Java21 + SpringBoot3集成Spring Data JPA
文章目录
- Java21 + SpringBoot3集成Spring Data JPA
- 前言
- 相关技术简介
- ORM(Object-Relational Mapping,对象-关系映射)
- JPA(Java Persistence API,Java持久层API)
- Hibernate
- Spring Data
- Spring Data JPA
- SpringBoot整合Spring Data JPA
- 引入maven依赖
- 修改配置文件
- 定义Spring Data JPA配置类
- 定义实体类
- 定义数据库实体基类
- 定义用户实体类
- 定义Repository接口
- 使用Repository接口
- 总结
- 附录
- Spring Data JPA 基于方法名创建查询支持的关键词
前言
近日心血来潮想做一个开源项目,目标是做一款可以适配多端、功能完备的模板工程,包含后台管理系统和前台系统,开发者基于此项目进行裁剪和扩展来完成自己的功能开发。
本项目为前后端分离开发,后端基于Java21和SpringBoot3开发,后端使用Spring Security、JWT、Spring Data JPA等技术栈,前端提供了vue、angular、react、uniapp、微信小程序等多种脚手架工程。
本文主要介绍JPA相关技术以及在项目中如何集成Spring Data JPA。
相关技术简介
ORM(Object-Relational Mapping,对象-关系映射)
ORM(Object-Relational Mapping) 即对象-关系映射。在面向对象的软件开发中,通过ORM,就可以把对象映射到关系型数据库中,一个类可以视作数据库中的一张表,类中的属性视作表中的字段,一个对象可以视为表中的一行记录。只要有一套程序能够做到建立对象与数据库的关联,操作对象就可以直接操作数据库数据,就可以说这套程序实现了ORM。也就是说ORM是建立了一个实体与数据库表的联系,这使得开发者对实体的直接操作而不是对数据库的操作,但操作实体也就等同于操作了数据库。主流的ORM框架有MyBatis、Hibernate、Spring Data JPA等。
JPA(Java Persistence API,Java持久层API)
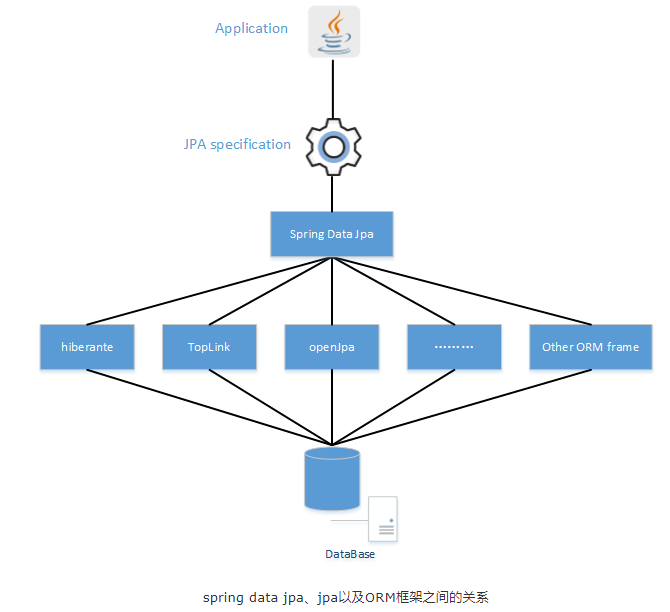
JPA(Java Persistence API)是 Java EE 标准中的一部分,它通过提供提供一套对象关系模型(ORM)来帮助在开发应用过程中高效的管理关系型数据。和 JDBC 一样,JPA 本身并不是一个框架,只是一套标准接口,是ORM框架的标准和规范,目前比较成熟的 JPA 实现有 Hibernate、EclipseLink 等。
Sun引入新的JPA ORM规范出于两个原因:其一,简化现有Java EE和Java SE应用开发工作;其二,Sun希望整合ORM技术,实现天下归一。
JPA的目标是提供一种统一的、面向对象的数据访问方式,使开发人员能够更加方便地进行数据库操作,而不需要关注底层数据库的细节。它抽象了不同数据库之间的差异,提供了一套通用的API,使开发人员能够以相同的方式操作不同的数据库。
JPA的核心概念包括实体(Entity)、实体管理器(EntityManager)、持久化上下文(Persistence Context)等。开发人员可以通过注解或XML配置来定义实体类和数据库表之间的映射关系,然后使用EntityManager进行增删改查等数据库操作。

Hibernate
Hibernate是一个标准的ORM框架,实现Jpa接口。Hibernate着手解决如何实现映射的方案,是一种处理映射关系方法类框架。
JPA和Hibernate 的关系就像JDBC和JDBC 驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。

Spring Data
Spring Data是Spring Framework的一个子项目,它提供了一种简化数据访问层的方式。Spring Data支持多种数据存储技术,包括关系型数据库、NoSQL数据库、搜索引擎等。
通过使用Spring Data,开发人员可以更轻松地进行数据访问,同时还能够利用Spring Framework的其他功能,如依赖注入、面向切面编程等。
Spring Data提供了一组通用的API和实现,可以帮助开发人员快速、简便地访问各种类型的数据存储。
Spring Data JPA
Spring Data JPA是Spring Data项目中的一个模块,它提供了对JPA(Java Persistence API)的支持。
Spring Data JPA通过提供一组简化的API和自动化的实现,使得开发人员可以更轻松地进行数据库访问和操作。它减少了编写重复、繁琐的数据访问代码的工作量,同时还提供了一些方便的特性,如查询方法的自动生成、分页和排序的支持等。
使用Spring Data JPA,开发人员只需定义好实体类和接口,通过继承一些预定义的接口,就可以实现常见的数据访问操作,而无需编写具体的SQL语句。这样可以大大简化开发过程,提高开发效率。
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,但底层还是使用了 Hibernate 的 JPA 技术实现。
SpringBoot整合Spring Data JPA
https://zhuanlan.zhihu.com/p/570922724
在下文中笔者将以实现对用户表SysUser的增删改查为例,介绍SpringBoot整合Spring Data JPA的详细过程。所示项目基于Java21和SpringBoot3实现,数据库使用MySQL 5.7。
引入maven依赖
在pom.xml中添加MySQL和Spring Data JPA相关依赖,并引入Lombok用于简化代码。
<dependencies><!--Spring Data JPA Starter--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><!--MySQL依赖包--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><!-- Lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version><optional>true</optional></dependency>
</dependencies>
修改配置文件
在配置文件application.yml或application.properties中增加数据库和jpa相关配置。以下代码使用的是yml文件。
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driver # JDBC驱动类url: jdbc:mysql://localhost:3306/db_demo?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai # 数据库urlusername: developer # 数据库用户名password: abc123 # 数据库密码jpa:database: mysql # 数据库类型database-platform: org.hibernate.dialect.MySQL57Dialect # 数据库方言show-sql: true # 控制台打印SQLhibernate:ddl-auto: create # 根据实体类自动建表
上述配置中spring.jpa.hibernate.ddl-auto作用是根据实体类自动建表,无需手写ddl来建表。这样就使得开发者可以专注于实体类的设计,无需再去考虑建表SQL,可以提高开发效率。但此配置项更适合于开发环境时使用,不建议生产环境使用。
ddl-auto可选值如下:
- none,默认值,无任何操作;
- create,服务启动时没有表会新建表,有表则删除表和已有数据后重新建表;
- create-drop,服务启动时没有表会新建表,有表则清空数据并删除后重新建表,服务停止时删除所有表和数据;
- update,服务启动时没有表则新建表,有表则更新表结构,不清空已有数据;
- validate,服务启动时会校验实体类和数据库表结构是否一致,不一致会报错。
定义Spring Data JPA配置类
定义一个配置类Bean,启用Spring Data JPA,也可以直接main方法所在类上直接添加@EnableJpaRepositories和@EntityScan注解。
package com.demo.data.config;import org.springframework.boot.autoconfigure.domain.EntityScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;/*** Spring Data JPA Bean配置* 启用Jpa,扫描指定包下的Repository类和指定包下的实体类*/
@Configuration
@EnableJpaRepositories(basePackages = {"com.demo.data.repo"})
@EntityScan(basePackages = "com.demo.data.model")
public class JpaConfig {
}定义实体类
定义数据库实体基类
为了简化代码,可以将所有数据库实体类共有的属性提取出来,定义一个基础类。
/*** 数据库实体基类,声明数据库实体类共有属性*/
@Getter
@Setter
@MappedSuperclass
public abstract class BaseEntity implements Serializable {/*** ID,唯一标识列,使用主键自增策略*/@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;/*** 创建时间*/@CreatedDateprivate LocalDateTime createdTime;/*** 最后修改时间*/@LastModifiedDateprivate LocalDateTime lastModifiedTime;/*** 创建人ID*/private Long creatorId;/*** 最后修改人ID*/private Long lastModifierId;
}
@MappedSuperclass,表示一个类是某些实体类的超类,它不会直接映射为数据库表,但是可以被其他实体类继承,它的子类映射的数据库表中会包含它自身声明的属性。@Id,用于声明一个实体类的属性映射为数据库的主键列,一个JPA实体类中必须要有一个使用@Id注解的属性。@GeneratedValue,用于指定主键的生成策略,通过strategy属性来设置。@CreatedDate,表示该字段为创建时间字段,执行insert语句前会自动赋值。@LastModifiedDate,表示该字段为最后修改时间字段,执行insert和update语句前会自动赋值。
定义用户实体类
用户实体类SysUser中还用到了部门类Department,使用Department主要是为了介绍@Transient注解,本文不再给出其详细代码。它同样继承自BaseEntity,有部门编号(code)和部门名称(name)两个属性。
/*** 用户实体类*/
@Getter
@Setter
@Entity(name = "sys_user")
public class SysUser extends BaseEntity {/*** 用户名*/@Column(unique = true)private String username;/*** 密码*/private String password; /*** 电话*/private String phone;/*** 个人介绍*/@Lobprivate String introduce;/*** 所属部门ID*/private Long departmentId;/*** 所属部门*/@Transientprivate Department department;
}
@Entity,表示该类是一个实体类,可以映射为数据库表。name属性用于自定义表名,不设置name属性时默认会取类名转化为全小写+下划线分隔的字符串作为表名,比如类名为SysUser则默认映射的表名为sys_user。在使用了
@Entity注解的类中,必须要有一个使用@Id注解修饰的属性。
在使用了@Entity注解的类中,所有的属性都会被映射为数据库表中的字段,除非属性上使用了@Transient注解。
@Column,表示该属性是一个表中的字段,unique = true可以在对应字段上定义唯一约束,在有@Entity注解修饰的类中,属性上不加@Column注解也可以被映射为字段。
@Lob,表示该属性需要映射成数据库支持的大对象类型的字段,比如Clob或者Blob。
@Transient,表示该属性并非一个到数据库表中字段的映射,ORM框架映射时会忽略该属性。
定义Repository接口
JPA中的Repository可以理解为DAO(Data Access Object),即数据操纵对象。一个JPA的实体类需要有一个对应的Repository,用于操作该实体类所映射的数据库表。Repository可以仅仅是一个接口无需创建它的实现类,需要继承JpaRepository<T, ID>接口,T是实体类,ID是实体类中@Id修饰的属性的类型。程序启动时Spring Data JPA会自动生成该接口的实现,并注册为Spring Bean。
JpaRepository中定义了一系列最基本的CURD方法,开发者可以直接使用,也可以根据业务需求自定义查询方法。Spring Data JPA支持多种查询定义方式,主要包括:
- 基于方法名创建查询,可以根据方法名中的关键词构造出实际的查询SQL,在附录中给出了Spring Data JPA所支持的关键词;
- 基于
@Query注解创建JPQL查询或者原生SQL查询,nativeQuery属性设置为true时表示使用原生SQL; - 基于
Specification构造动态查询,此方式需要Repository继承JpaSpecificationExecutor<T>接口,T是实体类;
以下代码是使用不同方法创建查询的示例,基于Specification的查询方式在下一章节中给出。
/*** 用户表Repository*/
public interface SysUserRepository extends JpaRepository<SysUser, Long>, JpaSpecificationExecutor<SysUser> {/*** 根据username精确查询*/Optional<SysUser> findByUsername(String username);@Query("select u from SysUser u where u.username = ?1")Optional<SysUser> findByUsername2(String username);
}
使用Repository接口
在前文中我们已经定义好了一个用户实体类SysUser和一个用户表的DAO接口SysUserRepository,下面我们就来使用它们完成简单的增删改查操作。以下代码中我们定义了一个服务类接口SysUserService和它的具体实现SysUserServiceImpl。
public interface SysUserService {/*** 分页查询*/Page<SysUser> page(Pageable pageable);/*** 查询全部用户*/List<SysUser> list();/*** 根据ID查询*/SysUser retrieve(Long id);/*** 根据用户名查询*/SysUser findByUsername(String username);/*** 新增用户*/SysUser create(SysUser user);/*** 修改用户*/SysUser update(SysUser user);/*** 批量删除用户*/void remove(List<Long> ids);
}
@Service
public class SysUserServiceImpl implements SysUserService {private final SysUserRepository userRepository;public SysUserServiceImpl(SysUserRepository userRepository) {this.userRepository = userRepository;}@Overridepublic Page<SysUser> page(Pageable pageable) {return userRepository.findAll(pageable);}@Overridepublic List<SysUser> list() {return userRepository.findAll();}@Overridepublic SysUser retrieve(Long id) {return userRepository.findById(id).orElse(null);}@Overridepublic SysUser findByUsername(String username) {// 使用基于方法名定义的查询return userRepository.findByUsername(username).orElse(null);// 使用基于@Query定义的查询// return userRepository.findByUsername2(username).orElse(null);// 使用Specification查询// return userRepository.findOne(// (root, query, criteriaBuilder) -> criteriaBuilder.equal(root.get("username").as(String.class), username)// ).orElse(null);}@Overridepublic SysUser create(SysUser user) {return userRepository.save(user);}@Overridepublic SysUser update(SysUser user) {if (userRepository.findById(user.getId()).isEmpty()) {throw new RuntimeException("未查询到数据");}return userRepository.save(user);}@Overridepublic void remove(List<Long> ids) {userRepository.deleteAllById(ids);}
}
总结
在本文中,我们一起学习了与Spring Data JPA相关的技术简介,学习了如何基于Java21和SpringBoot3整合Spring Data JPA,也学习了JPA Repository的简单使用方法,如有错误,还望批评指正。
在后续实践中我也是及时更新自己的学习心得和经验总结,希望与诸位看官一起进步。
附录
Spring Data JPA 基于方法名创建查询支持的关键词
数据来源:Spring Data JPA 3.2.2官方文档https://docs.spring.io/spring-data/jpa/reference/jpa/query-methods.html#jpa.query-methods.query-creation
| 关键词 | 示例 | 对应的JPQL语句 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |