今天在程序调试时,程序中用到一个config.json文件,是UTF-8的格式,这是在win11的nodtepad中显示的编码格式,但复制到win7中使用时,出现一个奇特的现象,报文件格式错误,说出现一个特殊字符不识别,这个特殊字符像一个字母i上面有两点的一个特殊字符,但经过目视检查,没有任何问题,百思不得其解,最后还是chatgpt厉害,直接给出了原因和答案。
说这是一个UTF-8 BOM格式,导致的不兼容,解决办法是换成ANSI格式或再转换成标准的UTF-8格式,问题解决。
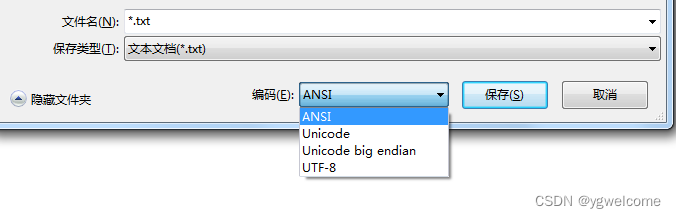
但怎么会出现这种问题的呢?有必要对文本文件的编码,再做详细的梳理。在win7或以前的系统中的notepad,支持ANSI、unicode、unicode big endian、UTF-8四种格式,如下图所示:
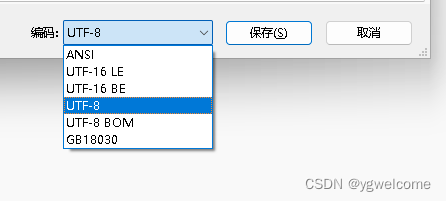
在win11的notepad中,支持ANSI、UTF-16 LE、UTF-16 BE、UTF-8、UTF-8 BOM、GB18030六种格式,如下图所示:
UTF,是Unicode Transformation Format"的缩写。Unicode是一种标准字符集,而UTF则是一种用于在计算机中存储和传输Unicode字符的编码方式。
下面,对这几种编码格式进行一一解释:
1、ANSI(ASCII):
使用单字节编码,通常每个字符占用一个字节。
仅支持128个基本ASCII字符。
2、UNICODE:
使用两个字节编码,允许表示更多字符,包括国际字符。
提供了对全球范围内字符的支持。
3、UNICODE BIG ENDIAN:
和Unicode相似,但是字节顺序是大端序,即高位字节在前。
4、UTF-8:
使用变长字节编码,一个字符可以由1至4个字节组成。
兼容ASCII,对英文字符使用一个字节,同时支持包括中文在内的多语言字符。
5、UTF-16LE:
使用两个字节编码,但是字节顺序是小端序,即低位字节在前。
6、UTF-16BE:
和UTF-16LE相似,但是字节顺序是大端序,即高位字节在前。
7、UTF-8 BOM(Byte Order Mark):
UTF-8编码中的一个特殊标记,占用三个字节(0xEF, 0xBB, 0xBF)。
用于标识文本文件使用了UTF-8编码,同时指定字节序。
这些编码方式中,ANSI、UNICODE和UTF-8是最常见的。UTF-8因为其灵活性和对多语言的支持,成为现代互联网中广泛使用的标准编码方式。UTF-16用于某些系统和应用,但在Web开发中并不常见。
BOM是可选的,不是所有UTF-8文件都包含BOM。在UTF-8编码文件中使用BOM可以帮助解释器识别编码方式,但有时也可能引起一些问题,因此在实际使用中需要注意。
由此可见,要特别注意UTF-8和UTF-8 BOM的区别,在win7以前的系统上,并不能识别出来,导致程序兼容性问题。如果用二进制打开文本文件,开头为:0xEF, 0xBB, 0xBF则为UTF-8 BOM格式。


![[Linux]HTTP状态响应码和示例](https://img-blog.csdnimg.cn/direct/836e694c716c4b6baddadb7099dbbeed.jpeg#pic_center)
![QT下载、安装详细教程[Qt5.15及Qt6在线安装,附带下载链接]](https://img-blog.csdnimg.cn/direct/3316a62492d74595bc895225d4fe73f4.png)