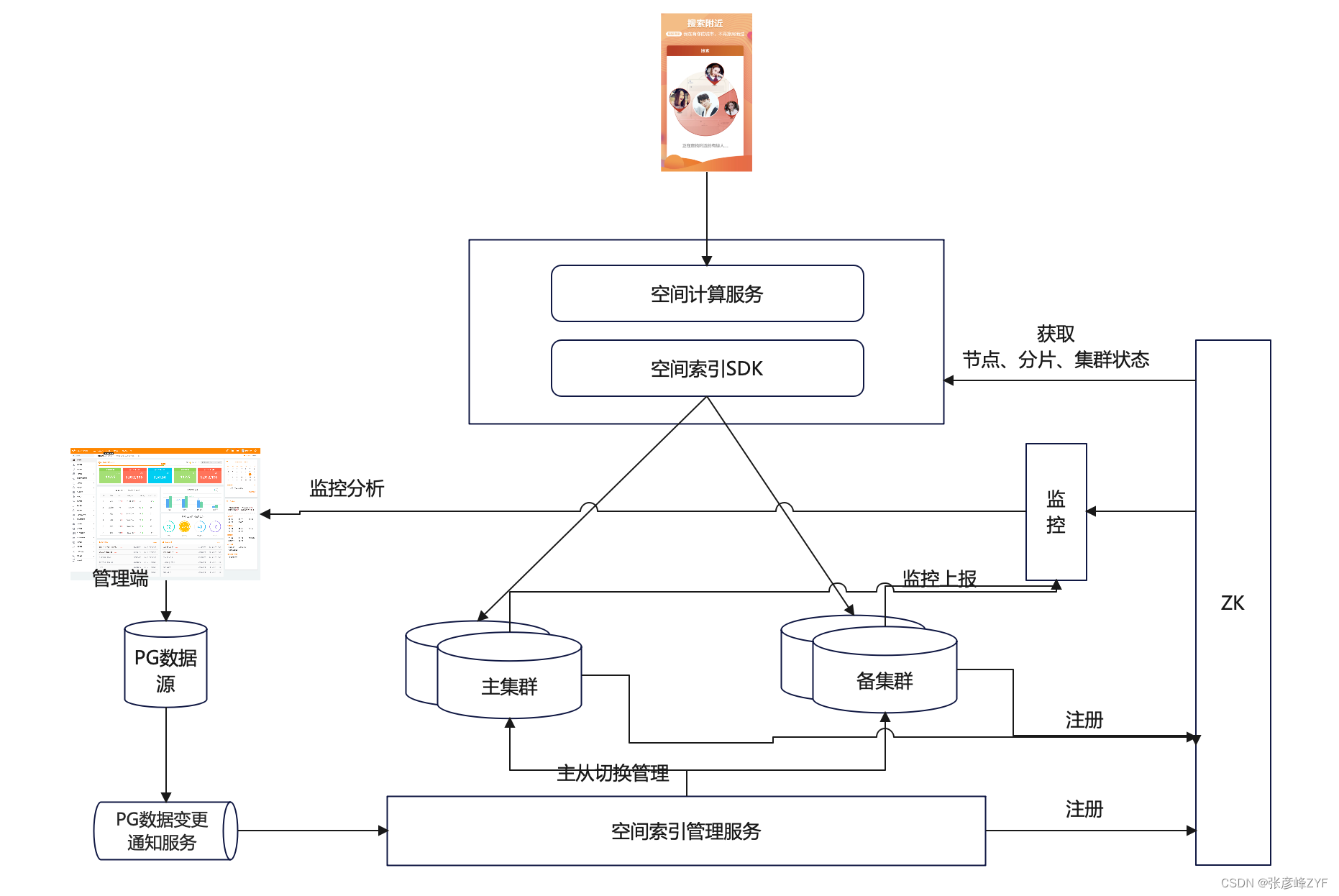
1: 问题描述与要求
《纽约时报》要求您对本文件中的结果进行分析,以回答几个问题。
问题1:报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。这个词的任何属性是否会影响报告的在困难模式下播放的分数的百分比?如果是这样,如何?如果不是,为什么不呢?
问题2:对于未来日期的给定未来解决方案词,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期 (1, 2, 3, 4, 5, 6, X) 的相关百分比。哪些不确定性与您的模型和预测相关?举一个你对2023年3月1日EERIE这个词的预测的具体例子。你对你的模型的预测有多自信?
问题3:开发并总结一个模型来按难度对解决方案单词进行分类。识别与每个分类关联的给定词的属性。使用您的模型,EERIE这个词有多难?讨论分类模型的准确性。
问题4:列出并描述这个数据集的其他一些有趣的特征。
2: 解题思路和分析结果(详解版)
针对问题1
思路:该问题主要是预测一个序列的变化趋势,而且该数据的变化趋势是统计的每天的数据,所以可认为是一个时间序列。数据的波动如下:

待预测数据的波动情况
分析该数据的随时间的变化趋势,可以发现是先上升、然后在下降的趋势,比较符合一个热点产生后,迅速得到关注,然后在逐渐降低热度,最后关注度保持稳定的情况。
针对该数据中末尾的最低点如何处理:该点可能是正确的数据(也可能是错误的,比如:录入错误)。所以可以做处理,也可以不错处理。处理方法,最简单的方法是使用最低点前后N(n=1,2,...)个数值的均值进性改进。
针对序列的预测方法:
(1)时间序列累预测方法:建议忽略到前半段,对下降的趋势进行时间序列建模与分析(也可用群不数据),可能效果较好。模型可以是:ARIMA、prophet等预测算法,prophet效果会好于ARIMA。
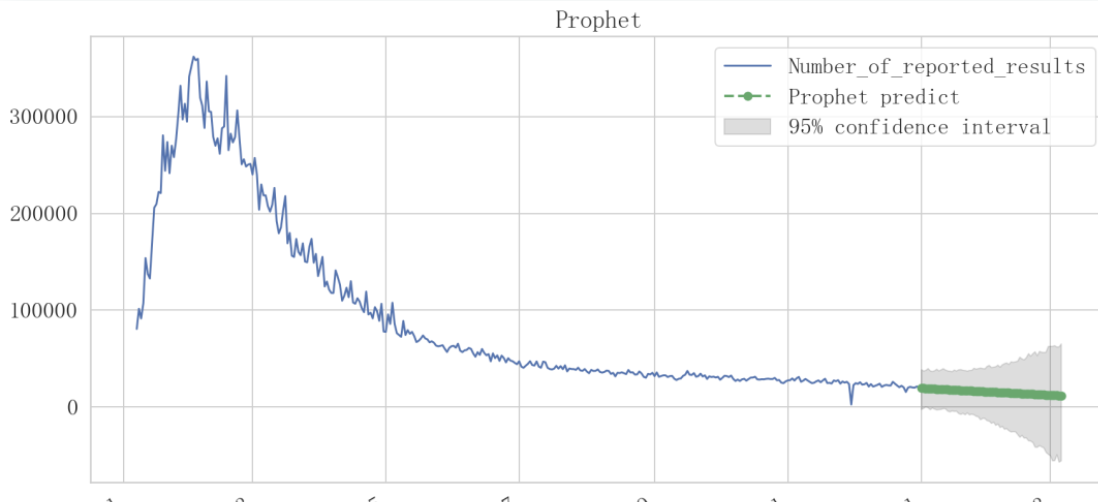
prophet算法预测
(2)考虑非线性回归方程:可以使用全部的数据建立,也可以使用数据下降趋势的后半段。

非线性回归方程
对于分析词的任何属性是否会影响报告的在困难模式下播放的分数的百分比的情况。主要的检验方法就是单因素方差分析,而且也要对词语一行清洗与与处理的改正操作。
针对问题2
目的1: 预测未来日期 (1, 2, 3, 4, 5, 6, X) 的相关百分比。
目的2: 对2023年3月1日EERIE这个词进行预测。
该问题是一个典型的有监督的数据回归问题,可以使用的方法有很多,而且针对数据的情况,可以先对数据进行特征工程,可以使用的特征例如:时间信息、每个位置的字母信息、词的属性信息等。可使用的预测算法也很多,例如:决策树、随机森林、GBDT、SVM、神经网络等。经过我的验证,使用随机森林或者GBDT的预测效果较好。
在数据与处理操作阶段,可以剔除一个累计正确率较离谱的样本,入下面的图所示:
累计正确率
对2023年3月1日EERIE这个词,一个可以参考的预测结果为:
(1, 2, 3, 4, 5, 6, X) 的相关百分比预测值分别为 (1, 5, 17, 32, 27, 12, 3)
针对问题3
目的1: 按难度对解决方案单词进行分类,并且根据单词的相关特征,为分类结果进行定级。
目的2: 对2023年3月1日EERIE这个词进行预测。
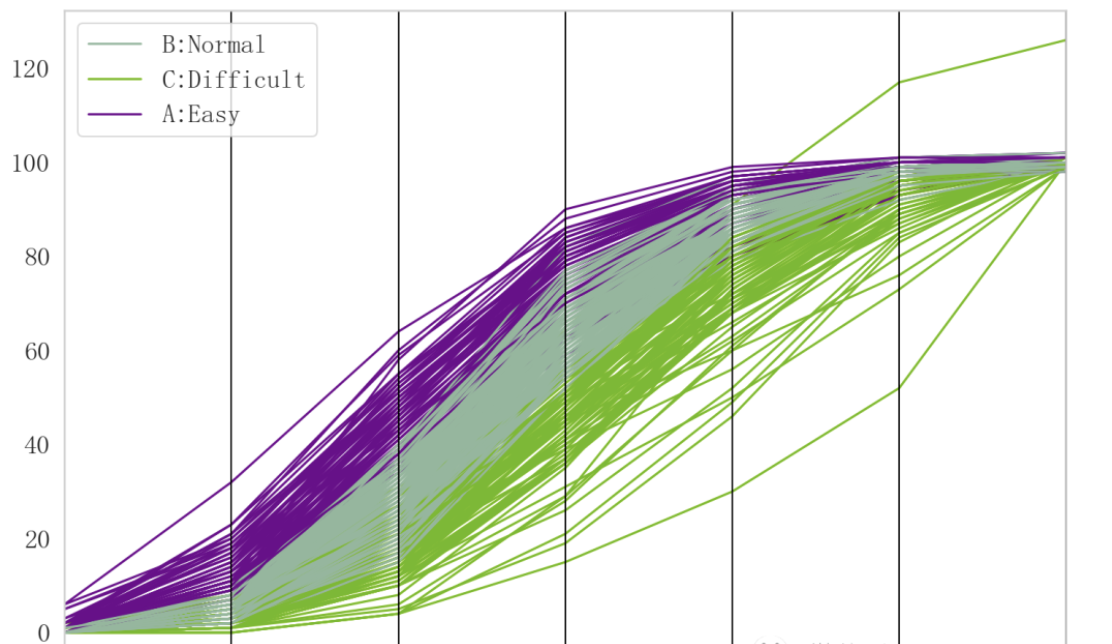
该问题属于一个无监督的聚类问题。而且针对该问题进行聚类是,使用的特征很关键。可以使用(1, 2, 3, 4, 5, 6, X) 的相关百分比作为特征建立聚类模型,而且聚类的算法有很多,例如:K均值、K中值、模糊聚类、系统聚类等。而且聚类的数量也有讲究。经过我的详细研究,聚类为3类,可能效果跟好一些。

聚了i结果可视化
聚类模型确定好后,对EERIE这个词进行预测即可。
针对问题4
该问题是一个开放性的问题,可以进行一些数据可视化分析等,便于发现数据的关系。并且可以结合前面三问的到的结果进行分析。例如:使用关联规则,可以发现单词中有哪些字母的情况下,属于哪个难度类别等。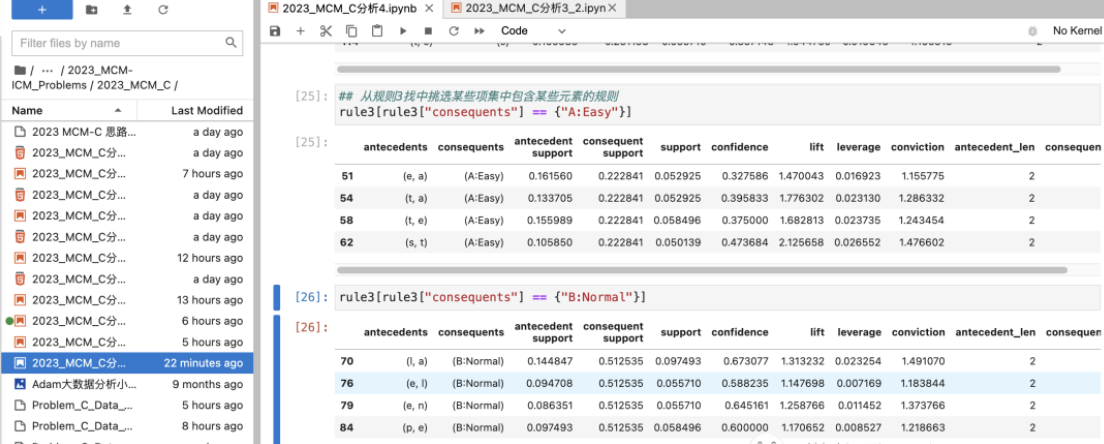
发现的一些规则
总结
前面的一些分析,都是本人使用Python,对数据一步步分析得出的一些经验,供大家参考,并不能完全保证是正确的。数学建模本身就是开放性问题,这里知识抛砖引玉。