Lecture #10_ Sorting & Aggregation Algorithms
Query Plan
数据库系统会将 SQL 编译成查询计划。查询计划是一棵运算符树。
Sorting
DBMS 需要对数据进行排序,因为根据关系模型,表中的tuple没有特定的顺序。排序使用 ORDER BY、GROUP BY、JOIN 和 DISTINCT 操作符。如果需要排序的数据适合内存,那么 DBMS 可以使用标准排序算法(如快排)。如果数据不适合在内存中进行排序,那么 DBMS 就需要使用外部排序,这种排序可以根据需要溢出到磁盘,并且优先选择顺序 I/O,而不是随机 I/O。
如果查询包含一个带 LIMIT 的 ORDER BY,那么 DBMS 只需扫描一次数据就能找到前 N 个元素。这就是 top-n 堆排序。堆排序的理想情况是前 N 个元素都在内存中,这样 DBMS 只需在扫描数据时维护一个内存中的优先队列即可。
外部合并排序是对大到内存无法容纳的数据进行排序的标准算法。这是一种 "分而治之 "的排序算法,它将数据分割然后分别进行排序。
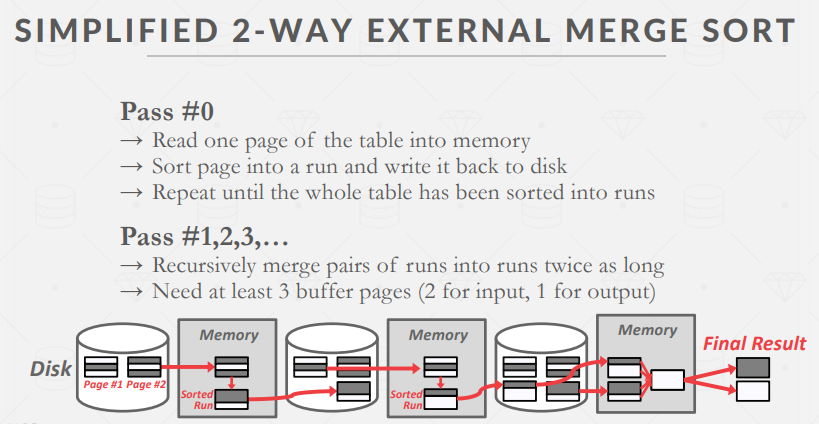
外部合并排序的一种优化方法是在后台预取下一次运行,并在系统处理当前运行时将其存储在第二个缓冲区中。这样可以持续利用磁盘,减少每一步 I/O 请求的等待时间。
对于 DBMS 来说,使用现有的 B+tree 索引辅助排序有时比使用外部合并排序算法更有优势。特别是,如果索引是聚簇索引,DBMS 就可以直接遍历 B+tree 索引。由于索引是聚类的,数据将以正确的顺序存储,因此 I/O 访问将是顺序的。
Aggregations
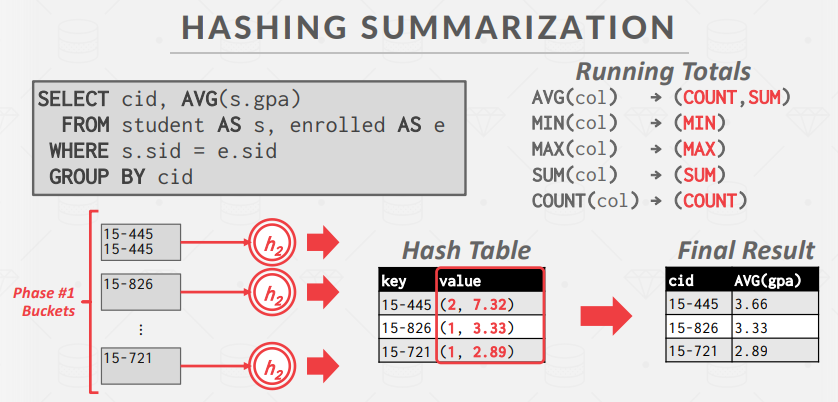
实现聚合有两种方法:排序和散列。
排序:DBMS 首先根据 GROUP BY 键对图元进行排序。如果所有数据都在缓冲池中(如 quicksort),可以使用内存内排序算法;如果数据大小超出内存,可以使用外部合并排序算法。然后,DBMS 会对排序后的数据执行顺序扫描,以计算聚合。运算符的输出将按键排序。在执行排序聚合时,必须对查询操作进行排序,以最大限度地提高效率。 例如,如果查询需要过滤,最好先执行过滤,然后对过滤后的数据进行排序,以减少需要排序的数据量。
哈希:
- Partition:使用哈希函数 h1,根据目标哈希键将tuple分组到磁盘上的分区。这将把所有匹配的元组放入同一个bucket。假设共有 B 个缓冲区,我们将有 B-1 个输出缓冲区和 1 个输入缓冲区。如果任何分区已满,数据库管理系统就会将其溢出到磁盘。
- ReHash:对于磁盘上的每个分区,将其页面读入内存,并根据第二个哈希函数 h2 建立一个内存哈希表。然后遍历哈希表中的每个桶,将匹配的tuple集中起来计算聚合。假设每个分区都适合内存。
Lecture #11_ Joins Algorithms
Joins
重点讨论用于合并两张表的内部等值连接算法。等值连接算法可以连接键值相等的表。
对于在连接属性上匹配的元组 r∈R 和元组 s∈S ,连接运算符会将 r 和 s 连接成一个新的输出元组。
实际上,连接算子生成的输出元组内容各不相同。这取决于 DBMS 的查询处理模型、存储模型和查询本身。对于连接运算符输出的内容有多种处理方法:
- Data(early materialization):将外层表和内层表中的属性值复制到中间结果表中的元组中,而中间结果表是专门为该算子准备的。这种方法的优点是,查询计划中的未来算子无需返回原来的表中去获取更多数据。缺点是需要更多内存来实例化整个元组。DBMS 还可以进行额外的计算,省略查询中以后不需要的属性,从而进一步优化这种方法。
- Record ID(late materialization):DBMS只复制连接键和匹配元组的记录 ID。这种方法非常适合列存储,因为 DBMS 不会复制查询不需要的数据。
连接算法的cost主要指磁盘I/O,且只考虑计算join时的 I/O,而不考虑输出结果时产生的 I/O。这是因为输出成本取决于数据,而且任何连接算法的输出都是相同的。
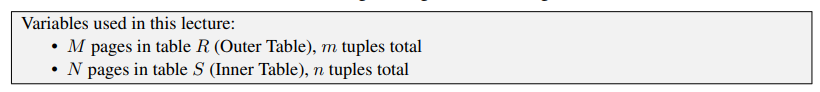
Nested Loop Join
这种连接算法由两个嵌套的 for 循环组成,这两个 for 循环遍历两个表中的tuple,并对每个tuple进行配对比较。外层 for 循环中的表称为外层表,内层 for 循环中的表称为内层表。
DBMS 总是希望使用较少tuple或者page的表作为外层表,还希望在内存中缓冲尽可能多的外层表。它还可以尝试利用索引来查找内表中的匹配项。
- Naive Nested Loop Join
- 朴素方法;
- Cost: M + (m × N)
- Block Nested Loop Join
- 对外部表中的每个数据块,从内部表中获取每个数据块,然后比较这两个数据块中的所有元组;
- Cost: M + ((# of blocks in R) × N)
- 如果 DBMS 有 B 个缓冲区可用来计算join,那么它可以使用 B - 2 个缓冲区来扫描外表,使用一个缓冲区扫描内表,并使用一个缓冲区存储连接的输出结果;
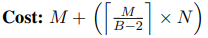
- Index Nested Loop Join
- 如果数据库已经为其中一个表建立了关于join key的索引,就可以利用它来加快比较速度。DBMS 可以使用现有索引或为连接操作建立临时索引;
- 外层表将是没有索引的表,内表是有索引的表;
- 假设每个索引探针的cost是每个元组的某个恒定值 C;
- Cost: M + (m × C)
Sort-Merge Join
根据两个表的连接键对两个表进行排序。DBMS 可以使用外部合并排序算法来实现这一点。
这种算法的最坏情况是两个表中所有tuple的连接属性都包含相同的值,而这在实际数据库中是不太可能发生的。在这种情况下,合并的成本将是 M × N。不过在大多数情况下,键大多是唯一的,因此合并成本大约是 M + N。
假设 DBMS 有 B 个缓冲区可用。
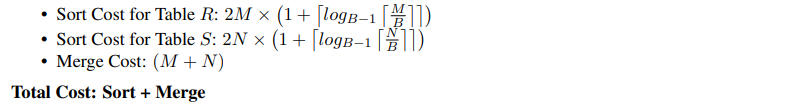
Hash Join
使用散列表根据连接属性将tuple分割成较小的块。这减少了 DBMS 为计算连接而需要对每个tuple执行的比较次数。hash join只能用于完整join key的等值连接。
如果元组 r∈R 和元组 s∈S 满足连接条件,那么它们的连接属性值相同。如果该值散列为某个值 i,则 R 元组必须位于数据桶 ri 中,而 S 元组必须位于数据桶 si 中。因此,只需将数据桶 ri 中的 R 元组与数据桶 si 中的 S 元组进行比较即可。
- Basic Hash Join
- 如果 DBMS 知道外层表的大小,则连接可以使用静态哈希表。如果数据库管理系统不知道外层表的大小,那么连接就必须使用动态哈希表或允许溢出页面;
- 探测阶段的一种优化方法是使用 Bloom 过滤器。这是一种概率数据结构,可放入 CPU 缓存中,并以肯定为 “否” 或可能为 “是” 来回答 “键 x 是否在哈希表中” 的问题。它可以防止磁盘读取不会导致匹配的数据,从而减少磁盘 I/O;
- Grace Hash Join / Partitioned Hash Join
- 当主内存无法容纳这些表时,数据库管理系统就必须从磁盘读取或写入表,从而导致性能低下。Grace Hash Join 是basic的扩展,它将内表也散列成分区,并将这些分区写入分区表中。
Conclusion

Lecture #12_ Query Processing I.md
Query Plan
DBMS 将 SQL 语句转换为查询计划。查询计划中的算子以树状排列,数据从树叶流向树根。树中根节点的输出就是查询结果。算子通常是二进制的(1-2 个子节点)。同一查询计划可以通过多种方式执行。
Processing Models
DBMS 处理模型定义了系统如何执行查询计划。它规定了查询计划的评估方向以及算子之间沿途传递的数据类型。
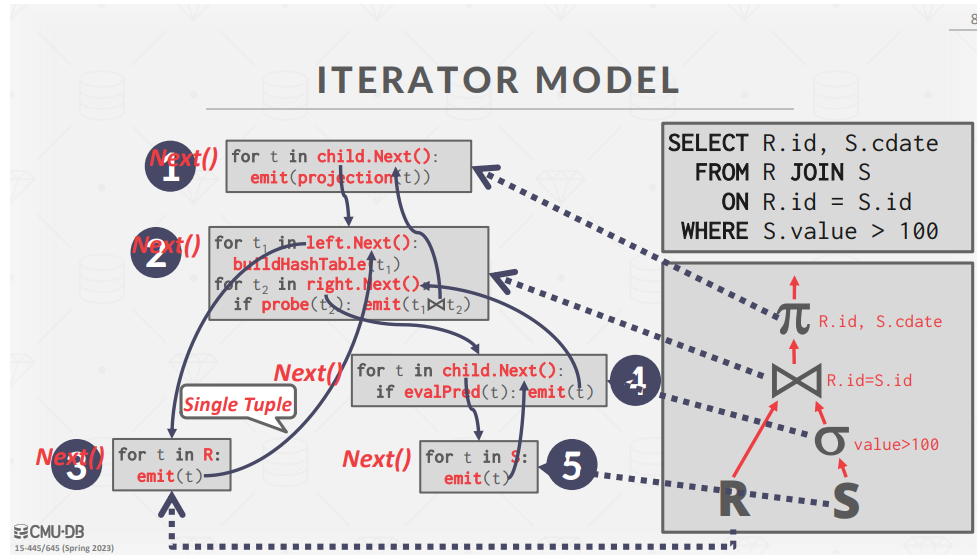
- Iterator Model
- 迭代器模型也称为火山模型或管道模型,是最常见的处理模型,几乎所有(基于行的)数据库管理系统都使用这种模型;
- 迭代器模型的工作原理是为数据库中的每个算子实现一个 Next 函数。查询计划中的每个节点都会对其子节点调用 Next,直到到达叶节点,叶节点开始向其父节点发送tuple进行处理。然后,在检索下一个tuple之前,每个tuple都会在计划中尽可能向上处理。这在基于磁盘的系统中非常有用,因为它允许我们在访问下一个tuple或页面之前,充分利用内存中的每个tuple。
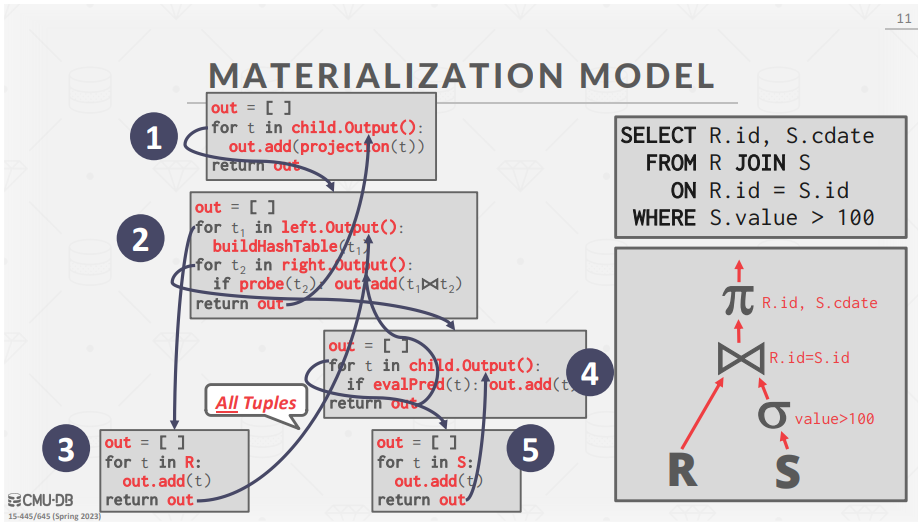
- Materialization Model
- 物化模型是迭代器模型的一种特殊化,其中每个算子一次性处理其输入,然后一次性输出。每个算子每次都会返回其所有的tuple,而不是使用一个返回单个tuple的Next函数。为避免扫描过多的tuple,DBMS可以向下传播后续需要多少tuple(如 LIMIT)。 算子将其输出 "具体化 "为一个结果。输出可以是整个tuple(NSM),也可以是列的子集(DSM);
- 更适合 OLTP,因为查询通常一次只访问少量图元。因此,检索图元的函数调用较少。物化模型不适合具有大量中间结果的 OLAP 查询,因为 DBMS 可能需要将结果溢出到磁盘;
- Vectorized / Batch Model
- 与迭代器模型一样,矢量化模型中的每个算子都实现了一个 Next 函数。不过,每个算子发出的是a batch of data(即向量),而不是单个tuple;
- 适合需要扫描大量tuple的 OLAP 查询,因为调用 Next 函数的次数较少;
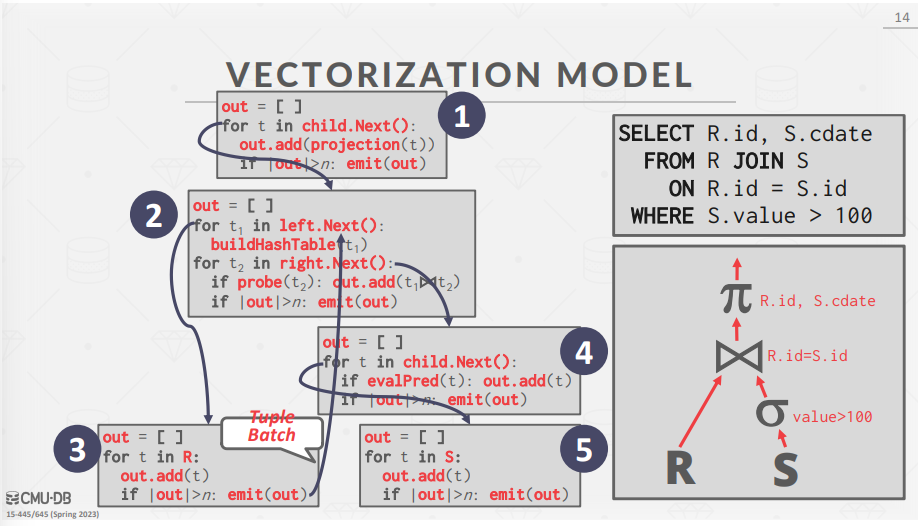

Access Methods
访问方法是指 DBMS 如何访问表中存储的数据。一般来说,访问模型有两种方法:要么从表中读取数据,要么通过顺序扫描从索引中读取数据。
- Sequential Scan
- 顺序扫描算子遍历表中的每一页,并从缓冲池中检索。当扫描遍历每一页上的所有元组时,它会评估以决定是否将元组发送给下一个运算符;
- 顺序扫描优化:
- 预取几个page避免频繁阻塞存储I/O;
- 将从磁盘获取的page存储在内存中而不是缓冲池,避免sequential flooding;
- 多线程并行扫描;
- Late Materialization:DSM DBMS 将tuple拼接延迟,每个算子将所需的最少信息传递给下一个算子(如Record ID,record在列中的偏移量)。这只在列存储系统中有用;
- 使用聚类索引指定的顺序将tuple存储在堆页面中;
- 近似查询(有损数据跳过):在整个表的抽样子集上执行查询,以产生近似结果。这通常用于在允许低误差的情况下计算聚合,从而得出近似准确的答案;
- Zone Map(无损数据跳过):为页面中的每个元组属性预先计算聚合,然后数据库管理系统可以通过先检查页面的 Zone Map 来决定是否需要访问该页面。每个页面的 Zone Map 都存储在不同的页面中,每个 Zone Map 页面通常有多个条目。因此,可以减少顺序扫描中检查的页面总数;

- Index Scan
- 在索引扫描中,DBMS会选择一个索引来查找查询所需的tuple;

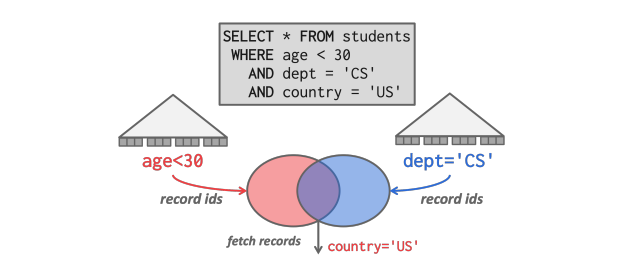
- 更先进的 DBMS 支持多索引扫描。当查询使用多个索引时,DBMS会通过每个匹配索引计算 record ID 集,根据查询谓词组合这些集,然后检索记录并应用可能保留的任何谓词。数据库管理系统可以使用位图、哈希表或 Bloom 过滤器通过集合交集计算 record ID。
Modification Queries
修改数据库的算子(INSERT、UPDATE、DELETE)负责检查约束和更新索引。对于 UPDATE/DELETE,子算子传递目标tuple的record ID,并且必须跟踪以前查看过的tuple。
- Halloween Problem
- 万圣节问题是一种异常:更新操作会改变tuple的物理位置,导致扫描多次访问该tuple;
- 解决这个问题的办法是跟踪每次查询修改的record ID。
Expression Evaluation
DBMS 将 WHERE 子句表示为expression tree。树中的节点代表不同的表达式类型。
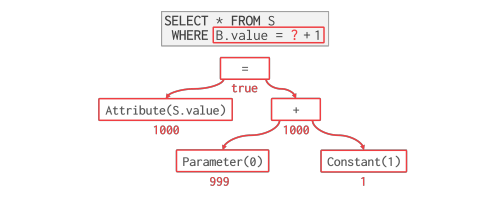
DBMS 会维护一个上下文句柄,其中包含执行的元数据,如当前元组、参数和表模式。然后,DBMS 会遍历表达式树,以评估其运算符并生成结果。
这种方式的速度很慢,因为 DBMS 必须遍历整个树,并确定对每个算子采取的正确操作。更好的方法是直接评估表达式(JIT)。根据内部成本模型,DBMS将决定是否采用代码生成来加速查询。
Lecture #13_ Query Execution II
Background
并行执行为 DBMS 带来了许多关键优势。
DBMS 支持两种类型的并行:查询间并行和查询内并行。
Parallel vs Distributed Databases
在并行和分布式系统中,数据库被分散到多个 "资源 "中,以提高并行性。这些资源可以是计算资源(如 CPU 内核、CPU 插槽、GPU、附加机器)或存储资源(如磁盘、内存)。
- Parallel DBMS:资源或节点在物理上彼此靠近。这些节点通过高速互连进行通信。它假设资源之间的通信不仅快速,而且便宜可靠;
- Distributed DBMS:资源之间可能相距甚远,因此,资源使用较慢的互连(通常通过公共网络)进行通信。节点之间的通信成本较高,而且故障不容忽视;
Process Models
DBMS 流程模型定义了系统如何支持来自多用户应用程序/环境的并发请求。DBMS 由一个或多个worker组成,他们负责代表客户执行任务并返回结果。应用程序可能会同时发送一个大型请求或多个请求,这些请求必须在不同的worker之间进行分配。
- Process per Worker
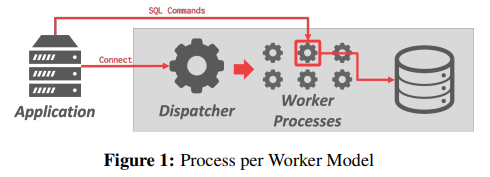
- 这种模式依赖于共享内存来维护全局数据结构,或者依赖于消息传递,而消息传递的开销更大;
- 优势在于进程崩溃不会破坏整个系统,因为每个worker都在自己的OS进程中运行;
- 问题:不同进程中的多个workers对同一页面进行多次复制。最大化内存使用率的解决方案是为全局数据结构使用共享内存,这样不同进程中运行的worker就可以共享这些数据结构;
- Thread per Worker
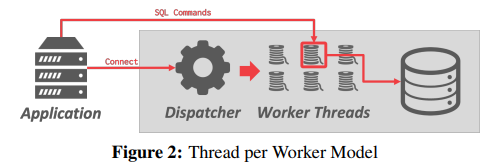
- 每个数据库系统只有一个带有多个工作线程的进程,而不是由不同的进程执行不同的任务。在这种环境下,DBMS 可以完全控制任务和线程,自己管理调度。多线程模型可以使用或不使用调度线程;
- 每次上下文切换的开销较少;无需维护共享模型。不过,线程崩溃有可能导致整个数据库进程瘫痪。此外,并不一定意味着 DBMS 支持查询内并行;
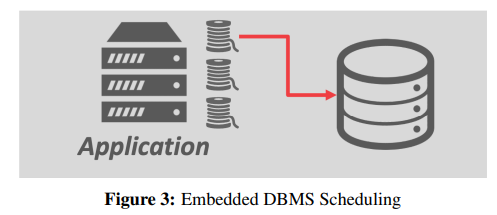
- Embedded DBMS
- 在应用程序的同一地址空间中运行系统,而不是在C/S模式中数据库独立于应用程序。在这种情况下,应用程序将设置在数据库系统上运行的线程和任务。应用程序本身主要负责调度;
Inter-Query Parallelism
在查询间并行中,数据库管理系统会同时执行不同的查询。
Intra-Query parallelism
在查询内并行中,数据库管理系统并行执行单个查询的操作。这可减少长时间运行查询的延迟。
可以从生产者/消费者模式的角度来考虑。
每个算子既是数据的生产者,也是其下级算子的数据消费者。 每个关系算子都有并行算法。DBMS 可以让多个线程访问集中式数据结构,也可以使用分区来划分工作。 在查询内并行中,有三种并行类型:算子内并行、算子间并行和总线并行。
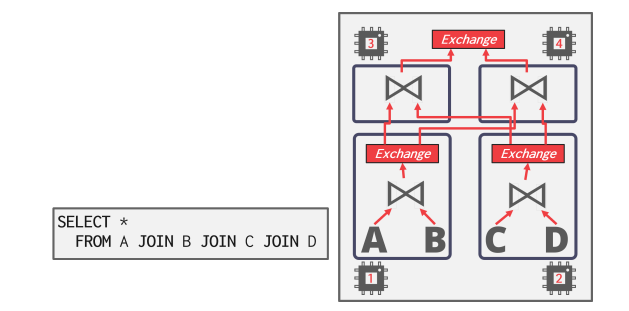
- Intra-Operator Parallelism (Horizontal)
- DBMS 会在查询计划中插入一个exchange算子(三种类型:gather、distribute、repartition),以合并来自子算子的结果。交换算子会阻塞 DBMS 执行计划中高于它的算子,直到它收到子算子的所有数据。
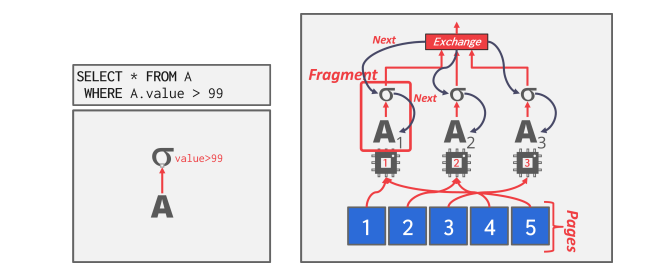
- Inter-Operator Parallelism (Vertical)
- 数据库管理系统会重叠运算符,以便将数据从一个阶段流水线输送到下一个阶段,而不需要实体化。这有时被称为流水线并行;
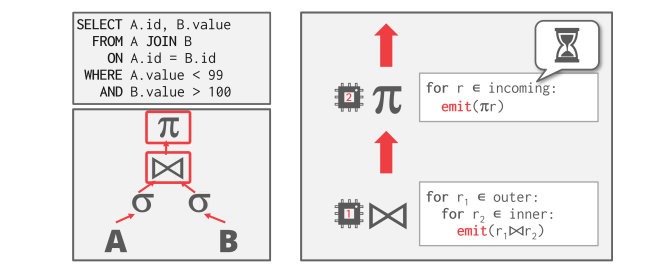
- Bushy Parallelism
- 混合体,在这种情况下,算子会同时执行来自查询计划不同部分的多个算子。 DBMS 仍会使用exchange来合并这些部分的中间结果;
I/O Parallelism
如果磁盘始终是主要瓶颈,那么使用额外进程/线程并行执行查询并不能提高性能。因此,在多个存储设备上拆分数据库非常重要。
两种方法:多磁盘并行性和数据库分区。
- Multi-Disk Parallelism
- 在多个存储设备上存储 DBMS 的文件。这可以通过存储设备或 RAID 配置来实现;
- Database Partitioning
- 数据库被分割成互不相连的子集,这些子集可以分配到不同的磁盘上;
- 逻辑分区的概念是将单个逻辑表分割成互不关联的物理段,分别存储/管理。理想情况下,这种分区对应用程序是透明的;
Lecture #14_ Query Planning & Optimization.md
Overview
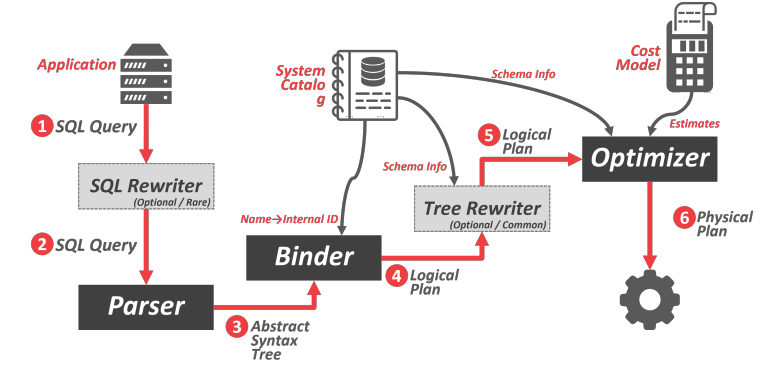
查询只能告诉 DBMS 要计算什么,而不能告诉 DBMS 如何计算。因此,数据库管理系统需要将 SQL 语句转化为可执行的查询计划。但是,执行查询计划中每个算子(如连接算法)的方法各不相同,这些计划的性能也会有差异。DBMS 优化器的工作就是为任何给定的查询选择一个最佳计划。
优化器将逻辑代数表达式映射为最佳等效物理代数表达式。逻辑计划大致等同于查询中的关系代数表达式。 物理运算符使用查询计划中不同运算符的访问路径定义了特定的执行策略。物理计划可能取决于所处理数据的物理格式(如排序、压缩)。 从逻辑计划到物理计划并不总是存在一对一的映射。
Logical Query Optimization
选择优化措施包括:尽早执行过滤;对谓词重新排序,以便 DBMS 首先应用选择性最强的谓词;分解复杂谓词并将其下推(拆分连接谓词)。
投影优化措施包括:尽早执行投影,以创建更小的元组并减少中间结果;剔除不需要的属性。

查询重写优化包括:删除不可能或不必要的谓词。在这种优化中,数据库管理系统会忽略不会改变结果的谓词的评估;合并谓词;通过去关联化和扁平化嵌套子查询来重写查询;分解嵌套查询,并将结果存储到临时表中。



JOIN操作的顺序是决定查询性能的关键因素。穷举效率很低,因此需要一个成本模型。不过仍然可以通过启发式优化方法消除不必要的连接。

Cost Estimations
DBMS 使用成本模型来估算执行计划的成本(CPU、disk I/O、memory、network)。这些模型会评估查询的等价计划,以帮助 DBMS 选择最优计划。

selection cardinality可用于确定对于输入将选择的图元数量。

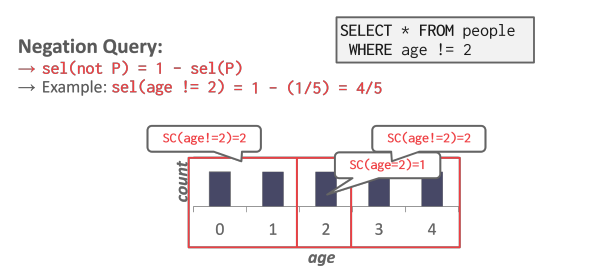
谓词的选择性等同于该谓词的概率。这使得概率规则可以应用于许多选择性计算中。这在处理复杂谓词时尤其有用。例如,如果我们假设连接中涉及的多个谓词是独立的,那么我们就可以计算连接的总 selectivity,即乘积。
Histograms
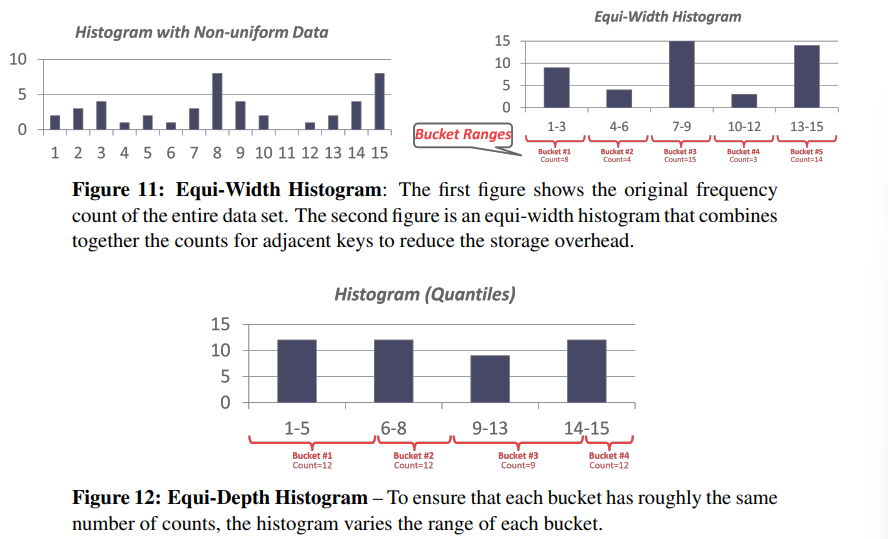
真实数据通常是有偏差的,要对其做出假设非常困难。然而,存储数据集的每一个值都很昂贵。减少内存使用量的一种方法是将数据存储在直方图中,将数值分组;另一种方法是使用等深直方图,改变桶的宽度,使每个桶的出现总数大致相同。
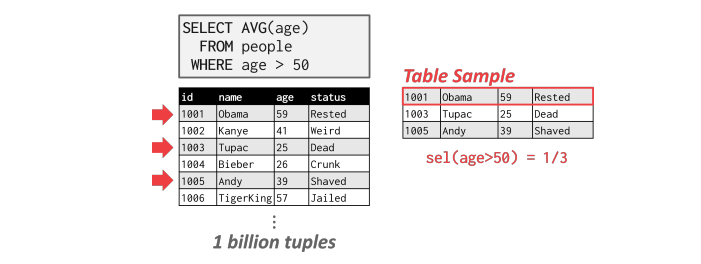
Sampling
DBMS 可以使用抽样将谓词应用于具有类似分布的表的较小副本。每当底层表的变化量超过阈值时,DBMS 就会更新样本。
Plan Enumeration
在执行重写后,数据库管理系统将枚举查询的不同计划,并估算其成本。然后,它会在穷尽所有计划或某个超时后,为查询选择最佳计划。
Single-Relation Query Plans
对于单相关查询计划,最大的障碍是选择最佳访问方法(如顺序扫描、二进制搜索、索引扫描等)。大多数新数据库系统只是使用启发式方法。
对于 OLTP 查询来说很容易,因为它们是可搜索的(Search Argument Able),这意味着存在一个可以为查询选择的最佳索引。这也可以通过简单的启发式方法来实现。
Multi-Relation Query Plans
对于多关联查询计划,随着连接数的增加,备选计划的数量也会迅速增加。 因此,必须限制搜索空间,以便能够在合理的时间内找到最优计划。
Bottom-up optimization example - System R
使用静态规则进行初始优化。然后使用动态编程,用分而治之的搜索方法确定表的最佳连接顺序。

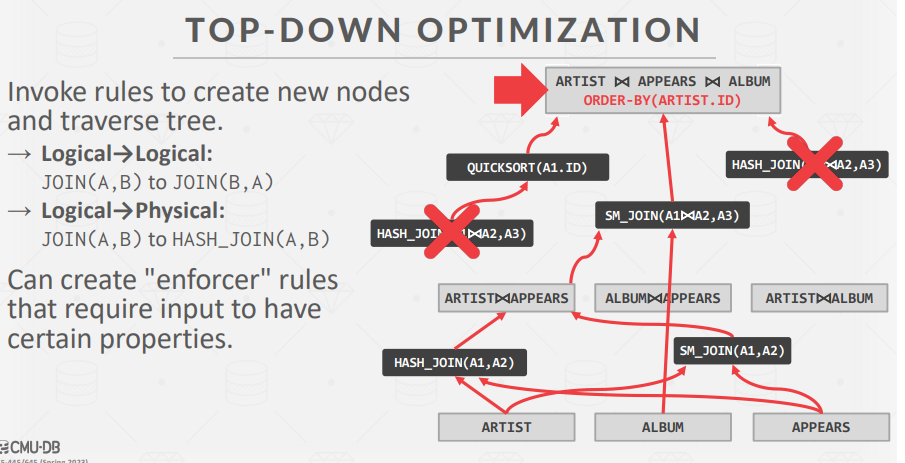
Top-down optimization example - Volcano
从希望查询的逻辑计划开始。通过将逻辑运算符转换为物理运算符,执行分支和边界搜索来遍历计划树。