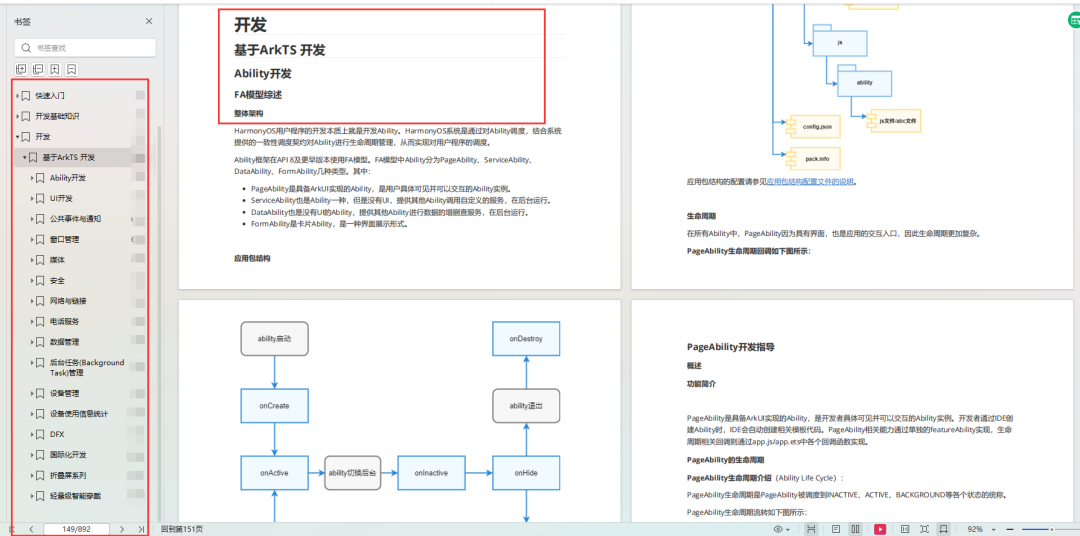
2-7 门控循环单元(GRU)_哔哩哔哩_bilibili

GRU LSTM


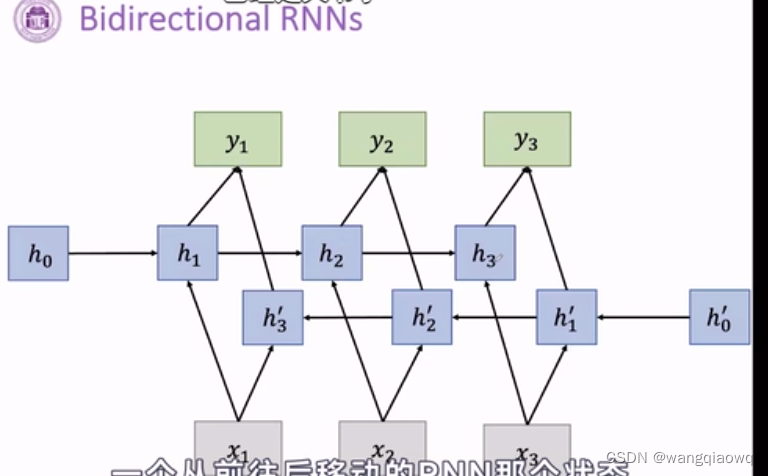
双向RNN
CNN 卷积神经网络
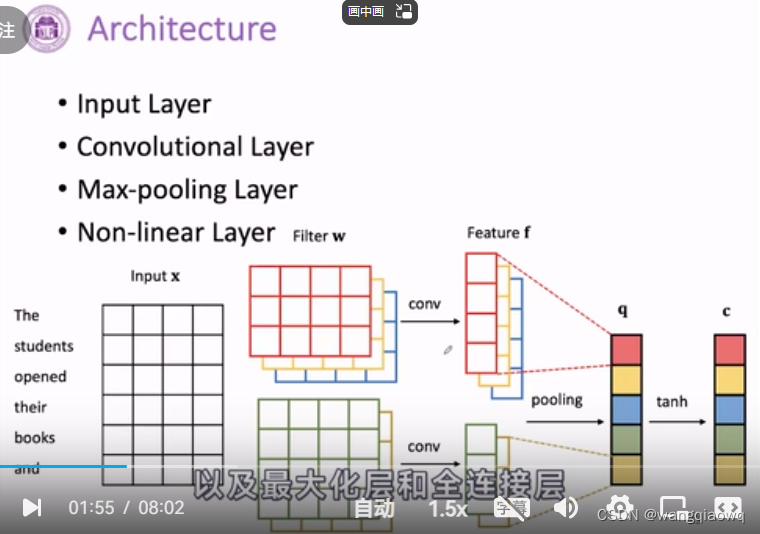
输入层 转化为向量表示



dropout
ppl



标量
在物理学和数学中,标量(Scalar)是一个只有大小、没有方向的量。它只用一个数值就可以完全描述,且满足交换律。例如,质量、温度、时间、体积、密度、功、能量等都是标量。
在向量代数中,标量与向量是相对的概念,标量可以与向量相乘,从而改变向量的长度但不改变其方向。例如,在三维空间中,如果一个向量的长度为3,一个标量为2,那么这个标量乘以向量的结果将得到一个长度为6,方向不变的新向量。

注意力分数
隐向量
隐向量(Latent Vector)是机器学习和深度学习中一个重要的概念,特别是在自然语言处理、推荐系统、图像识别等领域。隐向量是用来表示复杂数据的一种低维实数向量,它通过训练学习到的,并试图捕捉原始高维数据中的潜在结构和语义信息。
在推荐系统中:
- 隐向量通常用来表示用户和物品(如电影、音乐等),每个用户和每件物品都被映射到一个固定维度的向量空间中。
- 例如,在因子分解机(FM,Factorization Machines)模型中,各个特征(比如用户ID或商品ID)对应的隐向量可以通过矩阵分解得到,这些隐向量的内积可以用来预测用户对商品的评分或者偏好。
在自然语言处理中:
- 单词或文档也可以用隐向量来表示,这种表示方法常被称为词嵌入(Word Embeddings),如Word2Vec、GloVe等模型生成的向量。
- 这些隐向量可以捕获单词之间的语义相似性,使得在向量空间中距离相近的单词具有类似的含义。
在深度学习架构中:
- 在神经网络中,Embedding层就是用来将离散的高维输入(如one-hot编码)转换为连续的低维隐向量,以便进行后续的计算和模式挖掘。
总的来说,隐向量是一种压缩和抽象的表示形式,它有助于模型理解和处理高维稀疏数据,并能够发现数据内部隐藏的模式和联系。

softmax函数是一种在机器学习和深度学习中广泛使用的归一化指数函数,主要用于多分类问题的输出层计算预测类别概率分布。

激活函数
注意力机制解决信息瓶颈问题
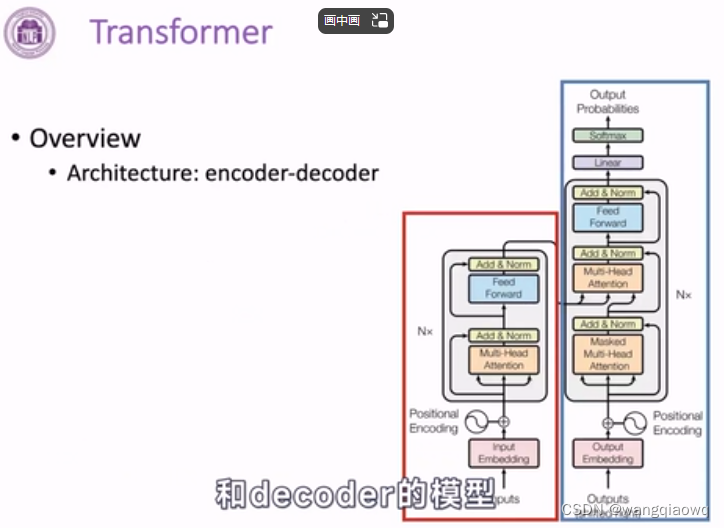
Transformer
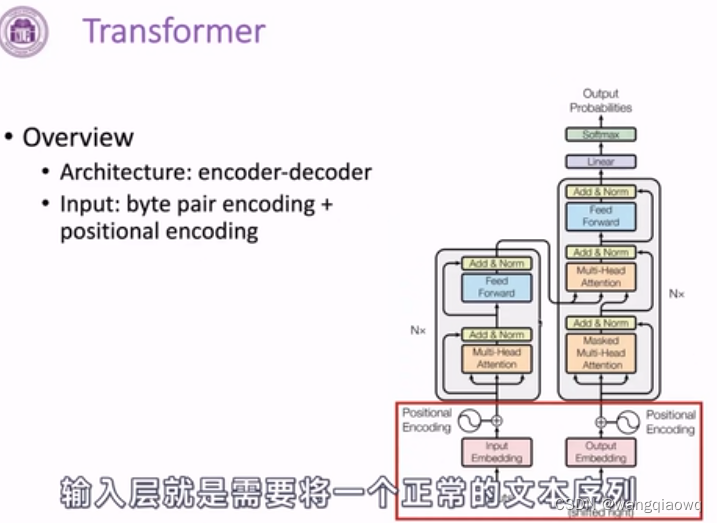
BPE
交叉熵





正则化

加权平均是一种统计方法,用于计算一组数值的平均值时,考虑到每个数值的重要性(权重)不同。在普通平均数中,所有数据点都同等重要,而在加权平均中,每个数据点有一个与其对应的权重值,这个权重反映了该数据点在最终结果中的相对影响程度。
加权平均的计算公式为:
加权平均数=∑(每个数据值×对应权重)∑(所有权重)加权平均数=∑(所有权重)∑(每个数据值×对应权重)
例如,在学校教育场景中,一个学生的学期总评成绩可能由平时测验、期中考试和期末考试的成绩按不同比例(权重)综合得出:
- 平时测验:80 分,权重 20%
- 期中考试:90 分,权重 30%
- 期末考试:95 分,权重 50%
那么,该学生的学期总评成绩可以通过以下步骤计算:
学期总评成绩=(80×0.2)+(90×0.3)+(95×0.5)0.2+0.3+0.5学期总评成绩=0.2+0.3+0.5(80×0.2)+(90×0.3)+(95×0.5)
此外,在财务领域,加权平均法常用于库存管理,计算存货的单位成本。例如,考虑一段时间内多次购入商品的情况,每次购入的数量和单价不同,这时会根据各批次进货的数量(作为权重)和其相应的单价来计算整个库存的平均单位成本。
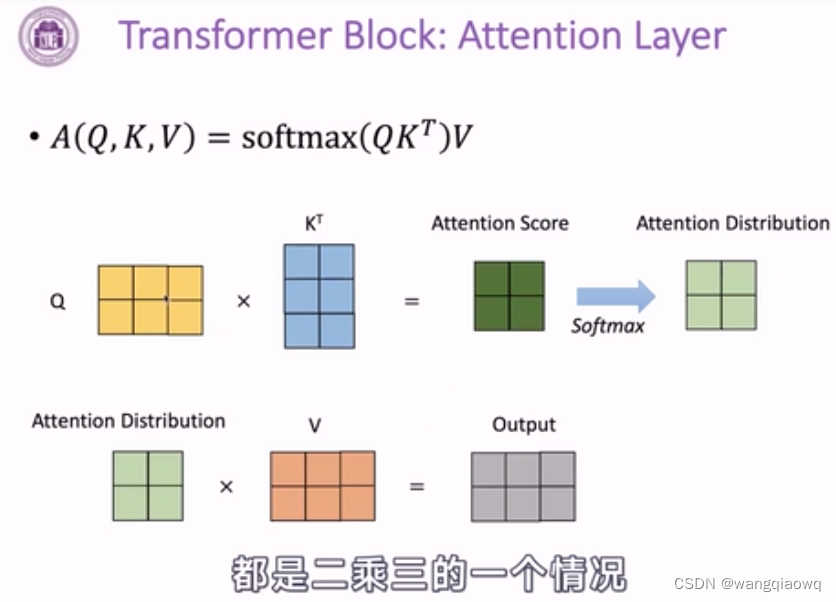


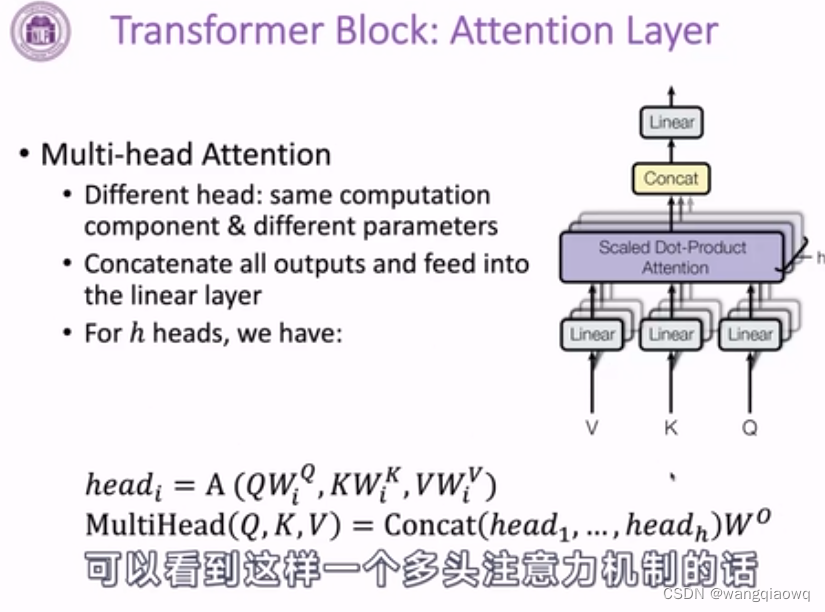




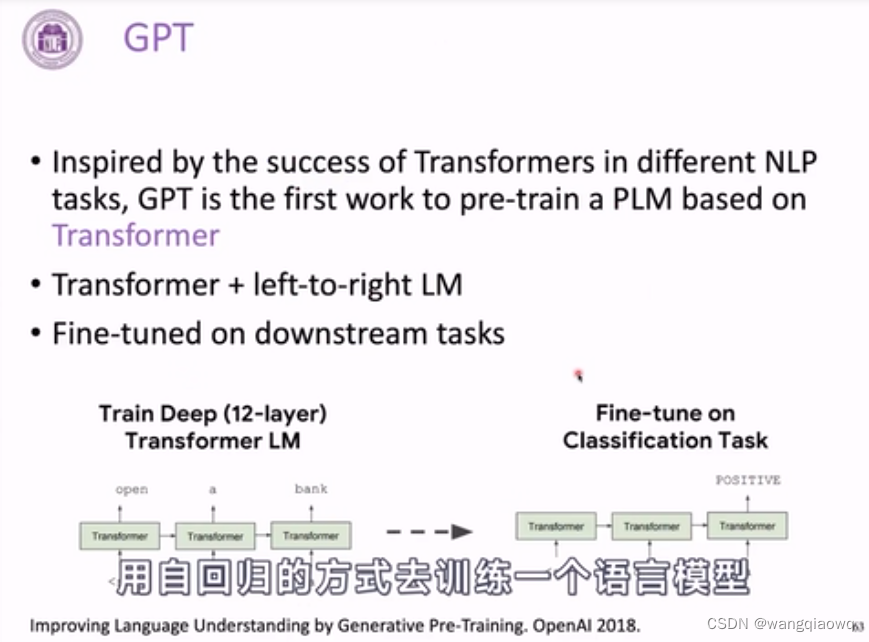




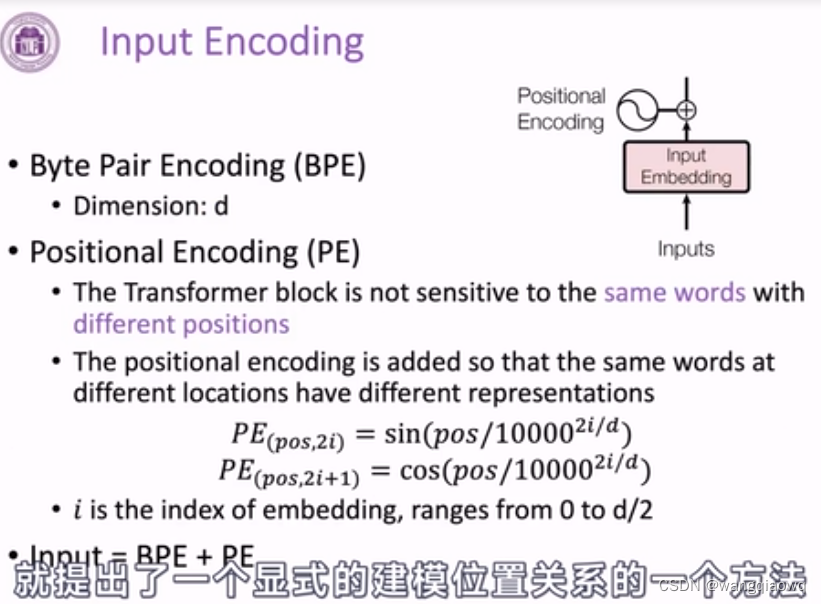
3-13 预训练语言模型--PLM介绍_哔哩哔哩_bilibili

预训练

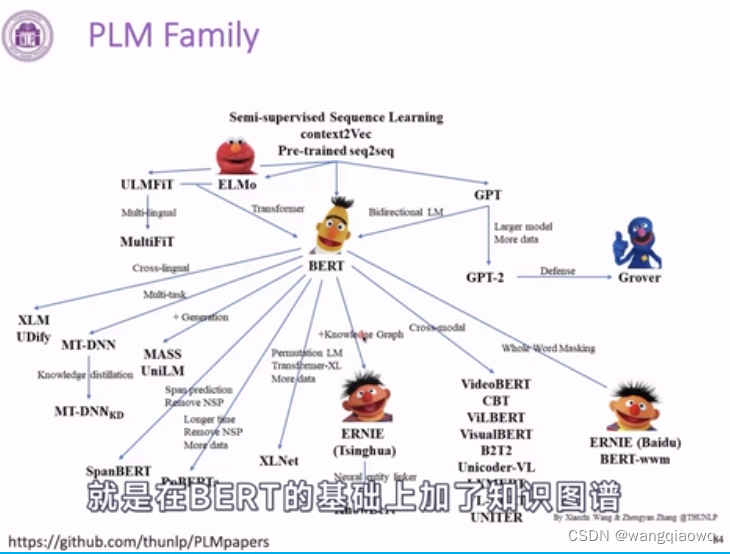
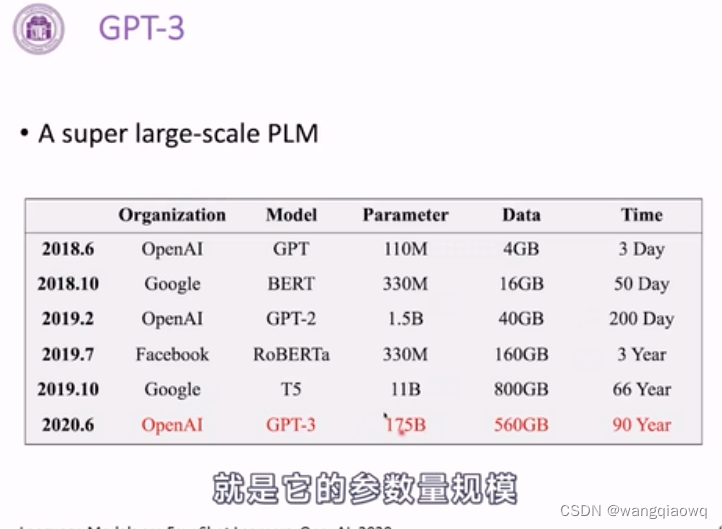

预训练语言模型
Transformers

PyTorch
fine-tune
“微调”(fine-tune)的具体含义略有不同,但核心都是对已有的事物进行精细化调整和优化:
-
在机器学习和人工智能领域,微调通常是指对预训练模型的参数进行进一步调整。例如,在深度学习中,我们可能首先采用一个已经在大规模数据集上预训练好的模型,然后将其应用到特定任务上时,针对这个特定任务的数据进行再次训练,通过调整部分或全部模型参数,使得模型能够更好地适应新任务的需求,从而提升模型在新任务上的性能。


load metric
3-20 Transformers教程--Demo讲解_哔哩哔哩_bilibili 重点看下
4-1 课程内容介绍_哔哩哔哩_bilibili



4-2 Prompt-Learning和Delta-Tuning--背景和概览_哔哩哔哩_bilibili

representation
在自然语言处理(NLP)和机器学习中,representation(表示法或表征)特指将语言中的单词、短语、句子或文档转化为计算机可以理解与操作的形式。这个过程是模型理解和生成自然语言的关键步骤。
在语言模型中,representation通常是指:
-
词嵌入(Word Embedding):这是一种将每个单词映射到一个固定维度向量空间的技术,如Word2Vec、GloVe或BERT等预训练模型所生成的词向量,使得语义相近的词在向量空间上距离较近。
-
上下文相关的表示(Contextual Representation):比如Transformer架构中的BERT和GPT系列模型产生的表示,它们不仅能捕捉单个词的一般含义,还能考虑词语在具体上下文环境下的含义变化,生成动态的上下文嵌入。
这些表示被用于各种下游NLP任务,如情感分析、命名实体识别、问答系统等,通过学习到的有效数据表示,模型能够更好地理解和推断文本信息。
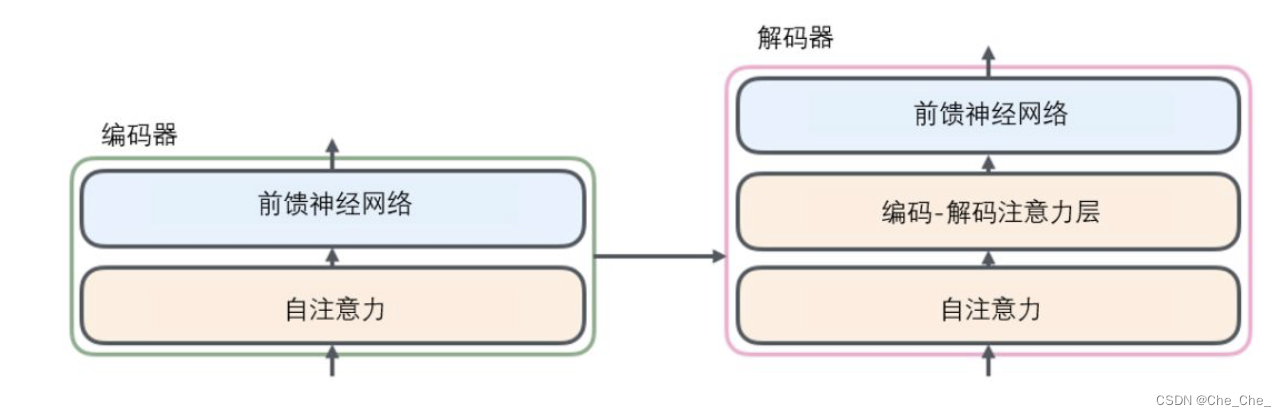
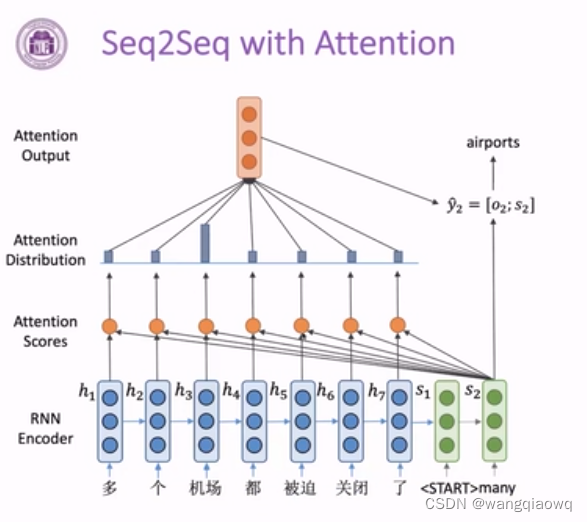
sequence to sequence
Sequence to Sequence(简称Seq2Seq)是一种在自然语言处理和机器学习领域广泛应用的模型架构,主要用于处理输入和输出都是变长序列的任务。中文可以解释为“序列到序列”或“顺序到顺序”。
具体来说,Seq2Seq模型设计用于将一个输入序列(比如一段文本)通过神经网络转换成另一个不同长度的输出序列(比如翻译后的另一段文本)。这种模型通常包含两个主要部分:编码器(Encoder)和解码器(Decoder)。
-
编码器负责读取并理解输入序列的信息,并将其压缩成一个固定维度的向量(称为上下文向量),这个向量包含了输入序列的整体语义信息。
-
解码器则依据该上下文向量逐步生成目标序列,每次生成一个元素(如一个词或子词单元),直到生成结束标记或者达到预设的最大长度。
Seq2Seq模型常应用于机器翻译、文本摘要、对话系统、语音识别转文字等场景中。随着注意力机制(Attention Mechanism)的发展,Seq2Seq模型能够更灵活地处理源序列和目标序列之间的依赖关系,进一步提升模型性能。




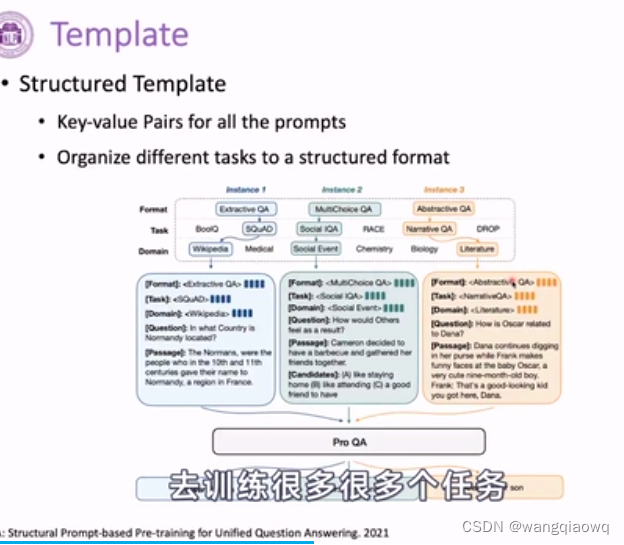
在自然语言处理和机器学习的上下文中,“trigger”这个词有多重含义:
-
事件触发词:在信息抽取或情感分析等领域,触发词(Trigger)是指引起特定事件发生的词语。例如,在识别文本中的“灾害事件”,“发生”、“爆发”等词可能是表示灾害开始的触发词。
-
条件触发器:在自动化流程或者智能系统中,触发器(Trigger)指的是一种当满足特定条件时启动某个操作或过程的机制。例如,在数据库中,一个时间触发器会在特定时间点执行预设的SQL脚本。
-
心理触发:在心理学上,触发(Trigger)可能指的是某些刺激因素,它们能够激发个体的情绪反应、记忆或者其他心理状态。
-
对话系统触发:在构建对话系统时,触发也可以指代用户话语中引导系统进行某种响应的部分,比如特定命令词或问题类型。
根据不同的语境,触发(Trigger)的具体意义会有所不同。
在自然语言处理中,"positive"(积极的、正面的)通常用于描述文本的情感倾向或评价。例如,在情感分析任务中,如果一段文本被标记为“positive”,则表示这段文字传达了积极的情绪、正面的态度或者对某个主题给予了肯定评价。
另外,在机器学习和数据分析中,“positive”也可能指代一个实例所属的类别标签,比如在疾病诊断问题中,“positive”可能意味着测试结果呈阳性,即存在某种病症。
而在日常对话或写作中,“positive”一词也常常用来鼓励乐观态度、积极思维和正向行为。
在自然语言处理(NLP)领域中,embedding(嵌入、词嵌入或向量化)是指将文本中的单词、短语或者整个句子映射到一个低维连续向量空间的技术。这种向量空间通常被称为嵌入空间,其中每个词汇都有一个对应的向量表示。
通过embedding技术,原本离散的文本数据转换为数值型数据,使得机器学习和深度学习模型能够理解并处理自然语言。这些向量代表了词语在上下文环境中的语义特征,相似含义的词语在向量空间中的距离会比较接近,从而让模型能够捕捉词汇间的语义关系。
例如,在Word2Vec、GloVe等词嵌入方法中,通过训练可以得到每个词的向量表示。而在更复杂的模型如BERT、Transformer等中,不仅考虑单个词的嵌入,还引入了位置编码,并生成上下文相关的词嵌入,进一步提升了对文本理解的能力。



4-8 Prompt-Learning--应用_哔哩哔哩_bilibili




![[机器学习]简单线性回归——梯度下降法](https://img-blog.csdnimg.cn/direct/87a9d033ecfa4544a34c1b4261c32d75.png)