kafka环境搭建
kafka依赖java环境,如果没有则需要安装jdk
yum install java-1.8.0-openjdk* -y
1.下载安装kafka
kafka3.0版本后默认自带了zookeeper,3.0之前的版本需要单独再安装zookeeper,我使用的最新的3.6.1版本。
cd /usr/local
wget https://dlcdn.apache.org/kafka/3.6.1/kafka_2.12-3.6.1.tgz
tar -zxvf kafka_2.12-3.6.1.tgz
cd kafka_2.12-3.6.1.tgz
2.启动zookeeper
cd到kafka的安装根目录后,执行下面命令指令zookeeper.properties文件路径启动zookeeper,默认启动的zk服务使用内存是512m,可以修改zookeeper-server-start.sh脚本中参数调大使用堆内存
bin/zookeeper-server-start.sh config/zookeeper.properties
也可以通过指定-daemon以守护进程方式启动zookeeper,如果不指定关闭终端时zookeeper服务则会被杀死
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
#通过tail命令查看zookeeper实时日志
tail -f logs/zookeeper.out
启动完看到下面的日志表示启动成功了

停止zookeeper服务
bin/zookeeper-server-stop.sh
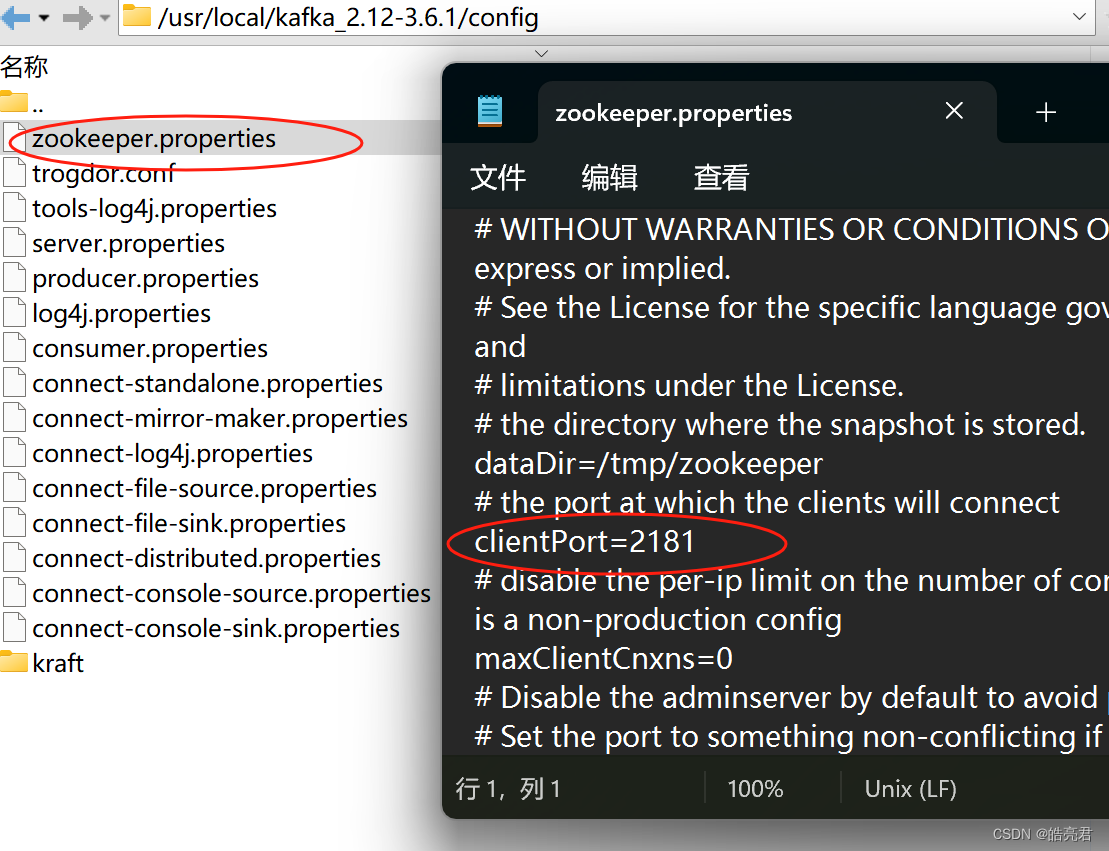
zk默认的端口是2181,可以修改zookeeper.properties里的clientPort字段改变zk监控的端口
可以再开一个终端启动zk客户端测试连接
bin/zookeeper-shell.sh 127.0.0.1:2181
执行ls查看根目录下的文件信息,默认只有zookeeper目录,由于我之前启动过kafka,所以这里会有kafka-server注册到zk中元数据信息
ls /

3.配置kafka
修改配置kafka配置文件,方便后面在idea中访问
vi config/server.properties
如果kafka需要被外部机器访问需要配置listeners和advertised.listeners字段,下图圈中的是我虚拟机的访问ip,如果不配置的话在笔记本上idea中访问会报错。
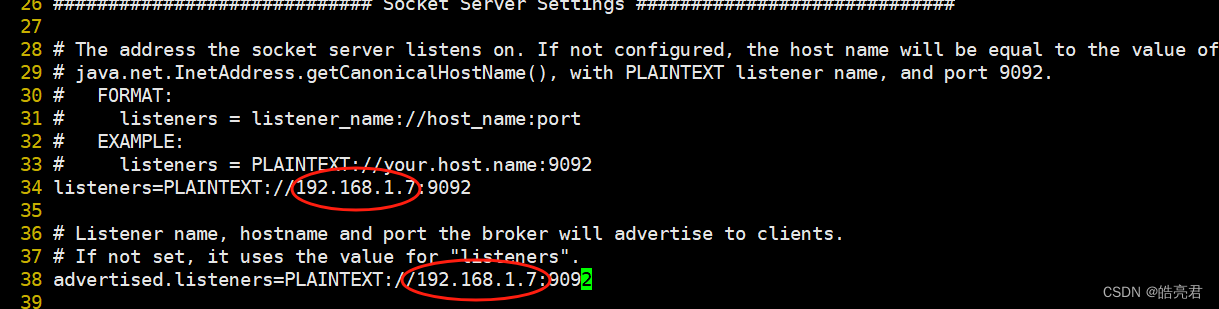
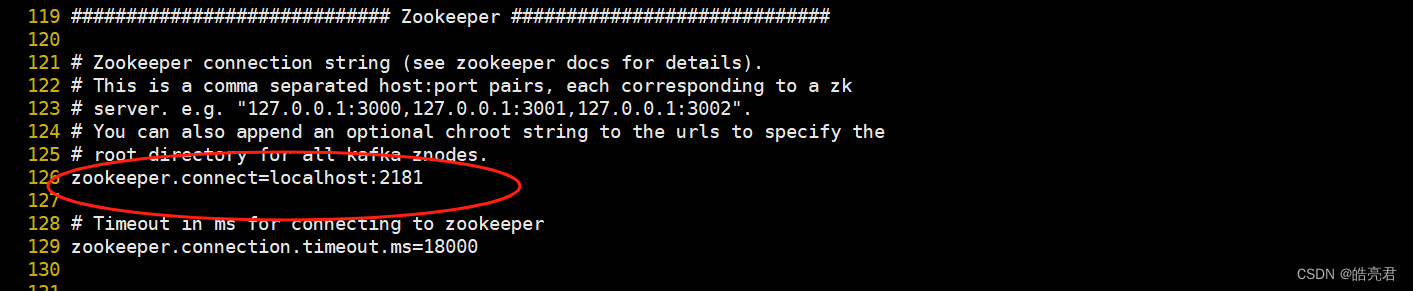
如果kafka和zookeeper不在同一台机器上面,需要修改zookeeper.connect字段
4.启动kafka
下面指定了kafka配置文件路径的方式启动kafka
bin/kafka-server-start.sh config/server.properties
也可以通过指定-daemon以守护进程方式启动kafka,如果不指定关闭终端时kafka服务则会被杀死
bin/kafka-server-start.sh -daemon config/server.properties
#指定了-daemon参数可以通过tail命令查看kafka实时日志
tail -f logs/server.log
看到下面的日志表示kafka启动成功

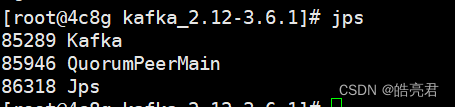
通过jps命令可以看到kafka和zookeeper两个java进程
停止kafka服务
bin/kafka-server-stop.sh
5.创建主题
通过kafka-topics.sh脚本可以对主题操作,由于我修改过server.properties监听地址为服务器的ip,所以不能使用localhost访问,只能用服务器ip访问
#bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic kafkatest
bin/kafka-topics.sh --create --bootstrap-server 192.168.1.7:9092 --replication-factor 1 --partitions 1 --topic kafkatest
- –bootstrap-server 指定kafka的server地址
- –replicator-factor 指定了副本因子(即副本数量); 表示该topic需要在不同的broker中保存几份,这里设置成1,表示在两个broker中保存两份Partitions分区数。
- –partitions 指定分区个数
- –topic 指定所要创建主题的名称,比如kafkatest
查看所有kafka主题信息
bin/kafka-topics.sh --list --bootstrap-server 192.168.1.7:9092
可以看到下面有刚刚创建的kafkatest主题

查看主题的详细信息
bin/kafka-topics.sh --describe --bootstrap-server 192.168.1.7:9092 --topic kafkatest

6.生产者发送消息
执行kafka-console-producer.sh命令给主题名称为kafkatest主题的发送消息
bin/kafka-console-producer.sh --broker-list 192.168.1.7:9092 --topic kafkatest
输入消息后按回车键就会发送消息

7.消费者消费消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.7:9092 --topic=kafkatest --from-beginning
- –from-beginning 参数从主题头开始消费消息,不指令只会消费实时消息
可以看到下图有刚才生产者发送的三条消息

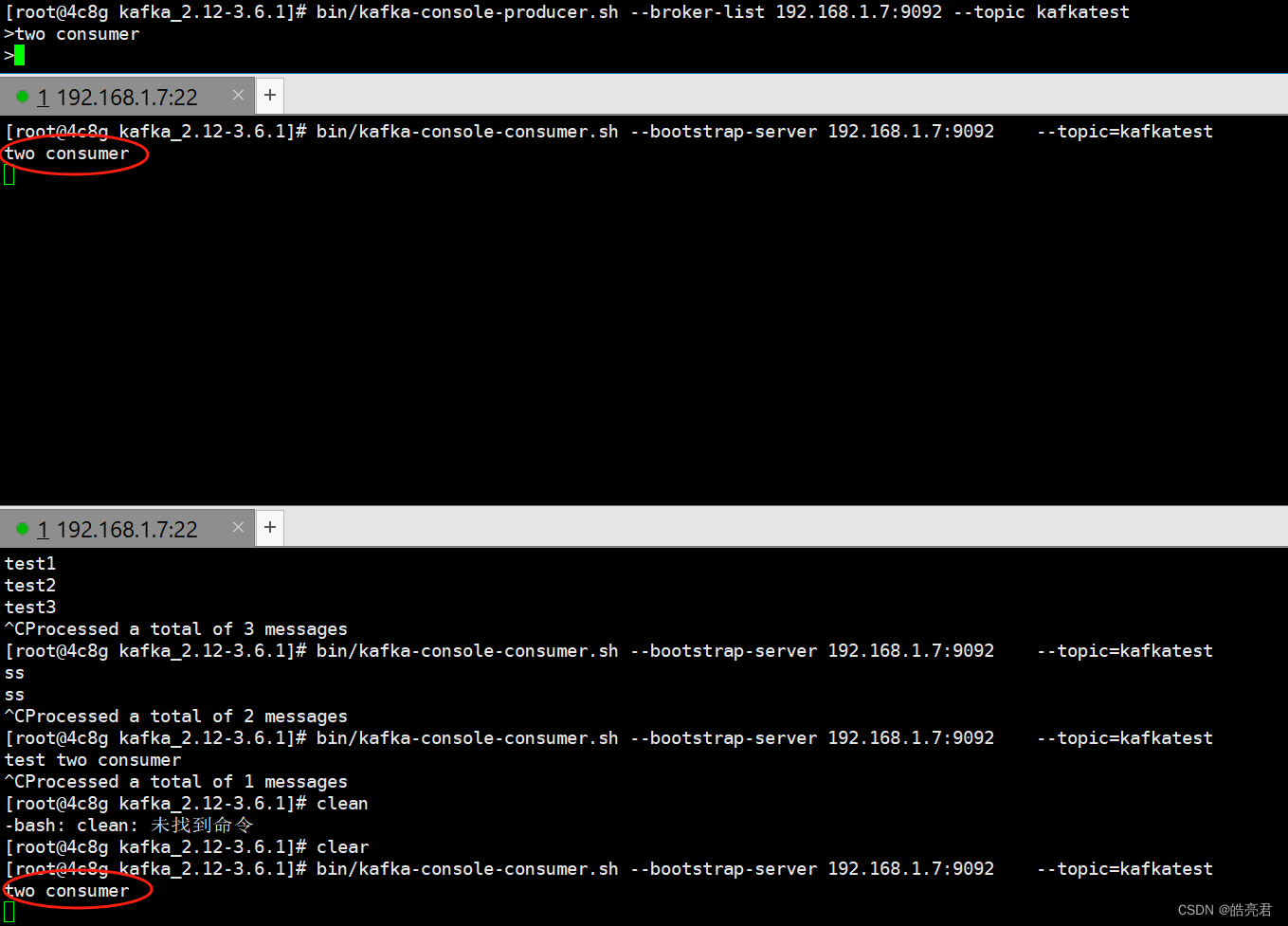
默认所有kafka消费者都会消费kafka生产者发送到主题的消息(有兴趣的可以再开一个终端启动kafka消费者,然后再用生产者发送消息,可以看到消息被两个消费者消费了,效果如下图)
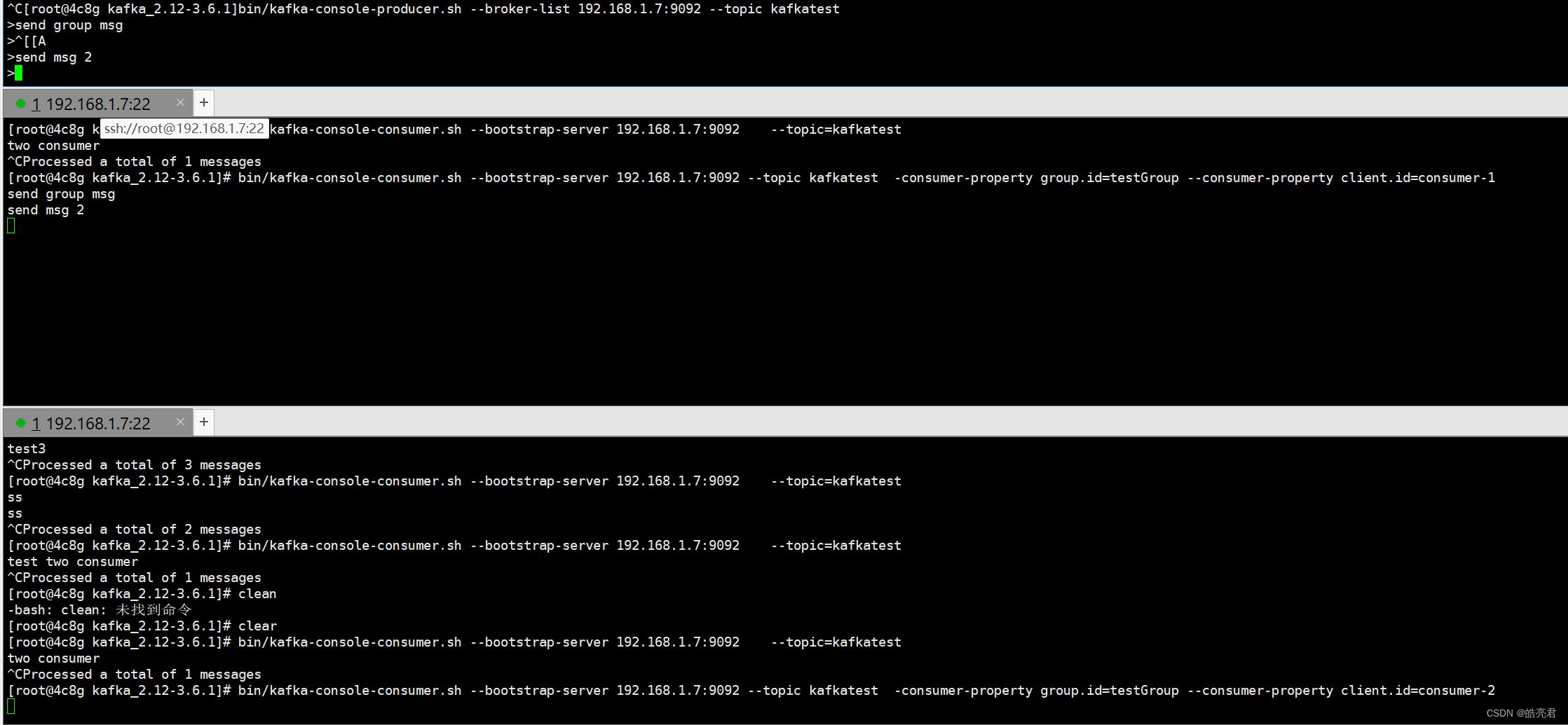
可以指定kafka消费者的组Id让在同一组的客户端只有一个实例能消费消息。
bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.7:9092 --topic kafkatest -consumer-property group.id=testGroup --consumer-property client.id=consumer-1
- group.id 用于指定消费者分组
- client.id 用于指定消费者在组中的客户端Id
再另外一个终端启动上面的命令,需要把client.id改成consumer-2
然后再用生产者发送消息,可以看到下图只有一个消费者在消费消息
在SpringBoot中使用
1.引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency>
2.application.yml
server:port: 8035spring:kafka:bootstrap-servers: 192.168.1.7:9092 #kafka server的地址producer:batch-size: 16384 #批量大小acks: -1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)retries: 10 # 消息发送重试次数buffer-memory: 33554432key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerproperties:linger:ms: 2000 #提交延迟consumer:group-id: testGroup #默认的消费组IDenable-auto-commit: true #是否自动提交offsetauto-commit-interval: 2000 #提交offset延时auto-offset-reset: latestmax-poll-records: 100 #单次拉取消息的最大条数key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproperties:session:timeout:ms: 10000 # 消费会话超时时间(超过这个时间 consumer 没有发送心跳,就会触发 rebalance 操作)request:timeout:ms: 30000 # 消费请求的超时时间listener:#type: batch #设置批量消费,注释掉则是单次消费missing-topics-fatal: false # consumer listener topics 不存在时,启动项目就会报错concurrency: 10 # 默认消费者线程数 也可以在@KafkaListener注解内配置concurrency字段值
3.创建主题
有两种创建主题的方式
通过TopicBuilder+ @Bean自动创建主题
@Configuration
public class KafkaConfig {public static final String DEFALUT_TOPIC = "autoTopic";@Beanpublic NewTopic newTopic() {//如果存在则不会创建, 参数:主题名称、分区数、副本数return TopicBuilder.name(DEFALUT_TOPIC ).partitions(1).replicas(1).build();}}
通过AdminClient 手动创建主题
@Configuration
public class KafkaConfig {@Beanpublic AdminClient adminClient(@Value("${spring.kafka.bootstrap-servers}") String bootstrapServers) {Properties prop = new Properties();prop.put("bootstrap.servers",bootstrapServers);return AdminClient.create(prop);}
}
web接口,下面定义了两个接口分别用于创建主题和查看所有主题
@Slf4j
@RestController
public class KafkaAdminController {@Resourceprivate AdminClient adminClient;/*** 创建主题*/@GetMapping("/create/{topicName}")public String createTopic(@PathVariable String topicName) throws Exception {//需要判主题是否已存在,已存在再创建会报错if (getTopicSet().contains(topicName)) {return "topicExists ";}// 创建主题 参数:主题名称、分区数、副本数CreateTopicsResult result = adminClient.createTopics(Collections.singletonList(new NewTopic(topicName, 1, (short) 1)));result.all().get();return "success";}/*** 查看所有主题*/@GetMapping("/listTopic")public String listTopic() throws Exception {Set<String> set = getTopicSet();return String.format("topics[%s]", getTopicSet().stream().collect(Collectors.joining(",")));}public Set<String> getTopicSet() throws Exception {ListTopicsResult listTopicsResult = adminClient.listTopics();KafkaFuture<Set<String>> future = listTopicsResult.names();return future.get();}}
启动项目后调用创建主题接口创建名称为newTopic的主题
用浏览器访问http://localhost:8035/create/newTopic 两次可以看到返回了主题已存在的错误信息

用浏览器访问http://localhost:8035/listTopic查看所有主题,可以看到通过TopicBuilder和AdminClient创建的主题都存在。其它的是之前测试造出来的脏数据

4.发送消息
4.1.正常消息
@RestController
public class KafkaProducerController {@Resourceprivate KafkaTemplate<String, Object> kafkaTemplate;/*** 正常消息发送*/@GetMapping("/send/{msg}")public String sendMessage(@PathVariable String msg) {log.info("sendMsg=" + msg);kafkaTemplate.send(KafkaConfig.DEFALUT_TOPIC, msg);return "success";}
4.2.带回调函数的消息
/*** 带回调的消息发送*/@GetMapping("/sendCallback/{msg}")public String sendCallbackMessage(@PathVariable String msg) {kafkaTemplate.send(KafkaConfig.DEFALUT_TOPIC, msg).addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable throwable) {log.error("send msg to kafka error:{}", throwable.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> result) {log.info("send msg to kafka success topic={},partition={},msg={}", result.getRecordMetadata().topic(), result.getRecordMetadata().partition(),result.getProducerRecord().value());}});return "success";}
4.3.全局监听回调函数配置
4.2.使用的ListenableFutureCallback和下文使用的ProducerListener两种监听的回调函数都会执行
@Slf4j
@Configuration
public class KafkaConfig {@ResourceProducerFactory producerFactory;@Beanpublic KafkaTemplate<String, Object> kafkaTemplate() {KafkaTemplate<String, Object> kafkaTemplate = new KafkaTemplate<String, Object>(producerFactory);kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {@Overridepublic void onSuccess(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata) {log.info("send susscess , data= {}", producerRecord.toString());}@Overridepublic void onError(ProducerRecord<String, Object> producerRecord, Exception exception) {//当消息发送失败可以拿到消息存在缓存或数据中 定时重试发送log.error("send fail , data{}", producerRecord.toString());}});return kafkaTemplate;}
}
分布用浏览器访问下面两个地址发送消息
http://localhost:8035/send/testmsg1
http://localhost:8035/sendCallback/testmsg2

由上图可以看到sendCallback接口两个监听器的回调函数都执行了。
5.消费消息
5.1.单次消费
通过@KafkaListener配置消费者信息
- topics 订阅的主题,可以是多个
- concurrency 线程数,如果不配置,则会使用用配置文件中的全局参数spring.kafka.listener.concurrency字段值,都不配置默认是单线程
@Slf4j
@Component
public class KafkaConsumer {/*** 监听消息*/@KafkaListener(topics = {KafkaConfig.DEFALUT_TOPIC}, concurrency = "5")public void onMessage(ConsumerRecord<String, Object> record) {log.info("onMessage msg={}",record.value());}}
5.2.批量消费消息
需要注释掉5.1的单次消息的代码,要不然会报错
批量消费需要在配置文件设置spring.kafka.listener.type=batch,可以通过max-poll-records指定最大条数
spring:kafka:consumer:max-poll-records: 100 #单次拉取消息的最大条数listener:type: batch #设置批量消费,注释掉则是单次消费 /*** 同一主题批量消费groupId不能和单次消费的一样*/@KafkaListener(topics = {KafkaConfig.DEFALUT_TOPIC}, errorHandler = KafkaConstant.CONSUMER_ERROR_HANDLER_NAME,groupId = "batchGroup")public void onBatchMessage(List<ConsumerRecord<String, Object>> records) throws Exception {log.info("batch size={}", records.size());for (ConsumerRecord<String, Object> record : records) {log.info("onBatchMessage msg={}", record.value());}}
用生产者发送多条消息,由下图可以看到消费者同时消费了6条消息

5.3.配置消费异常监听
@Slf4j
@Configuration
public class KafkaConfig {public static final String CONSUMER_LISTENER_ERROR_HANDLER_NAME ="consumerAwareListenerErrorHandler";@Bean(CONSUMER_LISTENER_ERROR_HANDLER_NAME)public ConsumerAwareListenerErrorHandler consumerAwareListenerErrorHandler() {return new ConsumerAwareListenerErrorHandler() {@Overridepublic Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) {log.error("consumer fail:{}" ,exception.getMessage());return null;}};}}
在@KafkaListener注解里通过errorHandler字段指定消费异常监听器的Bean名称
@KafkaListener(topics = {KafkaConfig.DEFALUT_TOPIC}, errorHandler = KafkaConfig.CONSUMER_LISTENER_ERROR_HANDLER_NAME,groupId = "batchGroup")public void onBatchMessage(List<ConsumerRecord<String, Object>> records) throws Exception {log.info("batch size={}", records.size());for (ConsumerRecord<String, Object> record : records) {log.info("onBatchMessage msg={}", record.value());}//模拟异常throw new Exception("test errorHandler");}
使用生产者发送消息,可以看到控制台打印了消费异常监听器里的日志

项目配套代码
gitee代码地址
创作不易,要是觉得我写的对你有点帮助的话,麻烦在gitee上帮我点下 Star
【SpringBoot框架篇】其它文章如下,后续会继续更新。
- 1.搭建第一个springboot项目
- 2.Thymeleaf模板引擎实战
- 3.优化代码,让代码更简洁高效
- 4.集成jta-atomikos实现分布式事务
- 5.分布式锁的实现方式
- 6.docker部署,并挂载配置文件到宿主机上面
- 7.项目发布到生产环境
- 8.搭建自己的spring-boot-starter
- 9.dubbo入门实战
- 10.API接口限流实战
- 11.Spring Data Jpa实战
- 12.使用druid的monitor工具查看sql执行性能
- 13.使用springboot admin对springboot应用进行监控
- 14.mybatis-plus实战
- 15.使用shiro对web应用进行权限认证
- 16.security整合jwt实现对前后端分离的项目进行权限认证
- 17.使用swagger2生成RESTful风格的接口文档
- 18.使用Netty加websocket实现在线聊天功能
- 19.使用spring-session加redis来实现session共享
- 20.自定义@Configuration配置类启用开关
- 21.对springboot框架编译后的jar文件瘦身
- 22.集成RocketMQ实现消息发布和订阅
- 23.集成smart-doc插件零侵入自动生成RESTful格式API文档
- 24.集成FastDFS实现文件的分布式存储
- 25.集成Minio实现文件的私有化对象存储
- 26.集成spring-boot-starter-validation对接口参数校验
- 27.集成mail实现邮件推送带网页样式的消息
- 28.使用JdbcTemplate操作数据库
- 29.Jpa+vue实现单模型的低代码平台
- 30.使用sharding-jdbc实现读写分离和分库分表
- 31.基于分布式锁或xxx-job实现分布式任务调度
- 32.基于注解+redis实现表单防重复提交
- 33.优雅集成i18n实现国际化信息返回
- 34.使用Spring Retry完成任务的重试
- 35.kafka环境搭建和收发消息