论文阅读笔记AI篇 —— Transformer模型理论+实战 (三)
- 第三遍阅读(精读)
- 3.1 Attention和Self-Attention的区别?
- 3.2 Transformer是如何进行堆叠的?
- 3.3 如何理解Positional Encoding?
- 3.x 文章涉及的其它知识盲区
第三遍阅读(精读)
精读的过程要把每个细节都钻研透,不留有死角。各种维度参数已经在“理论+实战(二)”中说清楚了,若之后还有疑问我再补上。
| 三、参考文章或视频链接 |
|---|
| [1] 【超强动画,一步一步深入浅出解释Transformer原理!】 |
3.1 Attention和Self-Attention的区别?
| 3.1 参考文章或视频链接 |
|---|
| [1] What’s the difference between Attention vs Self-Attention? What problems does each other solve that the other can’t? |
| [2] What’s the Difference Between Self-Attention and Attention in Transformer Architecture? |
3.2 Transformer是如何进行堆叠的?
原文提到了Encoder与Decoder是可以进行 N × N\times N× 堆叠的,那么堆叠之后的结构是什么?可以看到这就是堆叠之后的结构,这里的features是中间编码,6层decoder,每一层都需要拿features作为输入的一部分,这种设计思想也类似于ResNet。
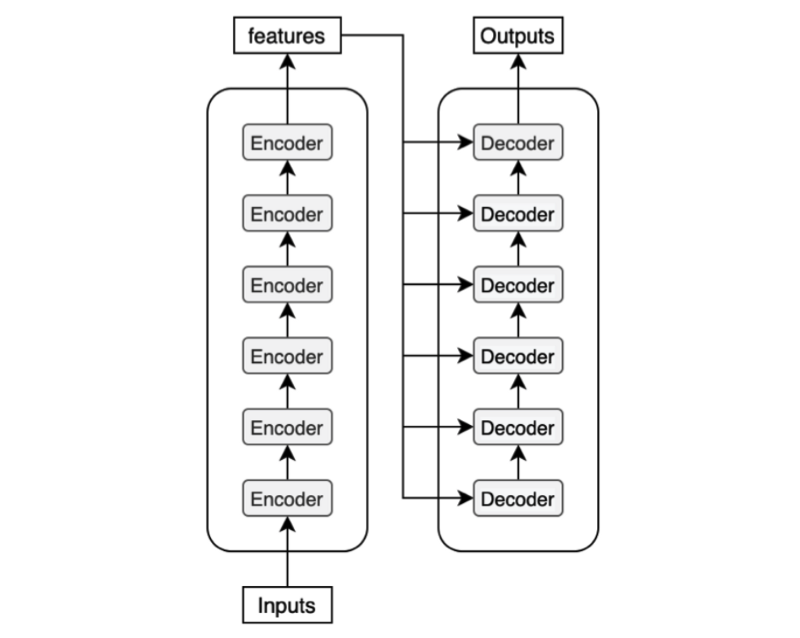
图1 —— 来自参考文章[1]
再看到原始的Transformer结构图中,对Outputs提到了一个(shifted right),这是什么意思?参考文章[4]中的动图诠释了这一点,shifted right是说不停的拿最新的预测词作为Outputs的输入,其实仔细想想,你写文章也绝对不可能是写下一个词语而不依赖上一句,一定是有前文的信息作为输入,才能让你流畅的写出下一个词语的,聊天在一定程度上就是拽着话头,话赶话。
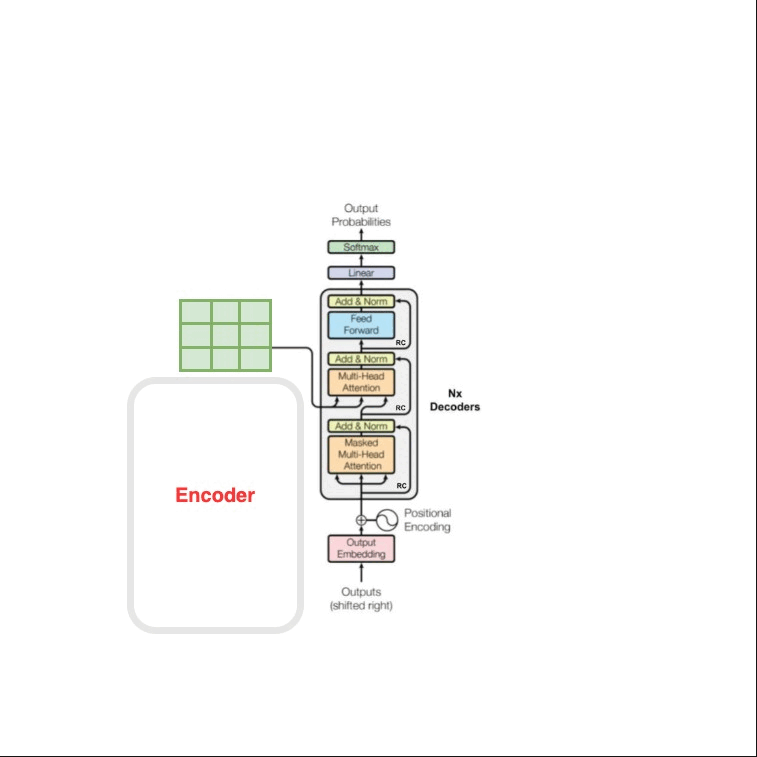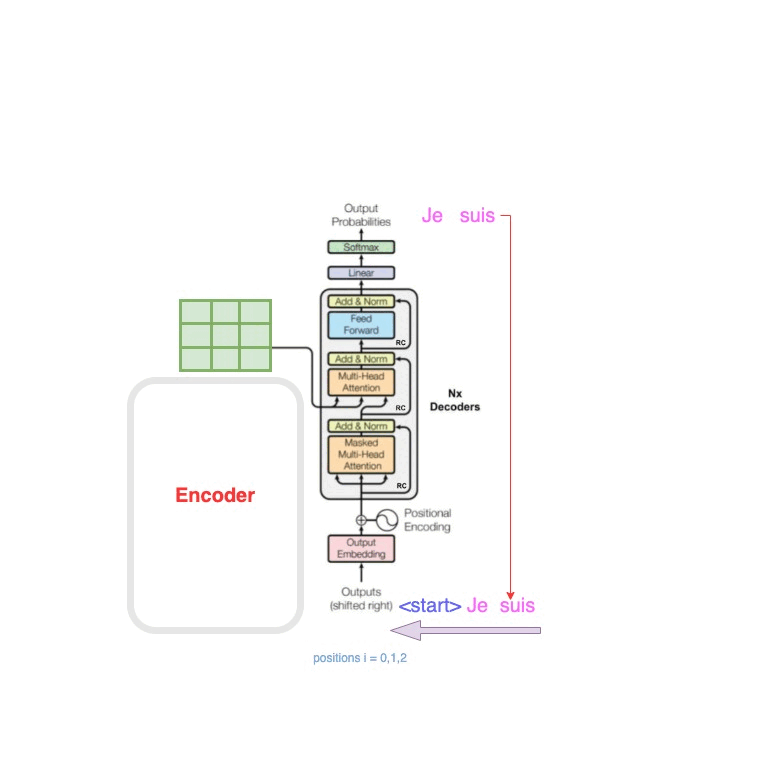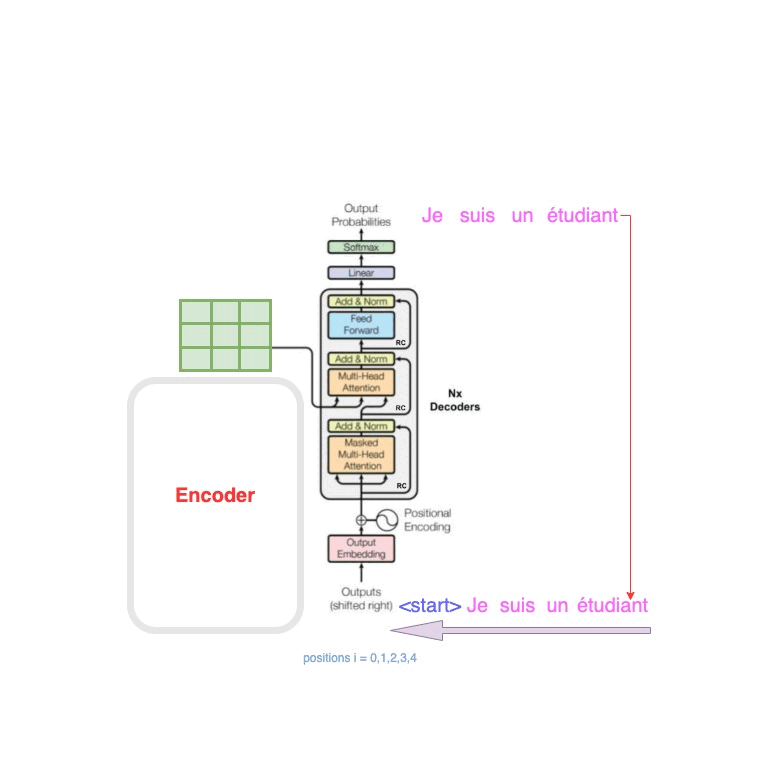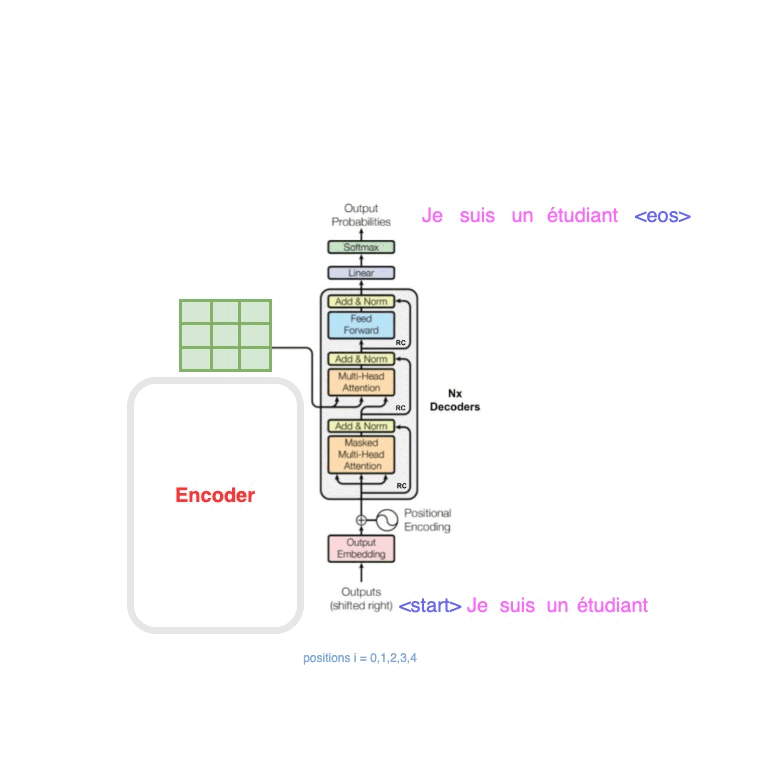
图2 —— 来自参考文章[4]
| 3.5 参考文章或视频链接 |
|---|
| [1] Transformer’s Encoder-Decoder Let’s Understand The Model Architecture |
| [2] What is purpose of stacking N=6 blocks of encoder and decoder in transformer? |
| [3] Stacked encoder and decoder blocks used in Transformers |
| [4] The Transformer Model - A Step by Step Breakdown of the Transformer’s Encoder-Decoder Architecture |
3.3 如何理解Positional Encoding?
“需要使用Positional Encoding的原因也很简单,因为 Transformer 摈弃了 RNN 的结构,因此需要一个东西来标记各个字之间的时序,换言之,也即位置关系,而这个东西,就是位置嵌入”[2],文章[2]又说,理想情况下,位置嵌入的设计应该满足以下条件:
- 它应该为每个字输出唯一的编码
- 不同长度的句子之间,任何两个字之间的差值应该保持一致
- 它的值应该是有界的
先来看到文章中的Positional Encoding公式:
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE(pos, 2i)=sin(\frac{pos}{10000^\frac{2i}{d_{model}}}) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE(pos, 2i+1)=cos(\frac{pos}{10000^\frac{2i}{d_{model}}}) PE(pos,2i+1)=cos(10000dmodel2ipos)
- d m o d e l = 512 d_{model}=512 dmodel=512是作者规定好的,代表编码长度。应该也可以修改的更长以提升性能?我不清楚,这里取何值较为合适呢?肯定有一个最优值。
- i i i 是指维度的下标,结合式子 2 i d m o d e l \frac{2i}{d_{model}} dmodel2i中的分母 d m o d e l d_{model} dmodel理解,应该有 i ∈ [ 0 , d m o d e l − 1 2 ] i \in [0, \frac{d_{model}-1}{2}] i∈[0,2dmodel−1],这是因为Word Embedding的维度大小是 d m o d e l d_{model} dmodel,所以为了Positional Embedding能与Word Embedding相加,肯定要能够一一对应。
p o s pos pos 为某句话中,这个Word所处的位置。
But using binary values would be a waste of space in the world of floats. 看英文原文有这么一句,
Positional Embedding 与 Word Embedding可以分开做concat拼接,但concat不一定有优势,初看这个东西我一定觉得作者在装神弄鬼,看完我理解了Positional Embedding的作用。
但是对于Word Embedding与Positional Embedding二者相加后,这个位置信息是如何体现出来的,则不甚明了,因为这就像两种颜色的墨水进行混合,Word Embedding是黑墨水,Positional Embedding是红墨水,两种数据直接相加就像把两种颜色的墨水混合到一起,那么要如何在相加之后的混合结果中体现Positional信息,则是我感到疑惑的。
Why do we mix two different concepts into the same multi-dimensional space? How can a model distinguish between word embeddings and positional encodings? [3] 两件毫不相干的事情怎么能相加到一个空间中,model要如何区分他们呢?
The model can learn to use the positional information without confusing the embedding (semantic) information. It’s hard to imagine what’s happening inside the network, yet it works. model可以在不混淆word embedding的情况下学到位置信息,你很难想象网络中究竟发生了,什么然而它就是工作了。然而,这是个什么解释? 所谓ai的黑箱模型,恐怕说的就是这一点,神经网络的拟合能力太过强大了,以至于我们都不知道内部究竟发生了什么。
| 3.6 参考文章或视频链接 |
|---|
| [1] Positional Encoding |
| 重点阅读:[2] 中文版:《Transformer 中的 Positional Encoding》 英文版:Transformer Architecture: The Positional Encoding |
| [3] Transformer’s Positional Encoding |
3.x 文章涉及的其它知识盲区
| 问题 | 总结 | 参考文章 |
|---|---|---|
| 什么是BLEU(Bilingual Evaluation Understudy,双语评估替换分数)? | 一种机器翻译任务的评价指标 | [1] 《BLEU详解》- 知乎 |