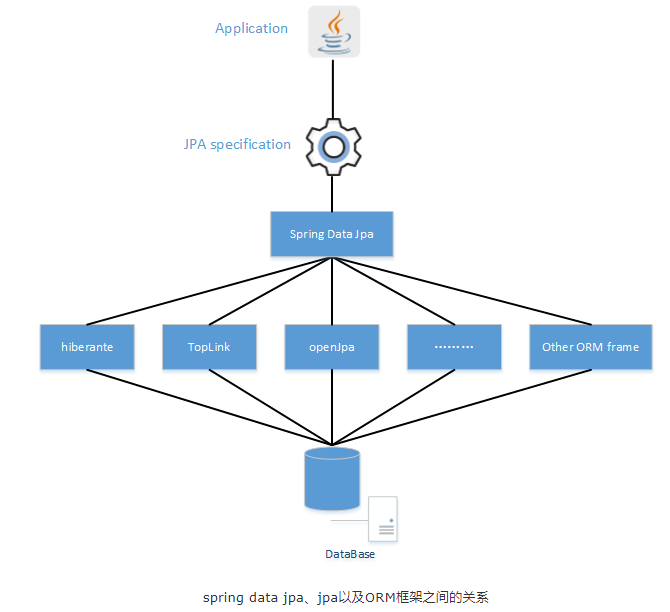
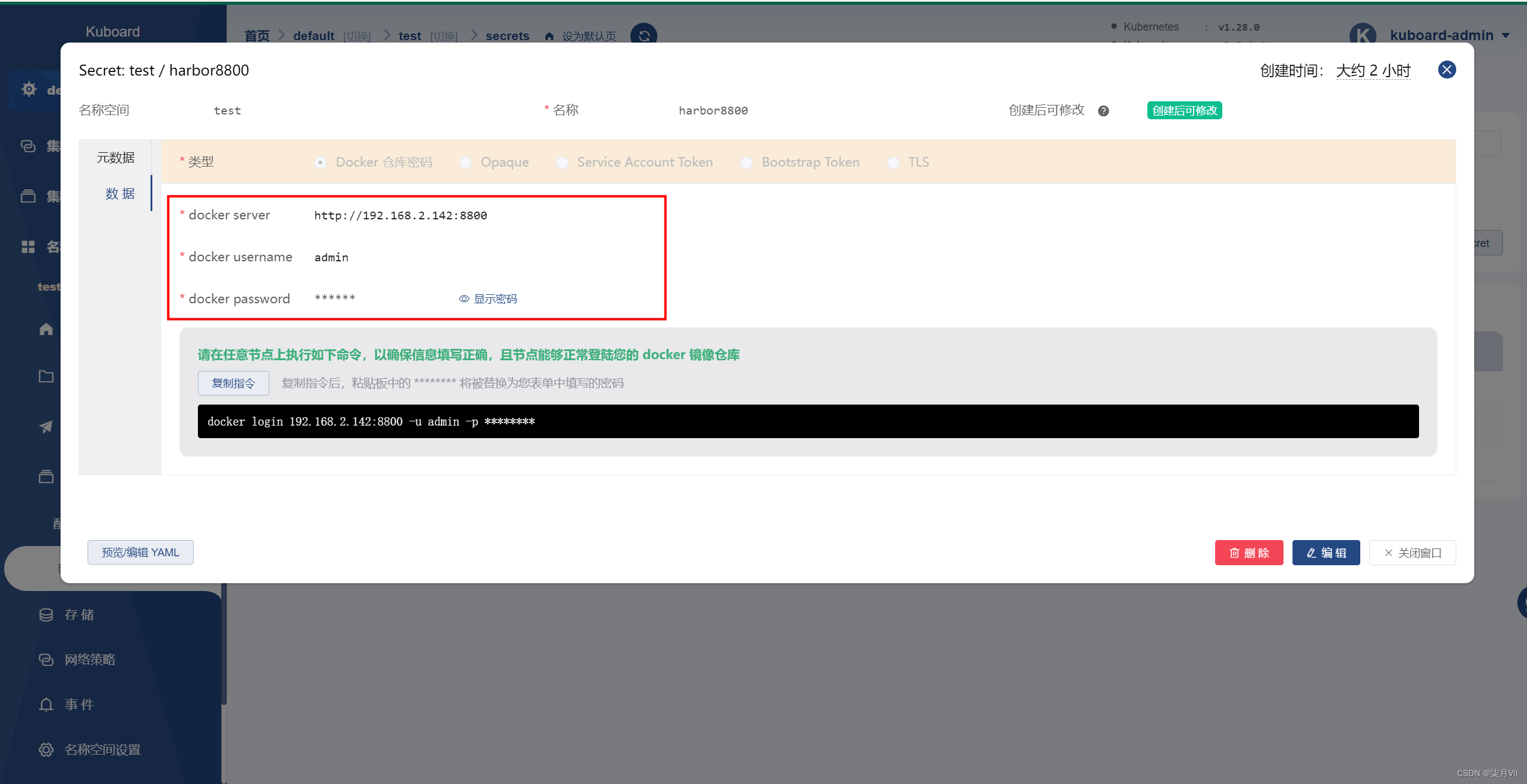
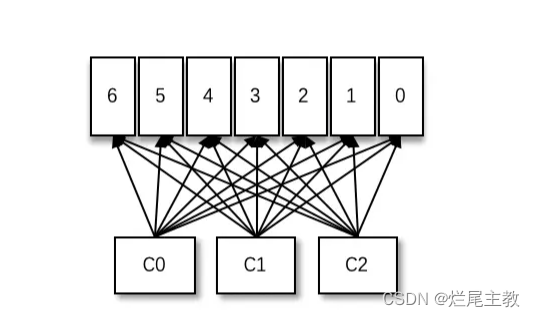
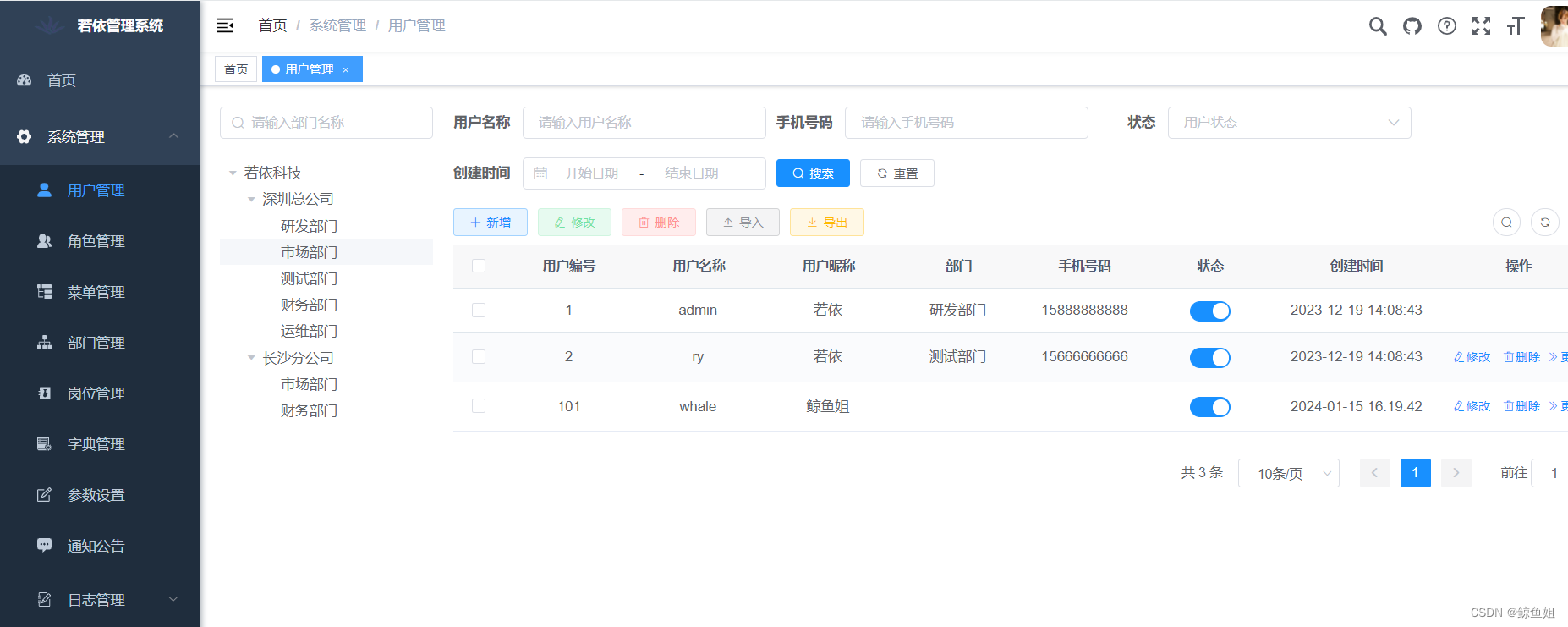
在多线程爬虫项目中,HTTP/HTTPS代理IP的实践主要包括以下几个关键步骤:
1. 收集代理IP资源:
- 从免费或付费代理IP提供商、公开代理列表网站(如西刺代理、无忧代理等)抓取代理IP和端口信息。
- 存储这些IP到数据库或者文件中,格式通常为`ip:port`。
2. 构建代理池:
- 设计一个代理池管理器,用于存储并维护代理IP的有效性。
- 代理池需要具备添加新IP、移除无效IP以及根据策略分配IP给爬虫的功能。
3. 验证代理IP有效性:
- 使用多线程对获取的代理IP进行有效性验证。通过发送HTTP请求至特定验证网址(比如Google首页或者其他可快速响应的API),检查返回的状态码和响应时间来判断IP是否可用及速度如何。
- 验证过程中要确保遵守网站的服务条款,并且不要过于频繁地向目标服务器发送请求,以免被封禁。
4. 集成代理IP到爬虫程序:
- 在爬虫代码中使用如requests库这样的网络请求模块,结合使用如`requests.Session()`来管理带有代理设置的会话对象。
- 每个爬虫线程从代理池中取出一个有效的代理IP,在发起HTTP请求时配置代理参数。
- 当一个代理失效或达到预设的使用次数后,将其标记为不可用,并通知代理池管理器更新状态。
5. 动态调整与优化:
- 根据爬虫运行情况实时调整代理池策略,如:优先使用速度快的代理,自动剔除长时间无响应的代理,适时补充新的代理IP等。
6. 错误处理与容错:
- 实现良好的错误处理机制,当某个代理IP因各种原因导致请求失败时,能立即切换到下一个有效代理继续执行任务。
示例代码片段(基于Python requests库):
```python
import requests
from concurrent.futures import ThreadPoolExecutor
from proxy_pool import ProxyPool # 假设有一个实现了代理池功能的ProxyPool类
# 初始化代理池
pool = ProxyPool()
def validate_proxy(proxy):
try:
response = requests.get('http://example.com', proxies={'http': 'http://' + proxy, 'https': 'https://' + proxy})
if response.status_code == 200:
return True
except Exception as e:
print(f"验证代理 {proxy} 失败,原因:{e}")
return False
def worker():
while True:
proxy = pool.get_valid_proxy()
if proxy is None:
break
if validate_proxy(proxy):
# 使用有效代理进行爬虫任务
session = requests.Session()
session.proxies.update({'http': 'http://' + proxy, 'https': 'https://' + proxy})
# 发起实际的网页请求...
else:
# 若验证失败,将该代理放回池子并标记为无效
pool.mark_invalid(proxy)
# 使用多线程验证并使用代理
with ThreadPoolExecutor(max_workers=10) as executor:
for _ in range(10): # 根据需要创建多个工作线程
executor.submit(worker)
```
请注意以上代码仅为简化示例,实际项目中可能需要根据具体需求和代理池的实现细节进行相应调整。