前言
随着人工智能技术的飞速发展,语义表征和检索增强生成(Retrieval Augmented Generation, RAG)在各个领域的应用日益广泛。在这样的背景下,网易有道推出了划时代的BCEmbedding模型,这不仅是一次技术的革新,更是跨语种检索和RAG领域的一次重大突破。
-
Huggingface模型下载:https://huggingface.co/maidalun1020/bce-embedding-base_v1
-
AI快站模型免费加速下载:https://aifasthub.com/models/maidalun1020
主要特点
-
双语和跨语种能力:基于有道翻译引擎的强大能力,
BCEmbedding实现强大的中英双语和跨语种语义表征能力。 -
RAG适配:面向RAG做针对性优化,可适配大多数相关任务,比如翻译,摘要,问答等。此外,针对 问题理解(query understanding) 也做了针对优化。
-
高效且精确的语义检索:
EmbeddingModel采用双编码器,可以在第一阶段实现高效的语义检索。RerankerModel采用交叉编码器,可以在第二阶段实现更高精度的语义顺序精排。 -
用户友好:语义检索时不需要特殊指令前缀。也就是,你不需要为各种任务绞尽脑汁设计指令前缀。
-
有意义的重排序分数:
RerankerModel可以提供有意义的语义相关性分数(不仅仅是排序),可以用于过滤无意义文本片段,提高大模型生成效果。 -
产品化检验:
BCEmbedding已经被有道众多产品检验。
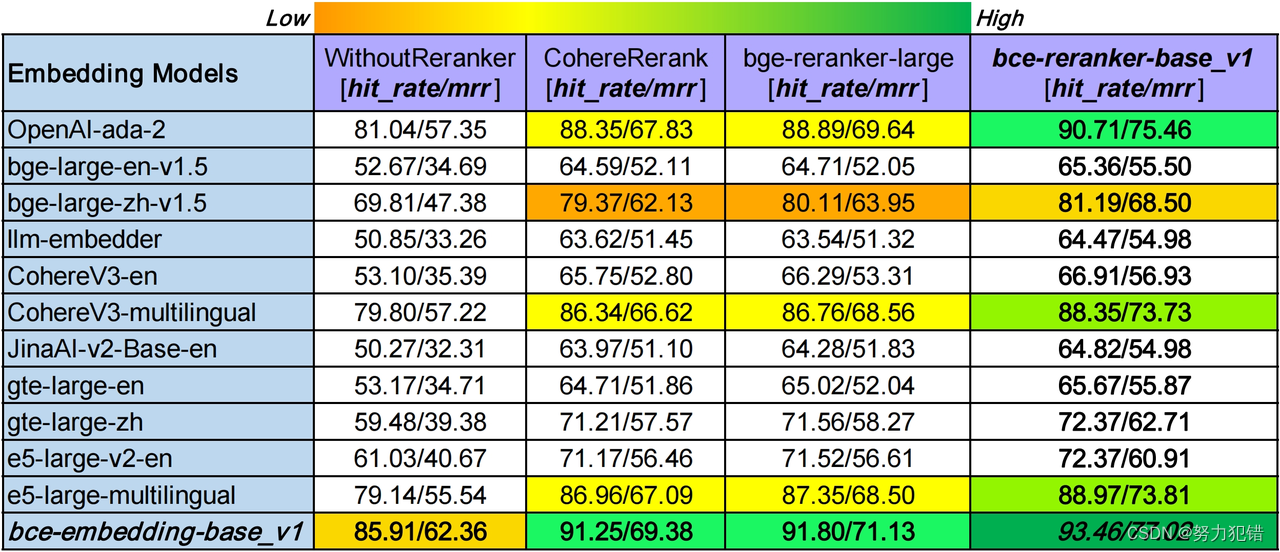
BCEmbedding的核心优势
双语和跨语种能力的突破
BCEmbedding最引人注目的特点之一就是其强大的双语和跨语种能力。它不仅支持中文和英文的语义表征,还能有效处理中英跨语种的任务。这一能力的背后,是网易有道翻译引擎的强大支持。在实际应用中,这意味着无论是中文还是英文的文本输入,BCEmbedding都能提供准确的语义理解和高效的检索能力。
针对RAG的专门优化
RAG作为近年来AI领域的热门话题,其在教育、法律、金融、医疗等多个领域都有广泛的应用前景。BCEmbedding在这方面进行了专门的优化,以适应更多真实业务场景。不仅如此,它还能够提供更准确的问题理解,这对于提高RAG任务的效果至关重要。
BCEmbedding的技术细节
BCEmbedding由两部分构成:EmbeddingModel和RerankerModel。EmbeddingModel负责生成语义向量,主要用于语义搜索和问答任务;而RerankerModel则擅长优化语义搜索结果和精确排序。
-
EmbeddingModel采用了双编码器结构,使得它在第一阶段就能实现高效的语义检索。这对于处理大量数据、快速响应用户查询请求尤为重要。

-
RerankerModel则采用交叉编码器结构,它能在第二阶段进行更深入的语义分析和精确的顺序排列。这一特性使得BCEmbedding在处理复杂的语义理解任务时更加高效和准确。

BCEmbedding的应用场景
网易有道的BCEmbedding已经在多个产品中得到了成功应用,如有道速读和有道翻译。它不仅在提升产品性能方面发挥了巨大作用,也为用户带来了更加流畅和准确的使用体验。此外,BCEmbedding还为开发者提供了便捷的集成方案,使其能够轻松融入现有的AI解决方案中。
BCEmbedding的未来展望
随着AI技术的不断进步,BCEmbedding在双语和跨语种领域的领先地位将会更加巩固。未来,它不仅将在更多领域发挥作用,还将推动整个RAG技术的发展,为用户和企业带来更多的可能性。
在这个信息爆炸的时代,BCEmbedding的出现无疑为我们提供了一个更加高效、准确的信息检索和处理工具。它的成功,不仅仅是技术上的突破,更是对未来AI应用场景的一种探索和展望。
模型下载
Huggingface模型下载
https://huggingface.co/maidalun1020/bce-embedding-base_v1
AI快站模型免费加速下载
https://aifasthub.com/models/maidalun1020