概述
分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具
什么是分词器
顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Analysis
是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。
举一个分词简单的例子:比如你输入 Mastering Elasticsearch,会自动帮你分成两个单词,一个是 mastering,另一个是 elasticsearch,可以看出单词也被转化成了小写的。
分词器的构成
分词器是专门处理分词的组件,分词器由以下三部分组成:
character filter
接收原字符流,通过添加、删除或者替换操作改变原字符流
例如:去除文本中的html标签,或者将罗马数字转换成阿拉伯数字等。一个字符过滤器可以有零个或者多个
tokenizer
简单的说就是将一整段文本拆分成一个个的词。
例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现。在一个分词器中,有且只有一个tokenizeer
token filters
将切分的单词添加、删除或者改变
例如将所有英文单词小写,或者将英文中的停词a删除等,在token filters中,不允许将token(分出的词)的position或者offset改变。同时,在一个分词器中,可以有零个或者多个token filters.
分词顺序
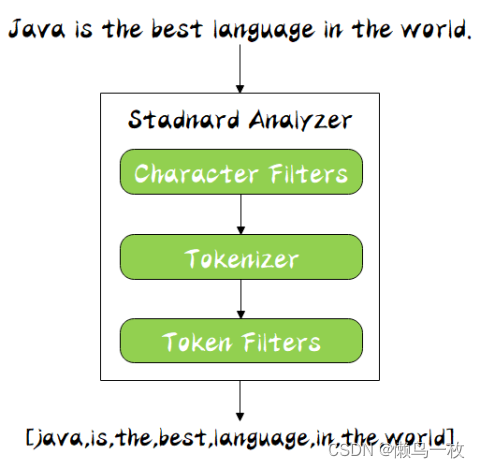
同时 Analyzer 三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters,Tokenizer 以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
索引和搜索分词
文本分词会发生在两个地方:
- 创建索引:当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。
- 搜索:当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
配置分词器
默认ES使用standard analyzer,如果默认的分词器无法符合你的要求,可以自己配置
分词器测试
可以通过_analyzerAPI来测试分词的效果。
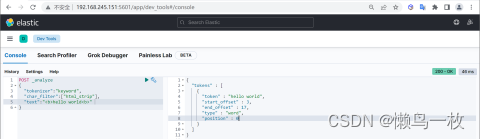
COPY# 过滤html 标签
POST _analyze
{"tokenizer":"keyword", #原样输出"char_filter":["html_strip"], # 过滤html标签"text":"<b>hello world<b>" # 输入的文本
}
指定分词器
使用地方
分词器的使用地方有两个:
- 创建索引时
- 进行搜索时
创建索引时指定分词器
如果手动设置了分词器,ES将按照下面顺序来确定使用哪个分词器:
- 先判断字段是否有设置分词器,如果有,则使用字段属性上的分词器设置
- 如果设置了analysis.analyzer.default,则使用该设置的分词器
- 如果上面两个都未设置,则使用默认的standard分词器
字段指定分词器
为title属性指定分词器
PUT my_index
{"mappings": {"properties": {"title":{"type":"text","analyzer": "whitespace"}}}
}
指定默认default_seach
COPYPUT my_index
{"settings": {"analysis": {"analyzer": {"default":{"type":"simple"},"default_seach":{"type":"whitespace"}}}}
}
内置分词器
es在索引文档时,会通过各种类型 Analyzer 对text类型字段做分析,
不同的 Analyzer 会有不同的分词结果,内置的分词器有以下几种,基本上内置的 Analyzer 包括 Language Analyzers 在内,对中文的分词都不够友好,中文分词需要安装其它 Analyzer
| 分析器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| standard | 标准分析器是默认的分析器,如果没有指定,则使用该分析器。它提供了基于文法的标记化(基于 Unicode 文本分割算法,如 Unicode 标准附件 # 29所规定) ,并且对大多数语言都有效。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] |
| simple | 简单分析器将文本分解为任何非字母字符的标记,如数字、空格、连字符和撇号、放弃非字母字符,并将大写字母更改为小写字母。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| whitespace | 空格分析器在遇到空白字符时将文本分解为术语 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] |
| stop | 停止分析器与简单分析器相同,但增加了删除停止字的支持。默认使用的是 english 停止词。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] |
| keyword | 不分词,把整个字段当做一个整体返回 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] |
| pattern | 模式分析器使用正则表达式将文本拆分为术语。正则表达式应该匹配令牌分隔符,而不是令牌本身。正则表达式默认为 w+ (或所有非单词字符)。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| 多种西语系 arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english等等 | 一组旨在分析特定语言文本的分析程序。 |

分词器 _analyze 的使用
#standard
GET _analyze
{"analyzer": "standard","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#simpe
GET _analyze
{"analyzer": "simple","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}GET _analyze
{"analyzer": "stop","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#stop
GET _analyze
{"analyzer": "whitespace","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#keyword
GET _analyze
{"analyzer": "keyword","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}GET _analyze
{"analyzer": "pattern","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#english
GET _analyze
{"analyzer": "english","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}POST _analyze
{"analyzer": "icu_analyzer","text": "他说的确实在理”"
}POST _analyze
{"analyzer": "standard","text": "他说的确实在理”"
}POST _analyze
{"analyzer": "icu_analyzer","text": "这个苹果不大好吃"
}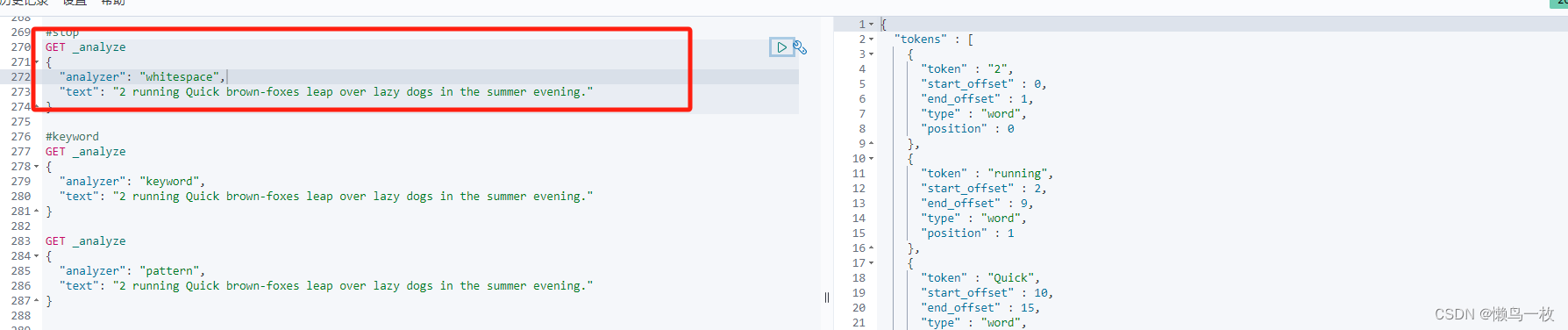
可以看出是按照空格、非字母的方式对输入的文本进行了转换,比如对 Java 做了转小写,对一些停用词也没有去掉,比如 in,其中 token 为分词结果;start_offset 为起始偏移;end_offset 为结束偏移;position 为分词位置。
使用分析器进行分词
课程Demo
#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
#Whitespace Analyzer – 按照空格切分,不转小写
#Keyword Analyzer – 不分词,直接将输入当作输出
#Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
#Language – 提供了30多种常见语言的分词器
#2 running Quick brown-foxes leap over lazy dogs in the summer evening
其他常用分词器
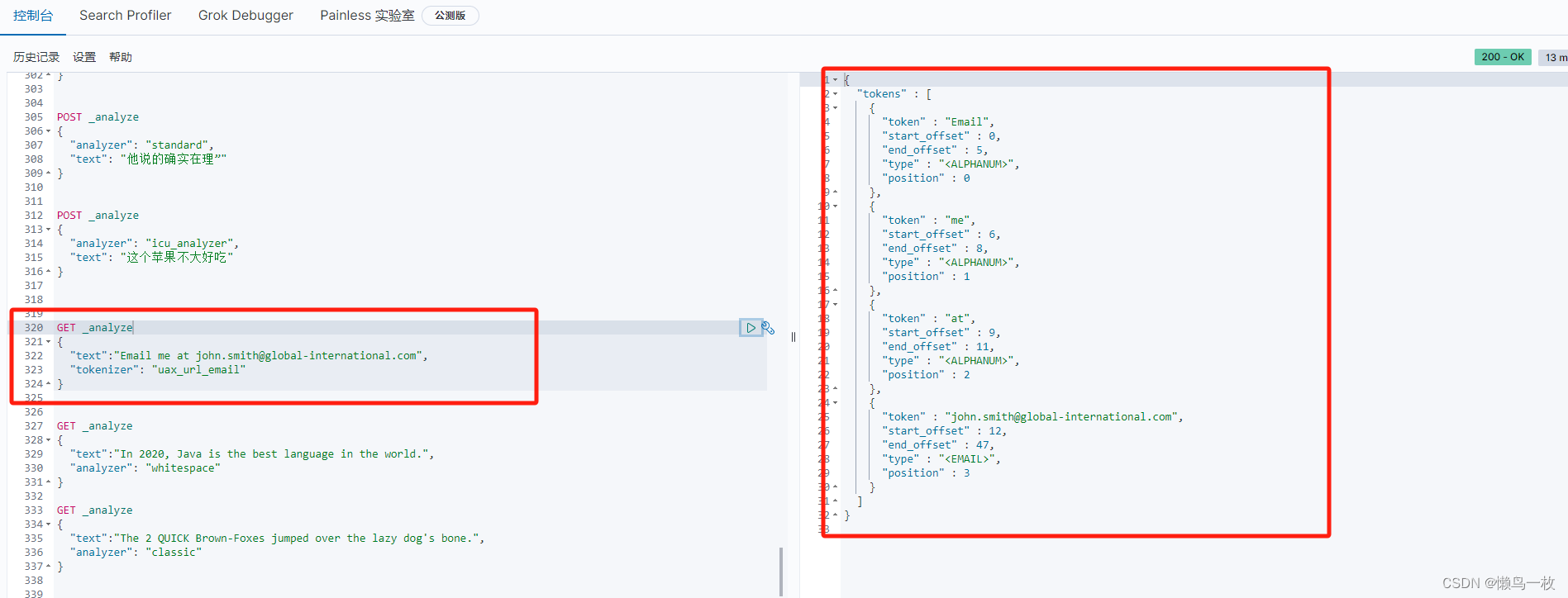
电子邮件分词器(UAX URL Email Tokenizer)
此分词器主要是针对email和url地址进行关键内容的标记。
GET _analyze
{"text":"Email me at john.smith@global-international.com","tokenizer": "uax_url_email"
}
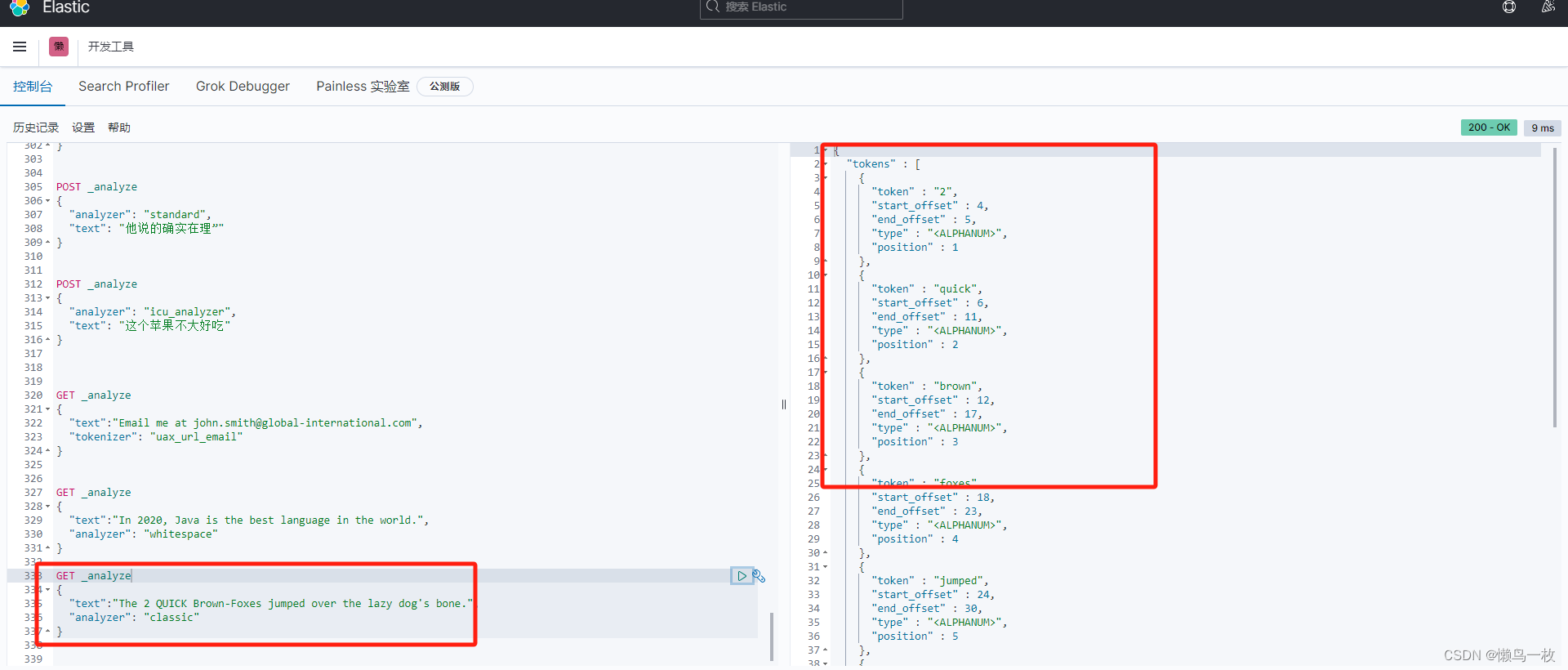
经典分词器(Classic Tokenizer)
可对首字母缩写词,公司名称,电子邮件地址和互联网主机名进行特殊处理,但是,这些规则并不总是有效,并且此关键词生成器不适用于英语以外的大多数其他语言
特点
- 它最多将标点符号拆分为单词,删除标点符号,但是,不带空格的点被认为是查询关键词的一部分
- 此分词器可以将邮件地址和URL地址识别为查询的term(词条)
GET _analyze
{"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.","analyzer": "classic"
}
路径分词器(Path Tokenizer)
可以对文件系统的路径样式的请求进行拆分,返回被拆分各个层级内容。
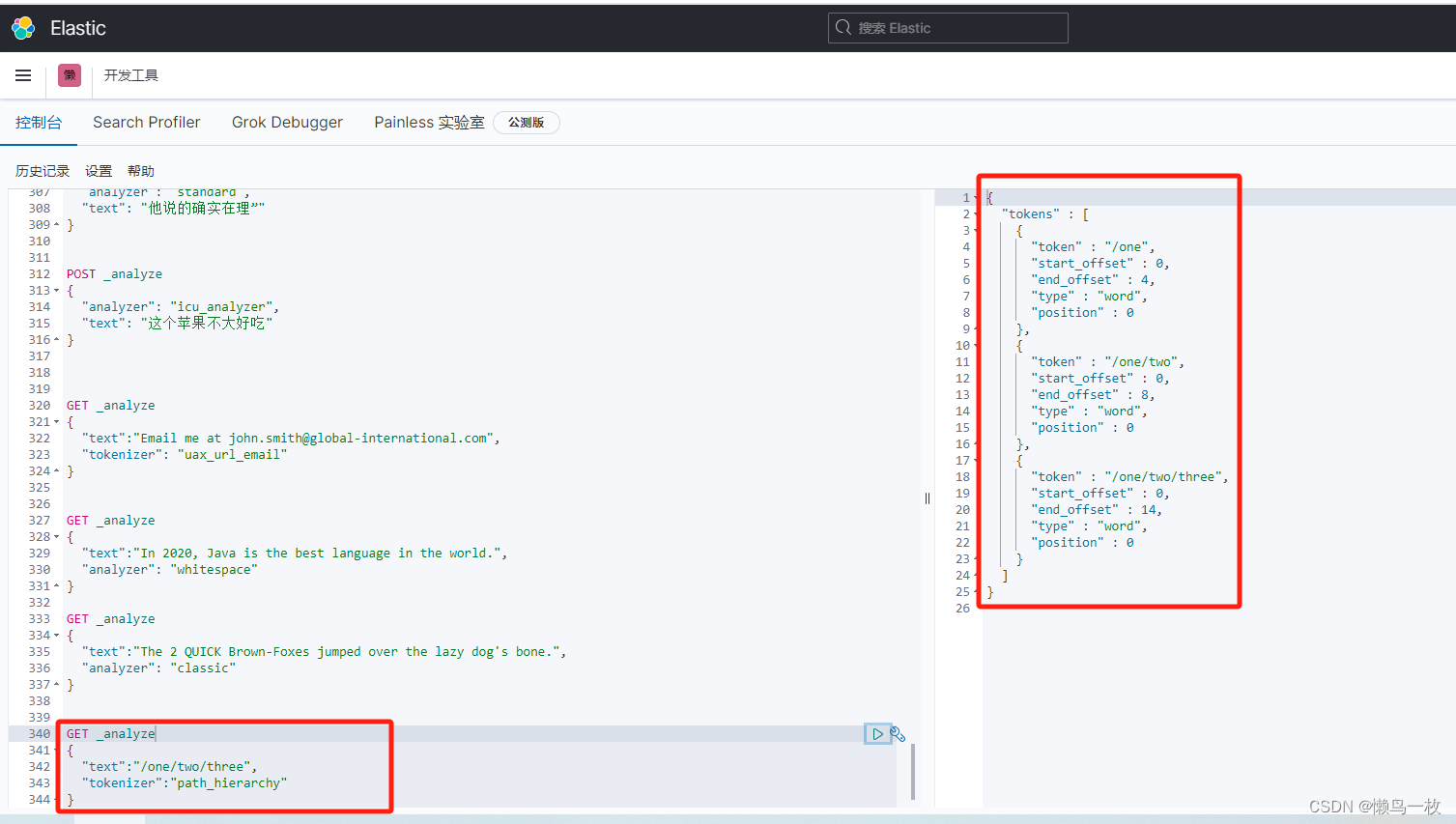
GET _analyze
{"text":"/one/two/three","tokenizer":"path_hierarchy"
}
自定义分词器
当内置的分词器无法满足需求时,可以创建custom类型的分词器。
配置参数
| 参数 | 描述 |
|---|---|
| tokenizer | 内置或定制的tokenizer.(必须) |
| char_filter | 内置或定制的char_filter(非必须) |
| filter | 内置或定制的token filter(非必须) |
| position_increment_gap | 当值为文本数组时,设置改值会在文本的中间插入假空隙。设置该属性,对与后面的查询会有影响。默认该值为100. |
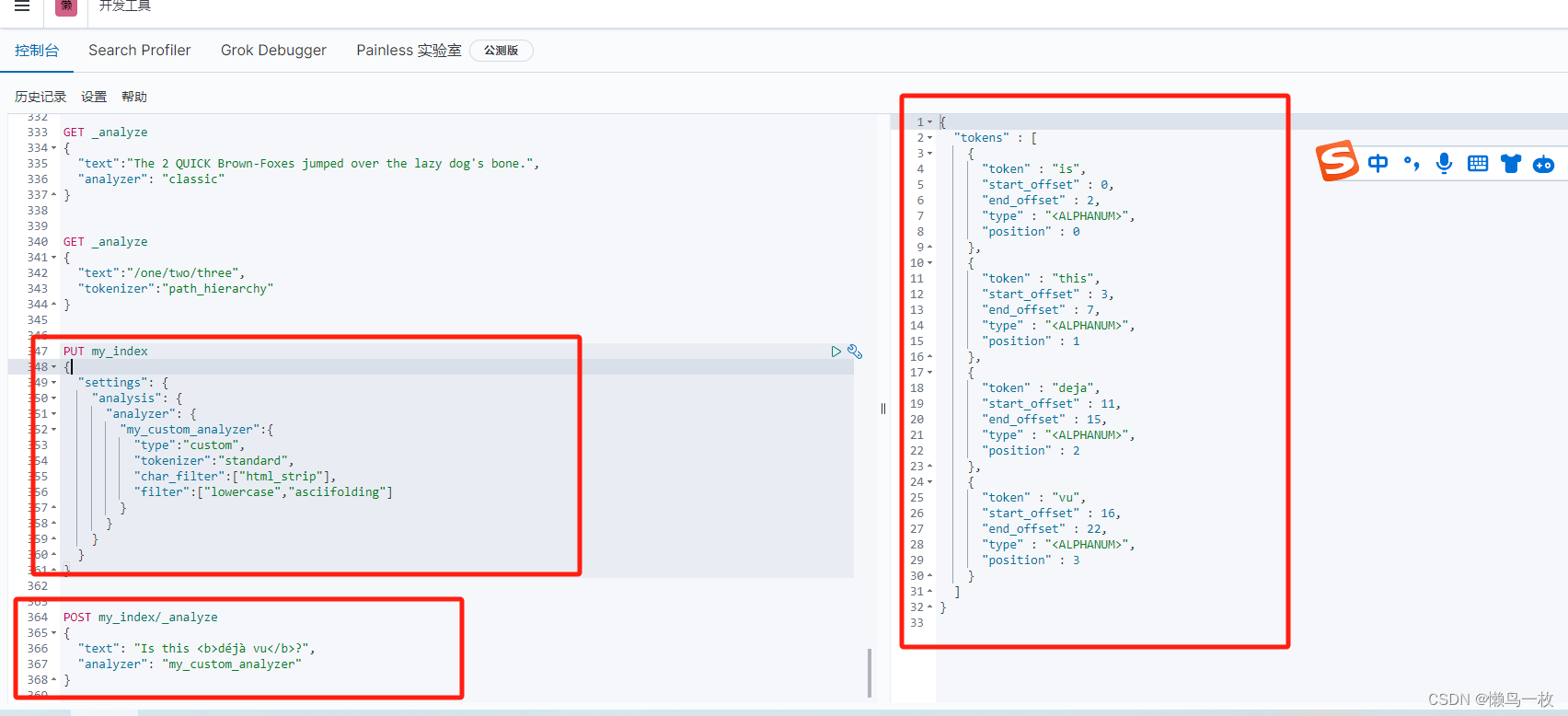
- 创建索引
上面的示例中定义了一个名为my_custom_analyzer的分词器
该分词器的type为custom,tokenizer为standard,char_filter为hmtl_strip,filter定义了两个分别为:lowercase和asciifolding
PUT my_index
{"settings": {"analysis": {"analyzer": {"my_custom_analyzer":{"type":"custom","tokenizer":"standard","char_filter":["html_strip"],"filter":["lowercase","asciifolding"]}}}}
}
- 测试使用自定义分词
POST my_index/_analyze
{"text": "Is this <b>déjà vu</b>?","analyzer": "my_custom_analyzer"
}
中文分词器
IKAnalyzer
IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本,在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
使用IK分词器
IK提供了两个分词算法:
- ik_smart:最少切分。
- ik_max_word:最细粒度划分。
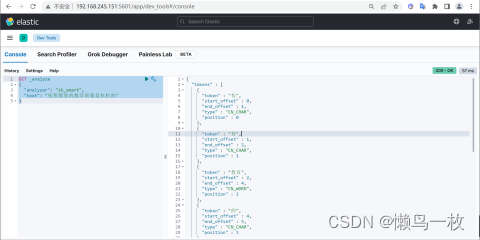
ik_smart 分词算法
使用案例
原始内容
GET _analyze
{"analyzer": "ik_smart","text": "传智教育的教学质量是杠杠的"
}
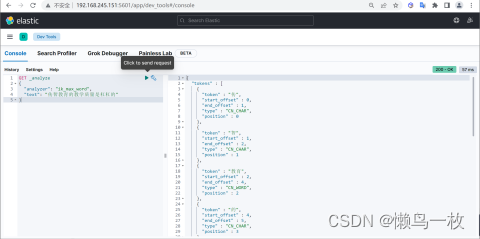
ik_max_word 分词算法
GET _analyze
{"analyzer": "ik_max_word","text": "传智教育的教学质量是杠杠的"
}
自定义词库
我们在使用IK分词器时会发现其实有时候分词的效果也并不是我们所期待的
问题描述
例如我们输入“传智教育的教学质量是杠杠的”,但是分词器会把“传智教育”进行拆开,分为了“传”,“智”,“教育”,但我们希望的是“传智教育”可以不被拆开。
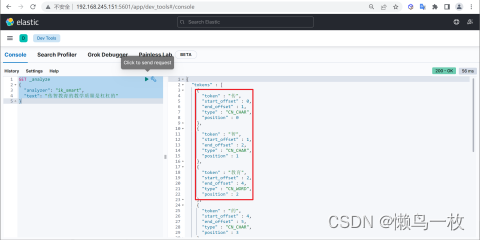
解决方案
对于以上的问题,我们只需要将自己要保留的词,加到我们的分词器的字典中即可
编辑字典内容
进入elasticsearch目录plugins/ik/config中,创建我们自己的字典文件yixin.dic,并添加内容:
cd plugins/ik/config
echo "传智教育" > custom.dic
扩展字典
进入我们的elasticsearch目录 :plugins/ik/config,打开IKAnalyzer.cfg.xml文件,进行如下配置:
vi IKAnalyzer.cfg.xml
#增加如下内容
<entry key="ext_dict">custom.dic</entry>
再次测试
重启ElasticSearch,再次使用kibana测试
GET _analyze
{"analyzer": "ik_max_word","text": "传智教育的教学质量是杠杠的"
}
可以发现,现在我们的词汇”传智教育”就不会被拆开了,达到我们想要的效果了
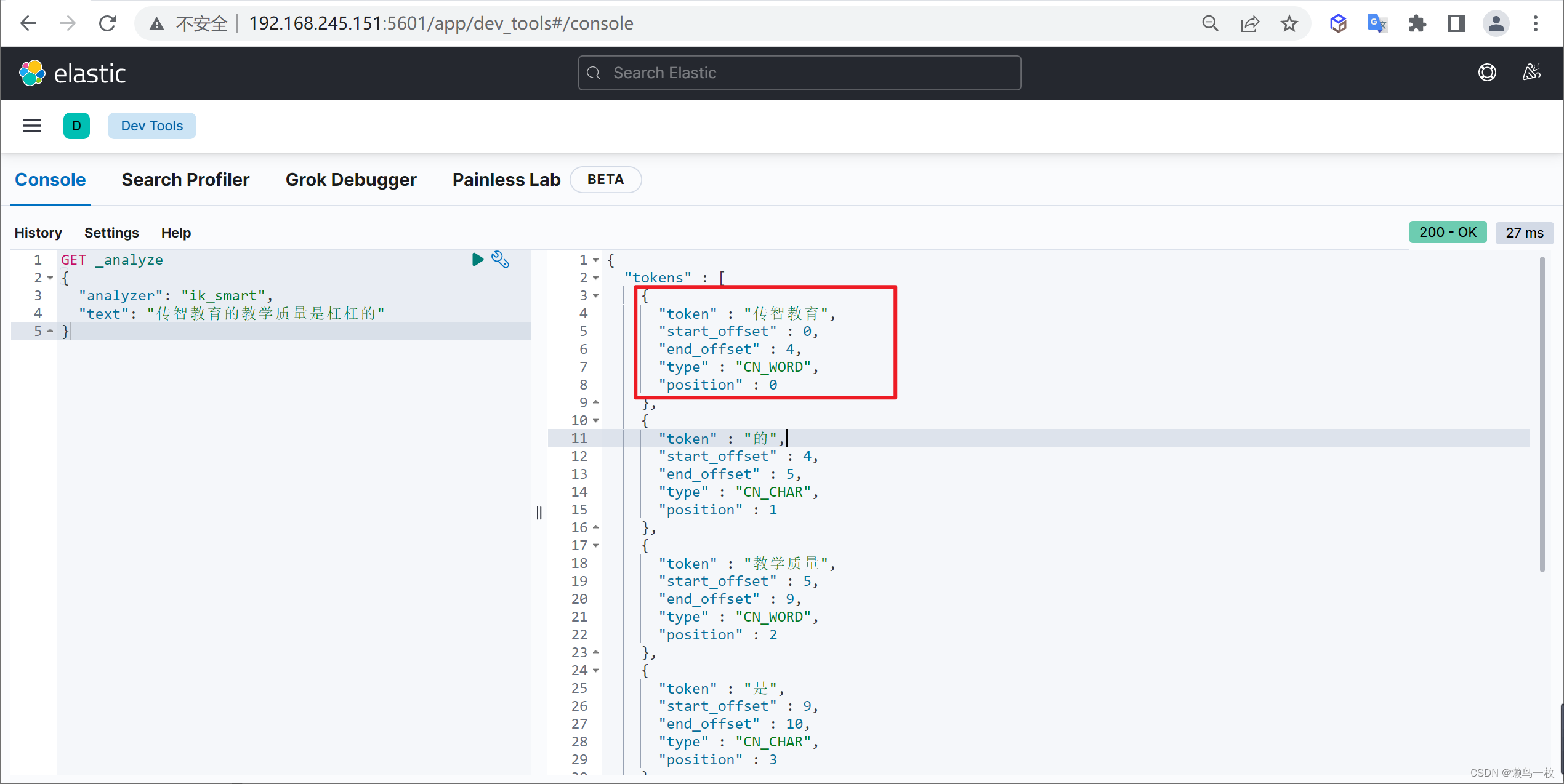
分词的可配置项
standard 分词器可配置项
| 选项 | 描述 |
|---|---|
| max_token_length | 最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255。 |
| stopwords | 预定义的停用词列表,例如english或包含停用词列表的数组。默认为none。 |
| stopwords_path | 包含停用词的文件的路径。 |
COPY{"settings": {"analysis": {"analyzer": {"my_english_analyzer": {"type": "standard","max_token_length": 5,"stopwords": "_english_"}}}}
}
正则分词器(Pattern Tokenizer) 可配置选项
可配置项
正则分词器有以下的选项
| 选项 | 描述 |
|---|
|pattern |正则表达式|
|flags |正则表达式标识|
|lowercase| 是否使用小写词汇|
|stopwords |停止词的列表。|
|stopwords_path |定义停止词文件的路径。|
COPY{"settings": {"analysis": {"analyzer": {"my_email_analyzer": {"type": "pattern","pattern": "\\W|_","lowercase": true}}}}
}
路径分词器(Path Tokenizer)可配置选项
| 选项 | 描述 |
|---|---|
| delimiter | 用作路径分隔符的字符 |
| replacement | 用于定界符的可选替换字符 |
| buffer_size | 单次读取到术语缓冲区中的字符数。默认为1024。术语缓冲区将以该大小增长,直到所有文本都被消耗完为止。建议不要更改此设置。 |
| reverse | 正向还是反向获取关键词 |
| skip | 要忽略的内容 |
COPY{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "path_hierarchy","delimiter": "-","replacement": "/","skip": 2}}}}
}
语言分词(Language Analyzer)
ES 为不同国家语言的输入提供了 Language Analyzer 分词器,在里面可以指定不同的语言





![【C++杂货铺】详解类和对象 [中]](https://img-blog.csdnimg.cn/direct/586292f9eb4847f993964cd177b5bc88.gif)