谷歌DeepMind的研究人员推出了一款,通过视觉语言模型进行场景理解,并使用大语言模型来发出指令控制实体机器人的模型——AutoRT
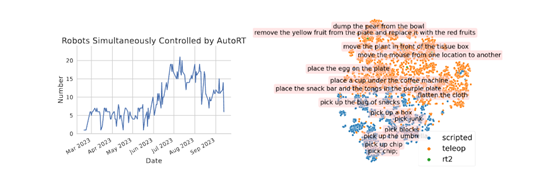
AutoRT可有效地推理自主权和安全性,并扩大实体机器人学习的数据收集规模。在实验中,AutoRT指导超过20个实体机器人执行指令,并通过远程操作和自主机器人策略收集了77,000个真实机器人操作的片段。
这充分说明,AutoRT收集的机器人操作数据更加多样化,并且在大语言模型的帮助下AutoRT可以轻松实现与人类偏好相一致的机器人行为指令,该模型对于训练实体机器人帮助巨大。
论文地址:https://auto-rt.github.io/static/pdf/AutoRT.pdf

大语言模型是AutoRT的核心组建之一,充当机器人的指挥“大脑”,根据用户的提示和环境条件为一个或多个机器人提供任务指令,主要包括环境探索、任务生成、自主行为和行为过滤四大模块。
环境探索
负责让机器人在环境中寻找适合操作的场景。该模块使用了视觉语言模型构建环境地图,识别并定位各个对象。
然后根据对象特征采样导航目标,引导机器人驶向潜在的操作场景。这使得AutoRT可以无需事先了解环境布局就进行部署。
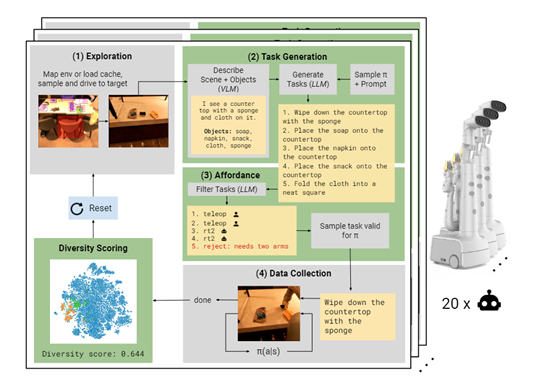
简单来说,就是让机器人自己在房间、办公室等环境进行自行操作和观察,到处看看有啥可以操作的东西。它会先把当前环境里的桌子、杯子这些物体定位好,明确具体的坐标,方便以后的动作指令操作。
任务指令生成
首先使用视觉语言模型描述当前场景和环境中的对象,然后将这些文字描述输入大语言模型,生成机器人可以执行的一系列操作任务指令。
任务生成考虑不同的数据收集策略,为它们各自生成适配的任务列表。此外,任务生成过程中还内嵌了“机器人约束”,定义了机器人需要遵守的基本规则、安全规则和具体约束,确保任务的安全性和合理性。
自主执行
在任务执行阶段,机器人根据生成的任务执行计划来执行具体的操作。机器人可以根据需要执行自主策略,如通过路径规划和运动控制来移动和操作物体。
此外,机器人还可以通过与人类操作员进行通信来执行任务。在需要人类干预或指导的情况下,机器人可以向操作员发送请求或询问,并根据操作员的指示进行相应的操作。
自主执行的目标是使机器人能够在不同环境和任务下独立运行,并从中获取丰富的数据。
行为指令过滤
主要对任务生成的输出进行再次筛选,移除不安全或不合理的任务。该模块同样基于大语言模型,将生成的任务及可选的数据收集策略作为输入,同时输出每个任务指令所匹配的策略或拒绝理由。

可以把这个模块看成是一个自我反思的过程,大语言模型对自己生成的内容进行纠错和修正,提升整体的安全性能。
通过以上4大模块的协同工作,AutoRT能够在真实世界的不同环境中快速收集大规模、多样化的机器人数据。
相比于传统的数据收集方法,AutoRT利用先进的视觉感知和语言模型技术,使机器人能够在未知的情境下自主决策并执行任务,从而最大限度地提高数据收集的效率和安全性。
此外,AutoRT还支持与人类操作员的交互,使机器人能够在需要时获取人类的帮助和指导。
本文素材来源AutoRT论文,如有侵权请联系删除
END