配置 ELSER 需要几个步骤。 首先,使用 Elasticsearch 的 ml.put_trained_model() 方法下载ELSER。 model_id 参数标识要下载的模型和版本(ELSER v2 适用于 Elasticsearch 8.11 及更高版本)。 input 字段是该模型所需的配置。
下载模型后,需要对其进行部署。 为此,使用 ml.start_trained_model_deployment() 方法,仅使用要部署的模型的标识符。 请注意,这是一个异步操作,因此该模型将在短时间内可供使用。
配置 ELSER 使用的最后一步是为其定义管道。 管道用于告诉 Elasticsearch 如何使用模型。 管道被赋予一个标识符和一个或多个要执行的处理任务。 上面创建的管道称为 elser-ingest-pipeline,具有单个推理任务,这意味着每次添加文档时,模型将在 input_field 上运行,并且输出将添加到 输出字段。 对于此示例,summary 字段用于生成嵌入,与上一章中的密集向量嵌入一样。 生成的嵌入将写入上一节中创建的 elser_embedding 稀疏向量字段。
为了方便调用此方法,请在 app.py 中的 Flask 应用程序中添加一个 deploy-elser 命令:
app.py
@app.cli.command()
def deploy_elser():"""Deploy the ELSER v2 model to Elasticsearch."""try:es.deploy_elser()except Exception as exc:print(f'Error: {exc}')else:print(f'ELSER model deployed.')
你现在可以使用以下命令在 Elasticsearch 服务上部署 ELSER:
(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ flask deploy-elser
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch','cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg','name': 'liuxgm.local','tagline': 'You Know, for Search','version': {'build_date': '2023-11-04T10:04:57.184859352Z','build_flavor': 'default','build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20','build_snapshot': False,'build_type': 'tar','lucene_version': '9.8.0','minimum_index_compatibility_version': '7.0.0','minimum_wire_compatibility_version': '7.17.0','number': '8.11.0'}}
ELSER model deployed.上面的命令的允许需要一段时间。等命令完成后,我们可以转到 Kibana 界面:

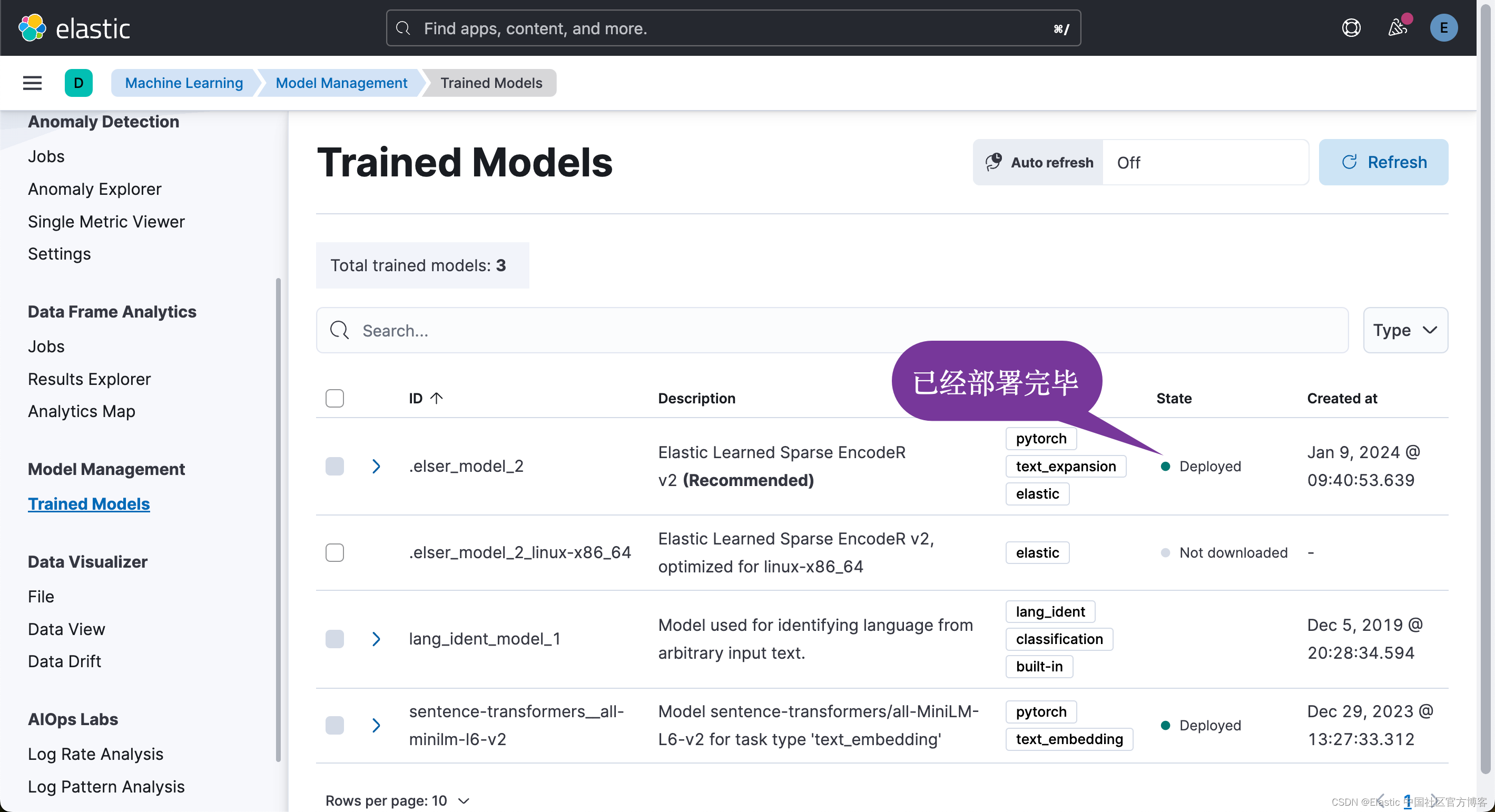
最后一个配置任务涉及将索引与管道链接,以便在该索引上插入文档时自动执行模型。 这是通过设置选项在索引配置上完成的。 以下是对 create_index() 方法的另一项更新,用于创建此链接:
search.py
class Search:# ...def create_index(self):self.es.indices.delete(index='my_documents', ignore_unavailable=True)self.es.indices.create(index='my_documents',mappings={'properties': {'embedding': {'type': 'dense_vector',},'elser_embedding': {'type': 'sparse_vector',},}},settings={'index': {'default_pipeline': 'elser-ingest-pipeline'}})
通过此更改,你现在可以重新生成索引并完全支持 ELSER 推理:
flask reindex(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ flask reindex
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch','cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg','name': 'liuxgm.local','tagline': 'You Know, for Search','version': {'build_date': '2023-11-04T10:04:57.184859352Z','build_flavor': 'default','build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20','build_snapshot': False,'build_type': 'tar','lucene_version': '9.8.0','minimum_index_compatibility_version': '7.0.0','minimum_wire_compatibility_version': '7.17.0','number': '8.11.0'}}
Index with 15 documents created in 59 milliseconds.运行完上面的命令后,我们可以在 Kibana 里进行查看:

从上面的图中我们可以看出来,有一个叫做 elser_embedding 的字段生成。它里面所含的值就是通过 text expansion 所生成的。
语义查询
现在索引配备了 ELSER 嵌入,可以更改 app.py 中的 handle_search() 函数来搜索这些嵌入。 目前,你将了解如何仅通过 ELSER 进行搜索,稍后将合并以前的搜索方法以创建组合解决方案。
要在搜索时使用 ELSER 推理,请使用 text_expansion 查询类型。 下面你可以看到带有此查询的更新后的 handle_search() 函数:
app.py
@app.post('/')
def handle_search():query = request.form.get('query', '')filters, parsed_query = extract_filters(query)from_ = request.form.get('from_', type=int, default=0)results = es.search(query={'text_expansion': {'elser_embedding': {'model_id': '.elser_model_2','model_text': parsed_query,}},},size=5,from_=from_,)return render_template('index.html', results=results['hits']['hits'],query=query, from_=from_,total=results['hits']['total']['value'])
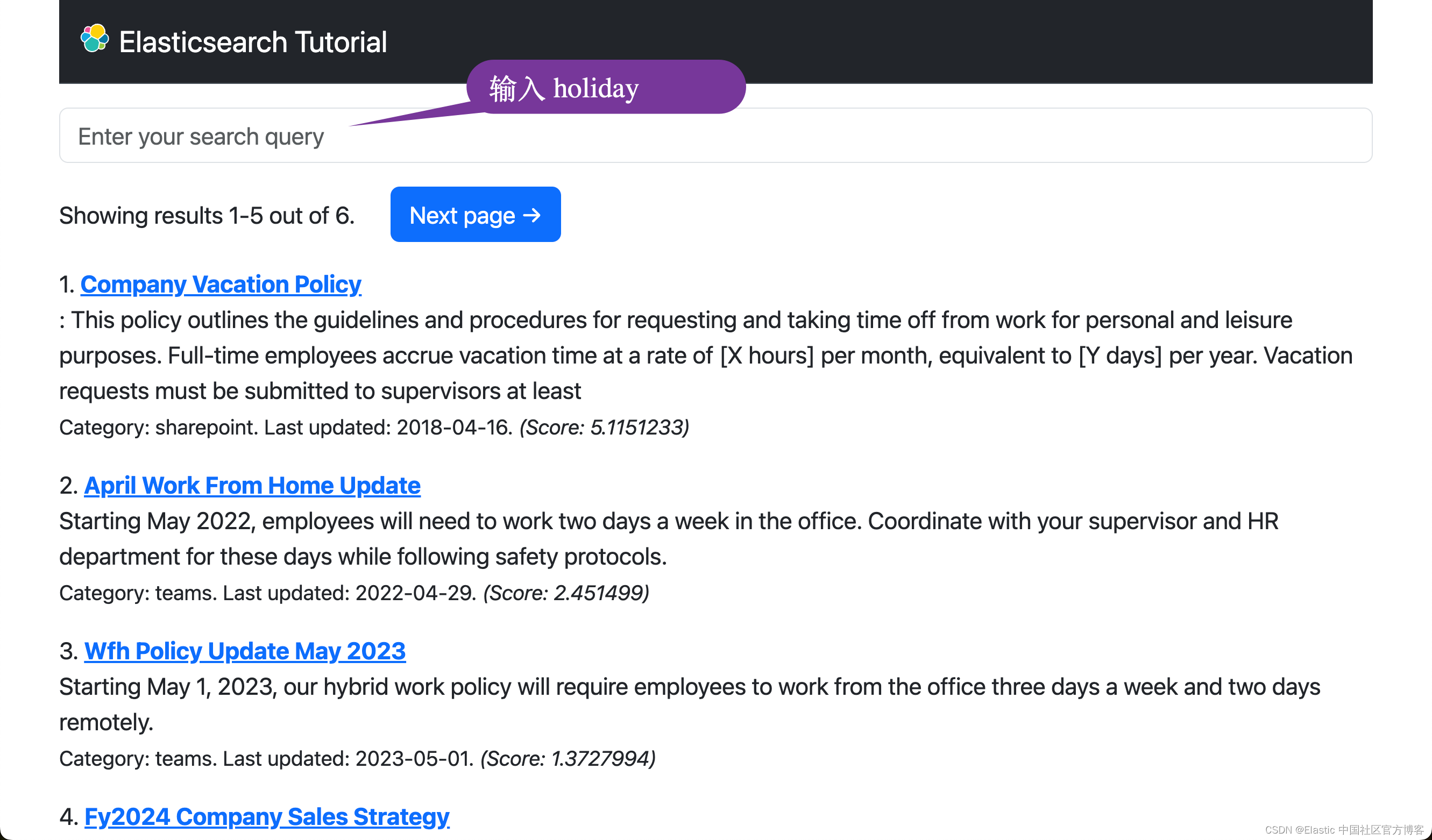
text_expansion 查询接收一个带有要搜索的字段名称的键。 在此键下,model_id 配置在搜索中使用哪个模型,model_text 定义要搜索的内容。 请注意,在这种情况下,无需为搜索文本生成嵌入,因为 Elasticsearch 管理模型并可以处理该问题。我们可以尝试如下的搜索:
在上面版本的handle_search()中,过滤器未被使用。 过滤器可以按照将其合并到全文搜索解决方案中的相同方式添加回来。 下面是更新的 handle_search() 函数,它将 text_expansion 查询移动到 bool.must 部分内,过滤器包含在 bool.filter 中。
app.py
@app.post('/')
def handle_search():query = request.form.get('query', '')filters, parsed_query = extract_filters(query)from_ = request.form.get('from_', type=int, default=0)results = es.search(query={'bool': {'must': [{'text_expansion': {'elser_embedding': {'model_id': '.elser_model_2','model_text': parsed_query,}},}],**filters,}},size=5,from_=from_,)return render_template('index.html', results=results['hits']['hits'],query=query, from_=from_,total=results['hits']['total']['value'])
花一些时间尝试不同的搜索。 你会注意到,与密集向量嵌入一样,当索引文档中没有出现确切的单词时,由 ELSER 模型驱动的搜索比全文搜索效果更好。
work from home category:sharepoint
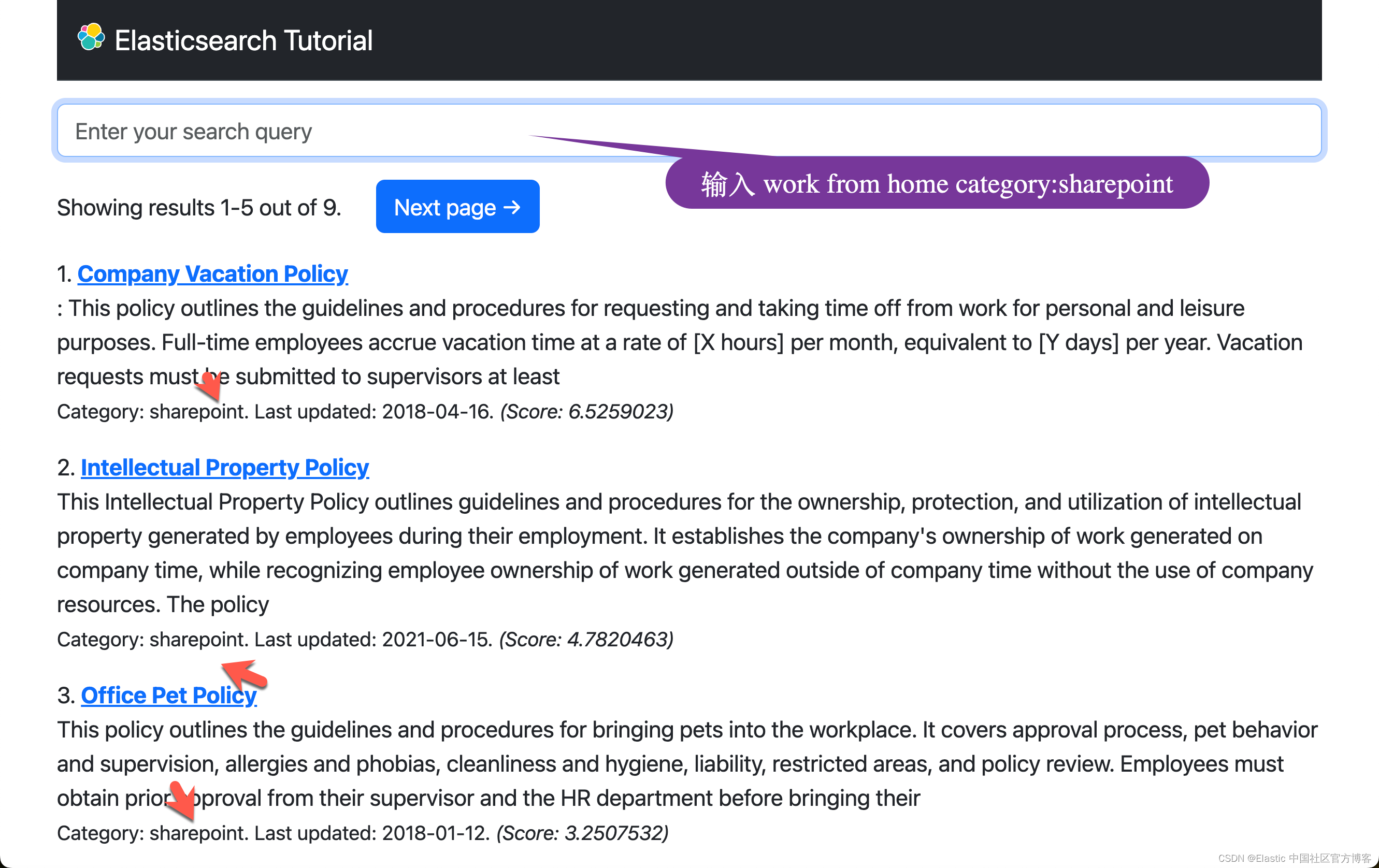
混合搜索:结合全文和 ELSER 结果
与上一节中的向量搜索一样,在本节中,你将学习如何使用倒数排名融合(RRF)算法组合来自全文和语义查询的最佳搜索结果。
子搜索简介
实现混合全文和密集向量搜索的解决方案是发送一个搜索请求,其中包括 query、knn 参数来请求两个搜索以及将它们合并到单个结果列表中的 rrf 参数。
当尝试执行相同操作来组合全文和稀疏向量搜索请求时,出现的复杂情况是两者都使用 query 参数。 为了能够提供需要与 RRF 算法结合的两个查询,需要包含两个查询参数,而实现这一点的解决方案是使用子搜索 (sub searches)来完成。
子搜索是一项目前处于技术预览版的功能。 因此,Python Elasticsearch 客户端本身并不支持它。 要解决此限制,可以更改 Search 类的 search() 方法以将搜索请求作为原始请求发送。 下面你可以看到一个新的但类似的实现,它使用客户端的 Perform_request() 方法发送原始请求:
search.py
class Search:# ...def search(self, **query_args):# sub_searches is not currently supported in the client, so we send# search requests as raw requestsif 'from_' in query_args:query_args['from'] = query_args['from_']del query_args['from_']return self.es.perform_request('GET',f'/my_documents/_search',body=json.dumps(query_args),headers={'Content-Type': 'application/json','Accept': 'application/json'},)
此实现不需要对应用程序进行任何更改,因为它在功能上是等效的。 唯一的区别是 search() 方法在发送请求之前验证所有参数,而 Perform_request() 是一个较低级别的方法,不执行任何验证。 无论客户端如何发送请求,服务器始终都会验证请求。
在此版本中,sub_searches 参数可用于发送多个搜索查询,如下所示:
results = es.search(sub_searches=[{'query': { ... }, # full-text search},{'query': { ... }, # semantic search},],'rank': {'rrf': {}, # combine sub-search results},size=5,from_=from_,)混合搜索实施
为了完成本节,让我们带回全文逻辑并将其与本章前面介绍的语义搜索查询相结合。
你可以在下面看到更新后的 handle_search() 端点:
app.py
@app.post('/')
def handle_search():query = request.form.get('query', '')filters, parsed_query = extract_filters(query)from_ = request.form.get('from_', type=int, default=0)if parsed_query:search_query = {'sub_searches': [{'query': {'bool': {'must': {'multi_match': {'query': parsed_query,'fields': ['name', 'summary', 'content'],}},**filters}}},{'query': {'bool': {'must': [{'text_expansion': {'elser_embedding': {'model_id': '.elser_model_2','model_text': parsed_query,}},}],**filters,}},},],'rank': {'rrf': {}},}else:search_query = {'query': {'bool': {'must': {'match_all': {}},**filters}}}results = es.search(**search_query,size=5,from_=from_,)return render_template('index.html', results=results['hits']['hits'],query=query, from_=from_,total=results['hits']['total']['value'])
你还记得,extract_filters() 函数查找用户在搜索提示中输入的类别过滤器,并将剩余部分作为 parsed_query 返回。 如果 parsed_query 为空,则意味着用户仅输入类别过滤器,在这种情况下,查询应该是简单的 match_all,并以所选类别作为过滤器。 这是在大条件的 else 部分中实现的。
当存在搜索查询时,如上一节所示,使用 sub_searches 选项来包含 multi_match 和 text_expansion 查询,而排名选项则要求将两个子搜索的结果合并到单个排名结果列表中。 为了完成查询,提供了 size 和 from_ 参数以维持对分页的支持。
我们可以尝试上面同样的搜索:
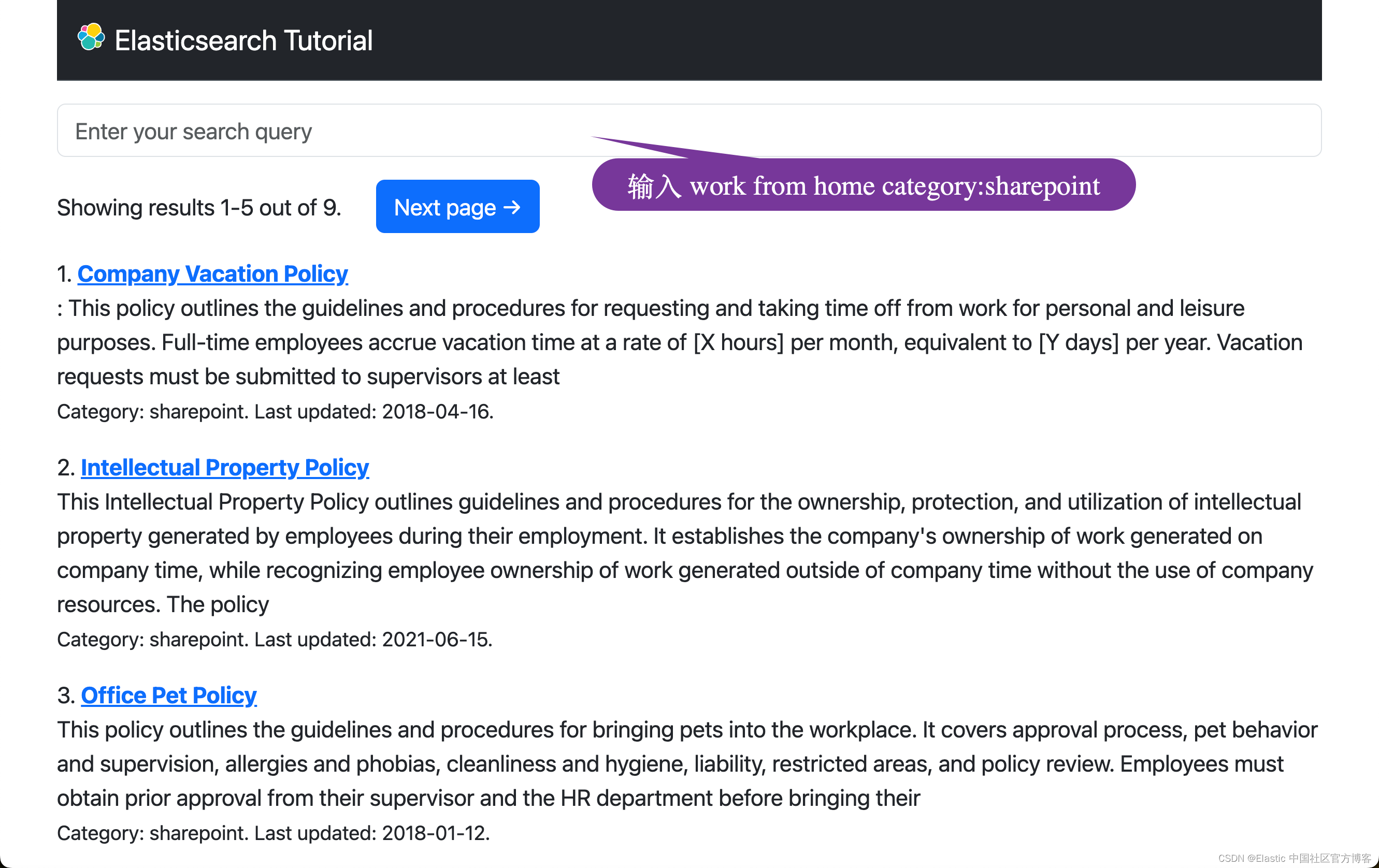
从上面的输出结果中,我们可以看出来它的搜索结果和之前的很相似,但是它融合了关键字搜索及语义搜索。在某些应用场合,它会更为精确。
我们可以在地址下载最后完整的代码:
git clone https://github.com/liu-xiao-guo/search-tutorial-3结论
恭喜你已完成搜索教程!
我们希望本教程为你提供了一个基础,你可以在此基础上开始使用 Elasticsearch 进行实验并创建你的搜索解决方案!