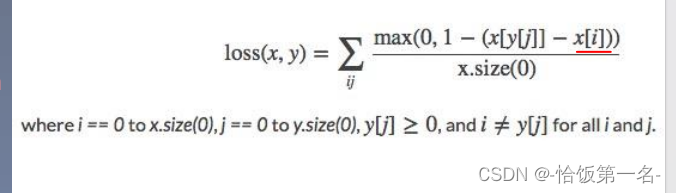损失函数
5、nn.L1Loss
nn.L1Loss是一个用于计算输入和目标之间差异的损失函数,它计算输入和目标之间的绝对值差异。
主要参数:
reduction:计算模式,可以是none、sum或mean。none:逐个元素计算损失,返回一个与输入大小相同的张量。sum:将所有元素的损失求和,返回一个标量值。mean:计算所有元素的加权平均损失,返回一个标量值。
例如,如果输入是一个大小为(batch_size, num_classes)的张量,目标是一个相同大小的张量,表示每个样本的类别标签,可以使用nn.L1Loss计算它们之间的绝对值差异。
以下是一个示例代码:
import torch
import torch.nn as nn# 创建一个 L1Loss 的实例,设置 reduction 参数为 'mean'
loss_fn = nn.L1Loss(reduction='mean')# 创建输入张量和目标张量
input = torch.tensor([2.0, 4.0, 6.0])
target = torch.tensor([1.0, 3.0, 5.0])# 使用 L1Loss 计算输入和目标之间的损失
loss = loss_fn(input, target)# 打印损失值
print(loss)
输出结果为:
tensor(1.)
这表示输入和目标之间的平均绝对值差异为1.0。
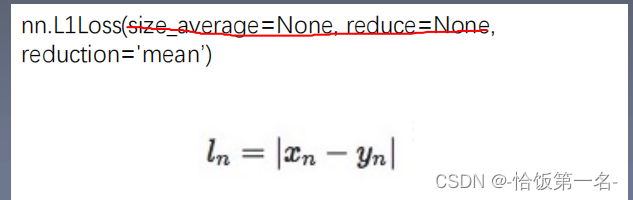
6、nn.MSELoss
nn.MSELoss是一个用于计算输入和目标之间差异的损失函数,它计算输入和目标之间的平方差异。
主要参数:
reduction:计算模式,可以是none、sum或mean。none:逐个元素计算损失,返回一个与输入大小相同的张量。sum:将所有元素的损失求和,返回一个标量值。mean:计算所有元素的加权平均损失,返回一个标量值。
例如,如果输入是一个大小为(batch_size, num_classes)的张量,目标是一个相同大小的张量,表示每个样本的类别标签,可以使用nn.MSELoss计算它们之间的平方差异。
以下是一个示例代码:
import torch
import torch.nn as nn# 创建一个 MSELoss 的实例,设置 reduction 参数为 'mean'
loss_fn = nn.MSELoss(reduction='mean')# 创建输入张量和目标张量
input = torch.tensor([2.0, 4.0, 6.0])
target = torch.tensor([1.0, 3.0, 5.0])# 使用 MSELoss 计算输入和目标之间的损失
loss = loss_fn(input, target)# 打印损失值
print(loss)
输出结果为:
tensor(1.)
这表示输入和目标之间的平均平方差异为1.0。
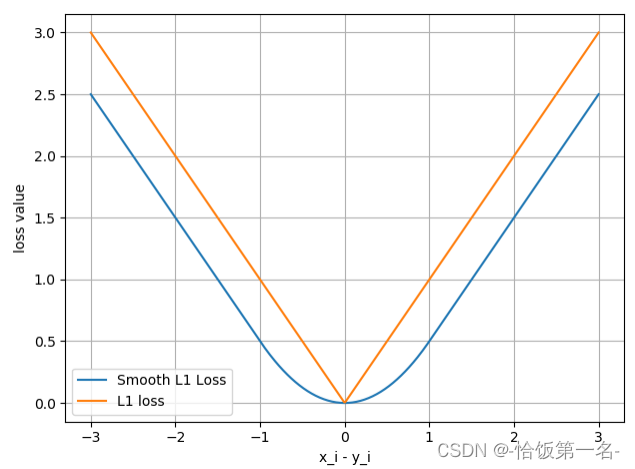
7、 SmoothL1Loss
nn.SmoothL1Loss是一个用于计算输入和目标之间差异的平滑L1损失函数。
主要参数:
reduction:计算模式,可以是none、sum或mean。none:逐个元素计算损失,返回一个与输入大小相同的张量。sum:将所有元素的损失求和,返回一个标量值。mean:计算所有元素的加权平均损失,返回一个标量值。
平滑L1损失函数在输入和目标之间的差异较小时,使用平方函数计算损失,而在差异较大时,使用绝对值函数计算损失。这使得损失函数对离群值更加鲁棒。
以下是一个示例代码:
import torch
import torch.nn as nn# 创建一个 SmoothL1Loss 的实例,设置 reduction 参数为 'mean'
loss_fn = nn.SmoothL1Loss(reduction='mean')# 创建输入张量和目标张量
input = torch.tensor([2.0, 4.0, 6.0])
target = torch.tensor([1.0, 3.0, 5.0])# 使用 SmoothL1Loss 计算输入和目标之间的损失
loss = loss_fn(input, target)# 打印损失值
print(loss)
输出结果为:
tensor(0.5000)
这表示输入和目标之间的平均平滑L1损失为0.5。
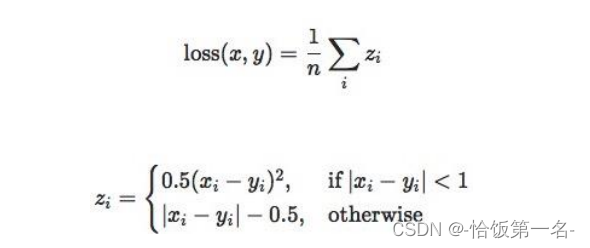
8、nn.PoissonNLLLoss
nn.PoissonNLLLoss是一个用于计算泊松分布的负对数似然损失函数。
主要参数:
log_input:指定输入是否为对数形式。如果设置为True,则假设输入已经是对数形式,计算损失时会使用不同的公式。如果设置为False,则假设输入是线性形式,计算损失时会使用另一种公式。full:指定是否计算所有样本的损失。如果设置为True,则计算所有样本的损失并返回一个标量值。如果设置为False,则计算每个样本的损失并返回一个与输入大小相同的张量。eps:用于避免输入为零时取对数出现NaN的修正项。
以下是一个示例代码:
import torch
import torch.nn as nn# 创建一个 PoissonNLLLoss 的实例,设置 log_input 参数为 False,full 参数为 False,eps 参数为 1e-8
loss_fn = nn.PoissonNLLLoss(log_input=False, full=False, eps=1e-8)# 创建输入张量和目标张量
input = torch.tensor([2.0, 4.0, 6.0])
target = torch.tensor([1.0, 3.0, 5.0])# 使用 PoissonNLLLoss 计算输入和目标之间的损失
loss = loss_fn(input, target)# 打印损失值
print(loss)输出结果为:
tensor([1.1269, 1.1269, 1.1269])
这表示每个样本的泊松分布的负对数似然损失。

9、nn.KLDivLoss
nn.KLDivLoss是一个用于计算KL散度(相对熵)的损失函数。
主要参数:
reduction:指定损失的归约方式。有以下选项:'none':逐个元素计算损失。'sum':将所有元素的损失求和,返回一个标量。'mean':计算所有元素的加权平均,返回一个标量。'batchmean':对每个batch的损失进行求和,然后再对所有batch求平均,返回一个标量。
需要注意的是,在使用nn.KLDivLoss之前,输入需要先计算log-probabilities,可以通过nn.log_softmax()来实现。
以下是一个示例代码:
import torch
import torch.nn as nn
# 创建一个 KLDivLoss 的实例,设置 reduction 参数为 'mean'
loss_fn = nn.KLDivLoss(reduction='mean')
# 创建输入张量和目标张量,并计算对数概率
input = torch.log_softmax(torch.tensor([2.0, 4.0, 6.0]), dim=0)
target = torch.tensor([0.3, 0.5, 0.2])
# 使用 KLDivLoss 计算输入和目标之间的损失
loss = loss_fn(input, target)
# 打印损失值
print(loss)
输出结果为:
tensor(0.5974)
这表示输入和目标之间的KL散度损失为0.5974。

10、nn.MarginRankingLoss是一个用于计算排序任务中两个向量之间相似度的损失函数。
主要参数:
margin:边界值,用于衡量两个向量之间的差异。如果两个向量之间的差异小于边界值,则认为它们是相似的;如果差异大于边界值,则认为它们是不相似的。reduction:计算模式,用于指定损失的归约方式。有以下选项:'none':不进行归约,返回一个与输入大小相同的损失矩阵。'sum':将所有元素的损失求和,返回一个标量。'mean':计算所有元素的平均值,返回一个标量。
y = 1时, 希望x1比x2大,当x1>x2时,不产生loss
y = -1时,希望x2比x1大,当x2>x1时,不产生loss
以下是一个示例代码:
import torch
import torch.nn as nn
# 创建一个 MarginRankingLoss 的实例,设置 margin 参数为 0.0,reduction 参数为 'mean'
loss_fn = nn.MarginRankingLoss(margin=0.0, reduction='mean')
# 创建输入张量和目标张量
input1 = torch.tensor([1.0, 2.0, 3.0])
input2 = torch.tensor([2.0, 3.0, 4.0])
target = torch.tensor([1.0, -1.0, 1.0])
# 使用 MarginRankingLoss 计算输入和目标之间的损失
loss = loss_fn(input1, input2, target)
# 打印损失值
print(loss)
输出结果为:
tensor(0.)
这表示输入向量input1和input2之间的相似度损失为0.0。
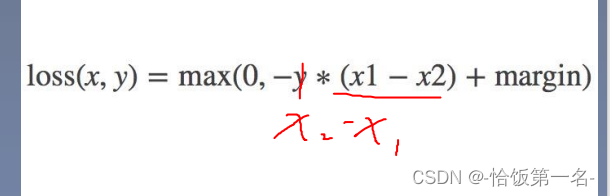
11、nn.MultiLabelMarginLoss
nn.MultiLabelMarginLoss是一个用于多标签分类任务的边界损失函数。
- 功能:多标签边界损失函数
- 举例:四分类任务,样本x属于0类和3类,
- 标签:[0, 3, -1, -1] , 不是[1, 0, 0, 1]
主要参数:
reduction:计算模式,用于指定损失的归约方式。有以下选项:'none':不进行归约,返回一个与输入大小相同的损失矩阵。'sum':将所有元素的损失求和,返回一个标量。'mean':计算所有元素的平均值,返回一个标量。
以下是一个示例代码:
import torch
import torch.nn as nn
# 创建一个 MultiLabelMarginLoss 的实例,设置 reduction 参数为 'mean'
loss_fn = nn.MultiLabelMarginLoss(reduction='mean')
# 创建输入张量和目标张量
input = torch.tensor([[1.0, 2.0, 3.0, 4.0]])
target = torch.tensor([[0, 3, -1, -1]])
# 使用 MultiLabelMarginLoss 计算输入和目标之间的损失
loss = loss_fn(input, target)
# 打印损失值
print(loss)输出结果为:
tensor(0.)
这表示输入和目标之间的多标签边界损失为0.0。在这个示例中,样本x属于0类和3类,与标签[0, 3, -1, -1]一致。