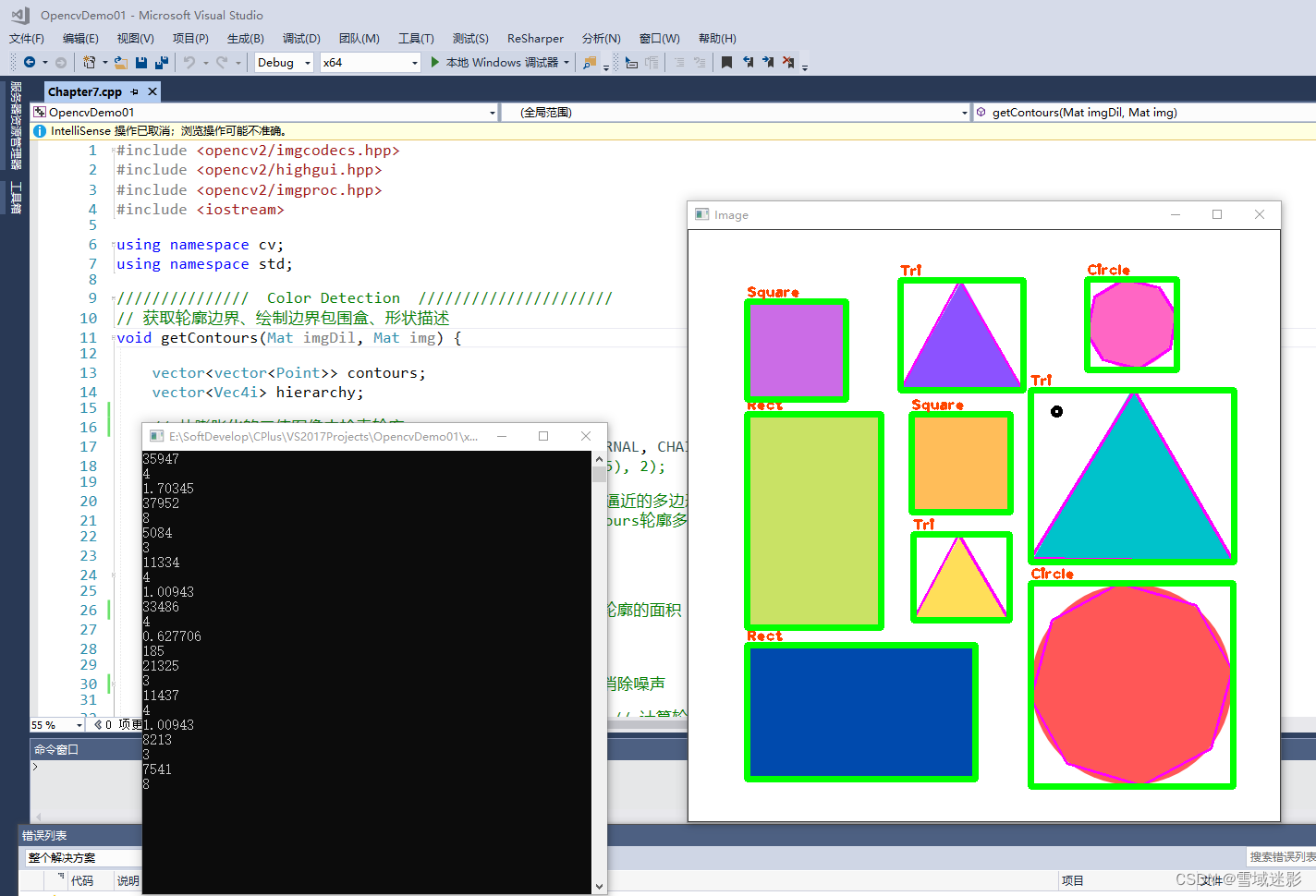
今天接到一份数据需要分析,数据在一个excel文件里,内容大概形式如下:

后面空的格子里的值就是默认是前面的非空的值,由于数据分析的需要需要对重复的数据进行去重,去重就需要把控的cell的值补上,然后根据几个关键的cell的值计算一个唯一的key, 类似如下:
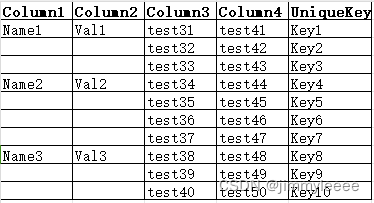
如果UniqueKey有重复的,就可以通过Excel的去重复数据的功能,直接将重复的行去掉。
接下来就需要一个简单的方法,把后面的空的cell的内容填上,这样通过公式计算UniqueKey时,就可以很容易。虽然Excel也提供了可以使用其他的Cell的值填充空白Cell的值,但是操作步骤有点作,而且对于操作有几千上万行的excel文件来说,太不方便,万一出错,就需要重来一遍。
正好学习了pandas库,发现用它的dataframe可以很轻松地实现。
Python代码如下:
import pandas as pddata_file = "F:\\1.xlsx"
data_info = pd.read_excel(data_file)
data_info.fillna(method="ffill", inplace=True)
data_info.to_excel("2.xlsx")代码运行之后,打开输出文件,内容如下:
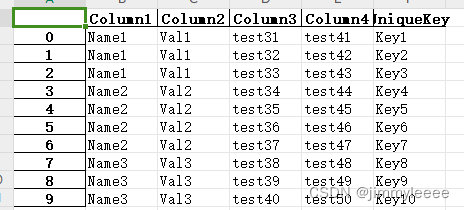
几行代码就可以轻松搞定几万行的文件的数据处理!