spark读取kafka(批数据处理)
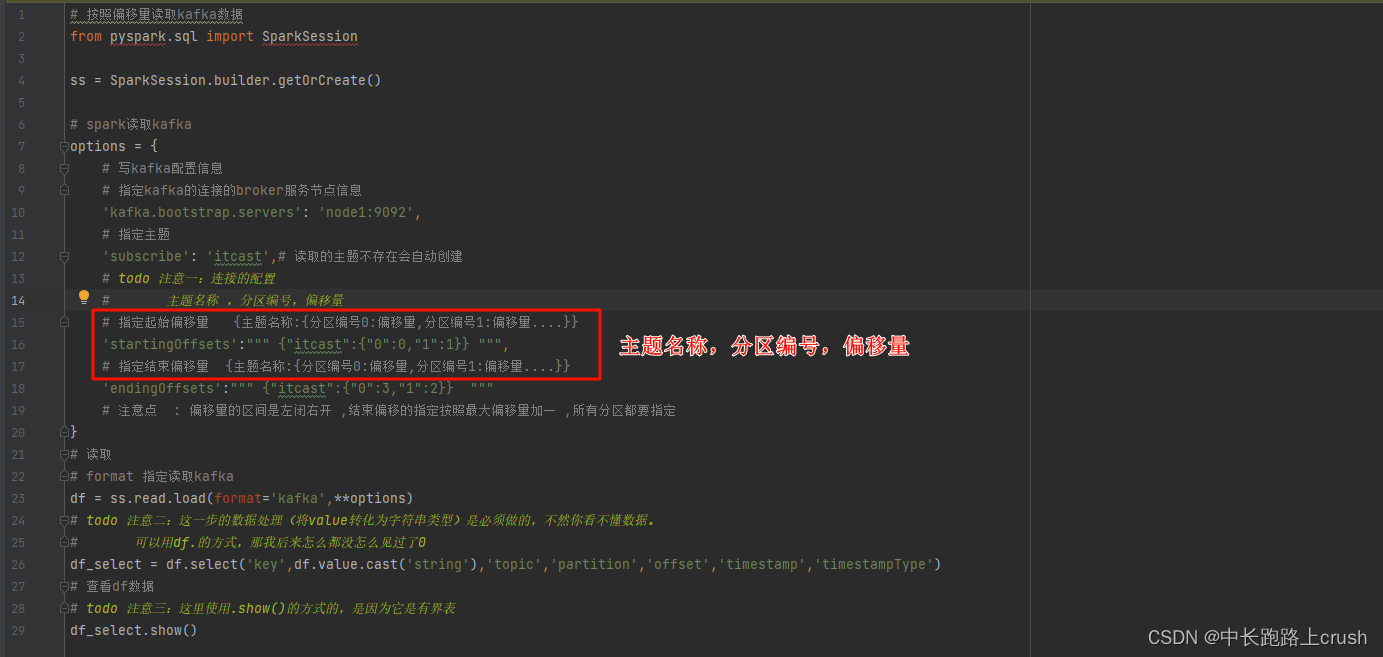
# 按照偏移量读取kafka数据
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()# spark读取kafka
options = {# 写kafka配置信息# 指定kafka的连接的broker服务节点信息'kafka.bootstrap.servers': 'node1:9092',# 指定主题'subscribe': 'itcast',# 读取的主题不存在会自动创建# todo 注意一:连接的配置# 主题名称 ,分区编号,偏移量# 指定起始偏移量 {主题名称:{分区编号0:偏移量,分区编号1:偏移量....}}'startingOffsets':""" {"itcast":{"0":0,"1":1}} """,# 指定结束偏移量 {主题名称:{分区编号0:偏移量,分区编号1:偏移量....}}'endingOffsets':""" {"itcast":{"0":3,"1":2}} """# 注意点 : 偏移量的区间是左闭右开 ,结束偏移的指定按照最大偏移量加一 ,所有分区都要指定
}
# 读取
# format 指定读取kafka
df = ss.read.load(format='kafka',**options)
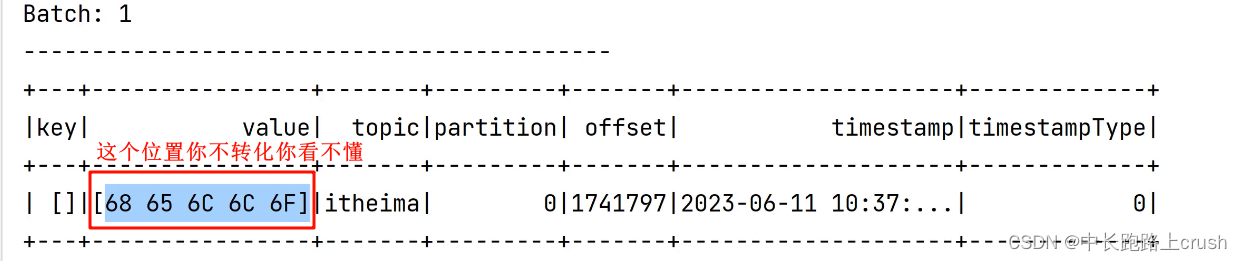
# todo 注意二:这一步的数据处理(将value转化为字符串类型)是必须做的,不然你看不懂数据。
# 可以用df.的方式,那我后来怎么都没怎么见过了0
df_select = df.select('key',df.value.cast('string'),'topic','partition','offset','timestamp','timestampType')
# 查看df数据
# todo 注意三:这里使用.show()的方式的,是因为它是有界表
df_select.show()

spark读取kafka(流数据处理)
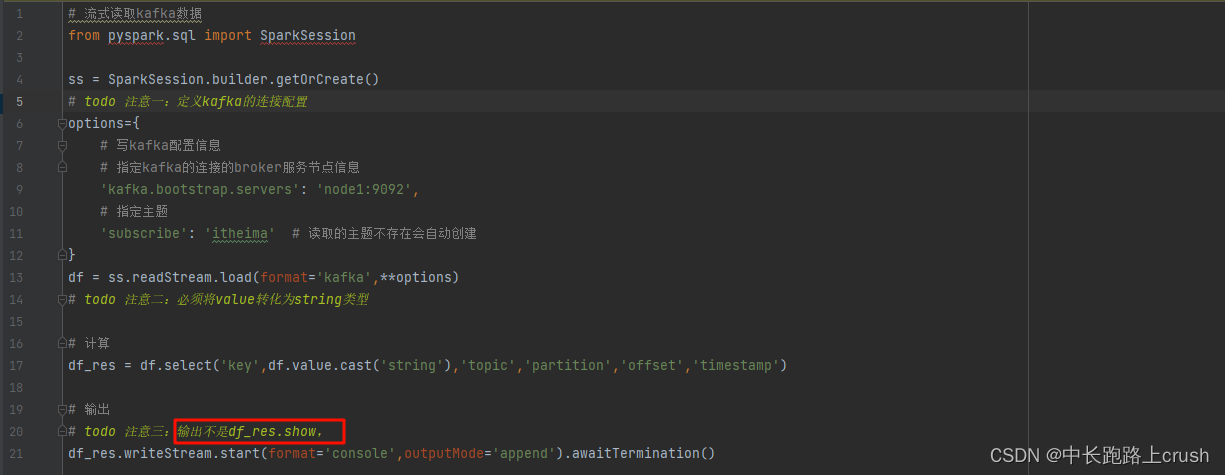
# 流式读取kafka数据
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()
# todo 注意一:定义kafka的连接配置
options={# 写kafka配置信息# 指定kafka的连接的broker服务节点信息'kafka.bootstrap.servers': 'node1:9092',# 指定主题'subscribe': 'itheima' # 读取的主题不存在会自动创建
}
df = ss.readStream.load(format='kafka',**options)
# todo 注意二:必须将value转化为string类型# 计算
df_res = df.select('key',df.value.cast('string'),'topic','partition','offset','timestamp')# 输出
# todo 注意三:输出不是df_res.show,
df_res.writeStream.start(format='console',outputMode='append').awaitTermination()